

人間の指示に従って画像やイラストを数秒で作り出す画像生成AI。
その中でも代表的なものがStable Diffusion(ステーブル・ディフュージョン)です。
Stable Diffusionは、Stability AIが開発した画像生成モデルで、誰でも無料で簡単に画像やイラストが作成可能です。
今回は、Stable Diffusionの仕組みや特徴・利用方法を徹底解説します。
画像作成の質を向上させる方法も合わせて参考にしていただけたら幸いです。
Stable Diffusionの概要
Stable Diffusionは、画像生成AIサービスの一種。
画像生成AIとは、完成形のイメージや雰囲気をテキストで入力するだけで、自動的にAIが画像を生成できるサービスの総称です。
これまで、画像やイラストを作成する能力がない方は、料金を支払って画像をダウンロードしたり、プロのイラストレーター等に作成を依頼する必要がありました。
Stable Diffusionが2022年に登場して以来、専門的な知識がなくても誰でも無料で高度な画像が作成できるため、日本でも多くのユーザーに人気があります。
Stable Diffusionの仕組みとは?
Stable Diffusionは、なぜ画像生成を行う事が可能なのでしょうか?
Stable Diffusionの画像生成の仕組みについて解説します。
画像の学習方法
Stable Diffusionに限らず、画像生成AIは膨大なデータを学習しています。学習方法には、
- 教師あり学習:データを元に学習する
- 教師なし学習:正解を与えず自ら回答を出力する
の2つがあります。教師あり学習では、AIに犬の画像を認識させるため、「犬の画像」と「犬」というテキストラベルを表示させ、紐付ける事で多くの犬の画像を学習し、新しく犬の画像を作成する際にそのデータを基にしているのです。
一方、教師なし学習は、学習済みのデータを基にAIがその特徴を抽出し、類似するような画像を作成する事が可能です。
これにより、データのルールやパターンを学ぶディープラーニングを用いたAIは、膨大な学習データを自ら学習・分析し、オリジナル画像を生成します。
潜在拡散モデル
一般的な画像生成AIは拡散モデルを使用しています。
拡散モデルは、ノイズだけの状態になるまで画像に少しずつノイズを加えた後、その工程からノイズを取り除き、元の画像を再形成するまでの工程をAIに学習させる生成モデルです。
この工程には膨大な処理を行っているため、時間がかかったりする等の難点がありました。
しかし、この膨大な処理を高速化し効率的に学習する「潜在拡散モデル」という生成モデルが登場しました。この「潜在拡散モデル」が搭載されているのがStable Diffusionになります。
Stable Diffusionの特徴
Stable Diffusionが持つ特徴をご紹介します。
Stable Diffusionの特徴1.利用方法は3通りある
Stable Diffusionを利用するには、
- WEB上で利用する方法
- アプリケーションをインストールして利用する方法
- Stable Diffusionをインストールし、ローカル環境で利用する方法
の3通りがあります。Stable Diffusionは、ソースコードがインターネット上で無料公開されているため、Stable Diffusionを基とした様々なアプリケーションなどのサービスが作成されており、スマートフォン等でも利用可能になりました。
Stable Diffusionの特徴2.商用利用可能
Stable Diffusionで生成した画像は、商用利用可能です。
しかし、法律や人権、著作権に触れる疑いのある場合は、商用利用が禁止されています。
Stable Diffusionは、アップロードした画像を元にした画像生成も可能です。
特定の画像を使用する際は、その画像が著作権に触れていないか注意してください。
Stable Diffusionの利用方法
先述したように、Stable Diffusionを利用するには3通りの方法があります。
こちらでは、WEB上やアプリケーションをインストールした際の利用方法をご紹介します。
尚、ご自身のPCにインストールする際の環境等の利用条件も合わせて参考にしていただければ幸いです。
①Stable Diffusionの操作環境を選択する
Stable Diffusionをどういった環境で使用するのか選択します。
WEB上で利用するのかアプリケーションをインストールするのか事前に決めておきましょう。
今回はStable Diffusionのデモ版Hugging Faceを活用し、手順をご説明します。
Hugging Faceは、機械学習モデルのオープンソースコミュニティです。
自由に公開されており、ソフトウェアの開発や情報交換等に用いられています。
>様々なデータセットが提供されている中に、Stable Diffusionのデモ版も含まれているため、どのようなテキストを入力すれば、Stable Diffusionがどのような画像を生成するのか、ご自身の目で実際に確認する事もできるのです。
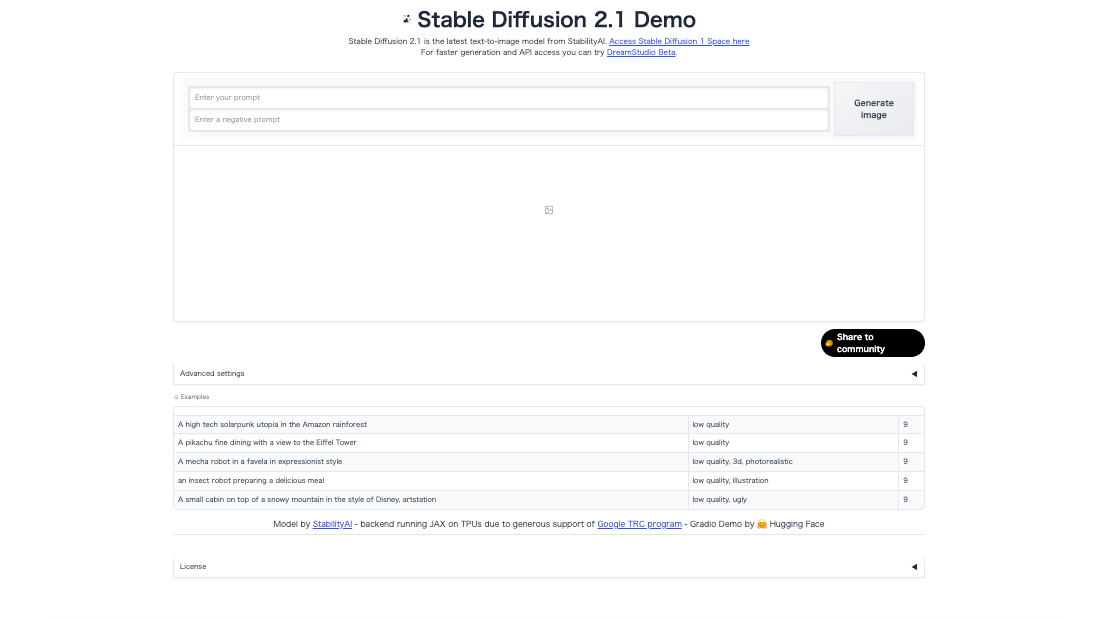
②テキスト(プロンプト)を入力する
テキスト(プロンプト)を入力します。
生成したい画像のイメージをテキスト入力欄に記述して下さい。
また、後述するアプリケーションサービスDream Studioでは、アップロードした画像を元にした画像生成や生成する枚数等の詳細設定、スタイルも変更可能です。
スタイルにより画像の風合いが異なるため、選択したモデルにより仕上がりも異なります。
※Dream Studioは、Hugging Faceの上記のリンクからも飛ぶ事が可能です。
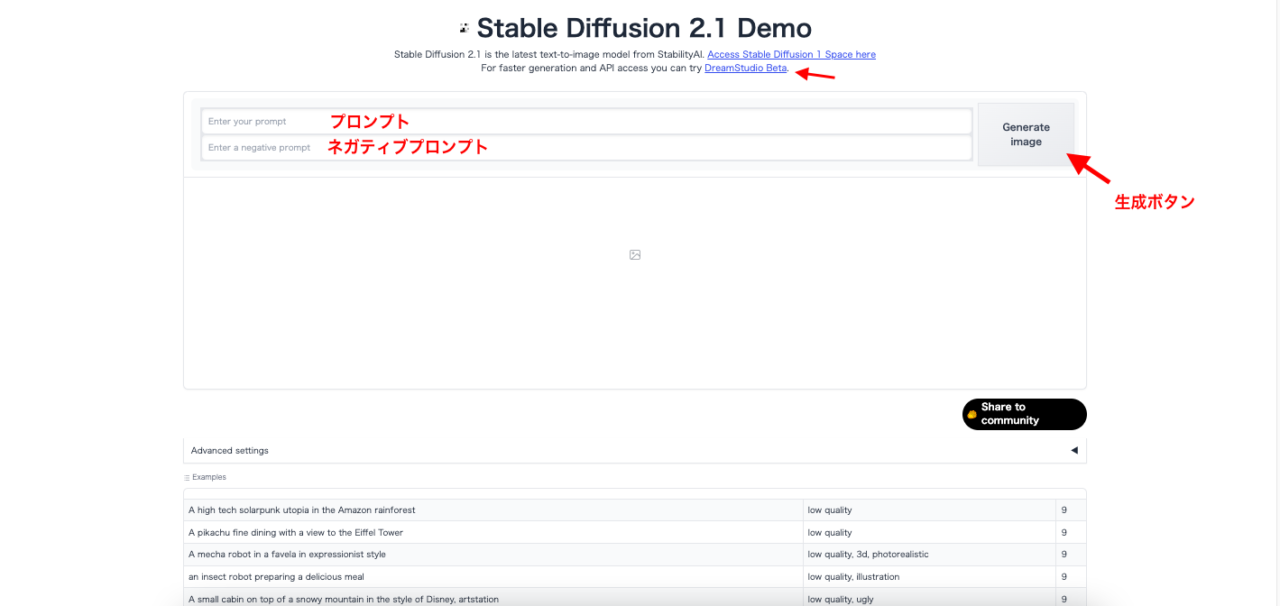
ネガティブプロンプト
プロンプトは2種類あり、通常の指示を記述する欄がプロンプトなのに対し、特定の要素を含めたくない場合に指示を記述する欄がネガティブプロンプトになります。
ネガティブプロンプトは記述しなくても画像生成可能ですが、ネガティブプロンプトを記述する事により、ご自分のイメージに近づける画像を生成できるでしょう。

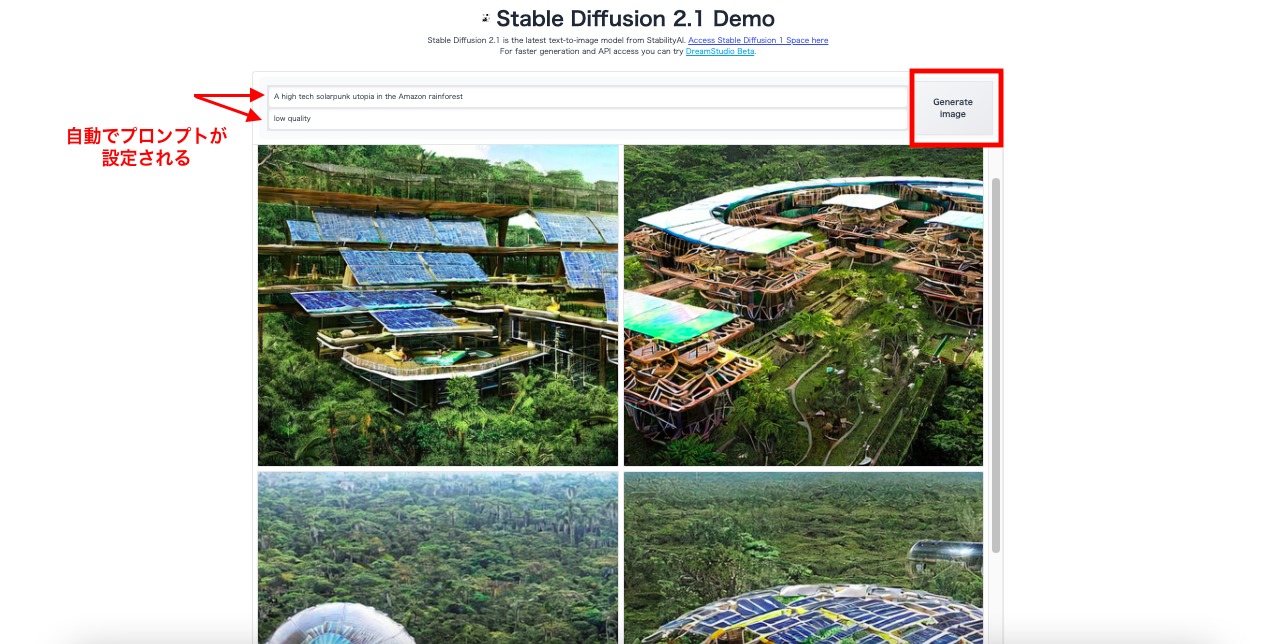
今回は、下記の見本にある「A high tech solarpunk utopia in the Amazon rainforest(熱帯雨林の中のハイテクソーラーパンクの理想郷)」を選択したところ、自動的に「low quality(低品質)」とネガティブプロンプトが設定されました。
③「Generate」ボタンを押す
右にある「Generate」ボタンを押し、画像生成を行います。数秒でAIが生成した画像が表示されました。
ローカル環境での利用条件
Stable Diffusionをローカル環境で利用するには、ゲーミングPCレベルの環境が必要になります。以下が利用条件になります。
- windows10/11 64bit版
- NVIDIAのGPU VRAM 4GB以上(数字が大きいほど処理速度が上がります)
- Python3.10.6のインストール
Stable Diffusionをより早く楽しみたい方に!
先述したStable Diffusionのデモ版は、画像枚数生成等の制限はありませんが、動作がやや遅いと感じます。そこで、同じStable Diffusionを用いたサービスで、より手軽に使用できるDreamStudioといった画像生成サービスをご紹介します。
Dream Studio
Dream Studioは、Hugging Faceと同様にStable Diffusionを手軽に使用できるサービスですが、画像生成速度がHugging Faceより早いため、より早い画像生成を行いたい方にお勧めです。Googleアカウントをお持ちの方は、ログインでDream Studioの画像生成が可能です。
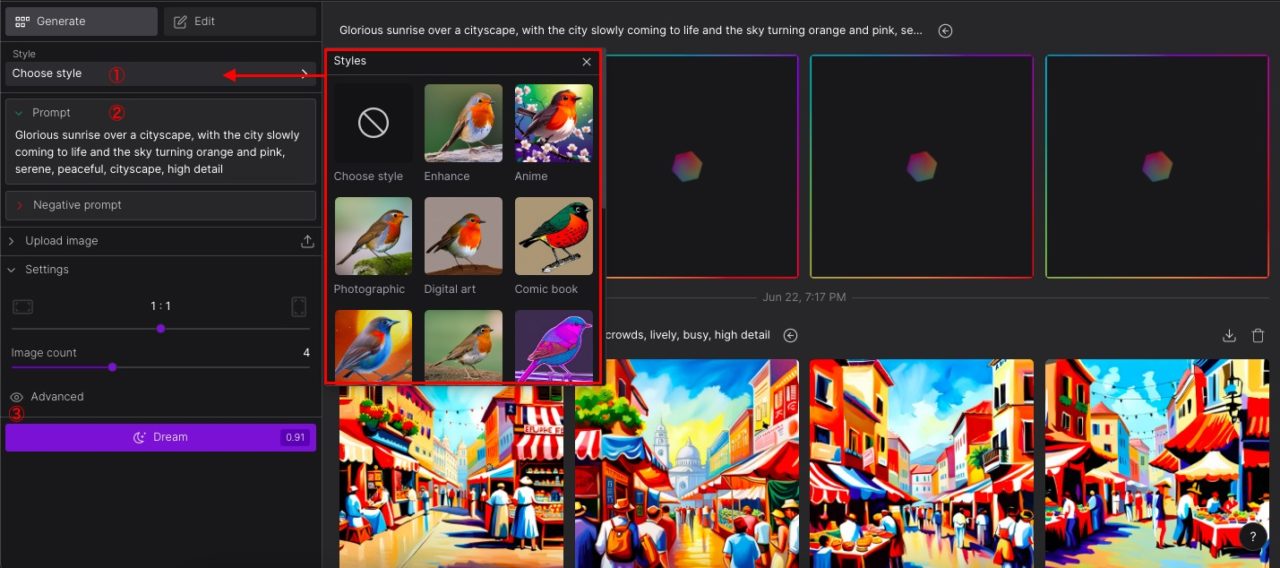
基本的な操作方法は、Hugging Faceと同様ですが、「Style」で画像の風合いを変更したり、「Image count」で1度に生成する画像の枚数も設定できます。
Hugging Faceと異なる点としては、設定の度合いで消費クレジットが生じる仕組みです。
初回に25セント分のクレジットが付与されるため、その範囲内であれば無料で画像生成が可能です。消費目安は設定により左右されますが、目安は25〜30数程の画像生成となります。
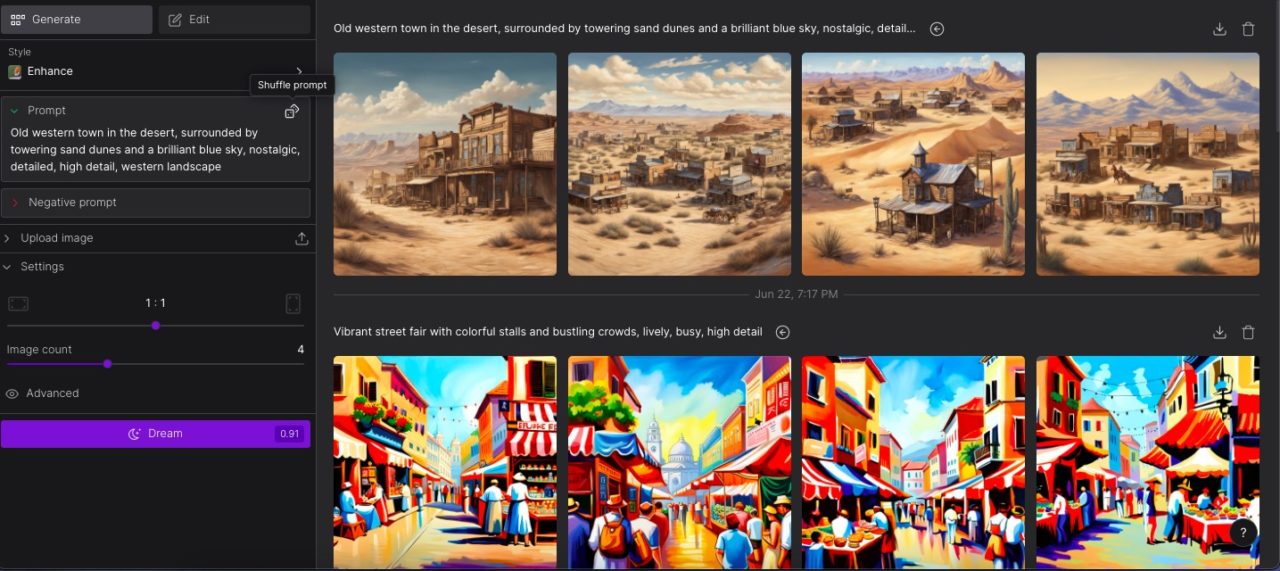
生成ボタン「Dream」の横に消費クレジットが確認できますので確認しましょう。
今回は、見本にある「Old western town in the desert, surrounded by towering sand dunes and a brilliant blue sky, nostalgic, detailed, high detail, western landscape(砂漠にある西部の古い町,高くそびえる砂丘と鮮やかな青い空,ノスタルジック,詳しい,高詳細,西部の風景)」にテキスト入力し、設定枚数は4枚にして出力しました。
無料であるのにも関わらず、質の高い砂漠の風景の画像が生成されました。
Stable Diffusionのテキスト入力の際のポイント
Stable Diffusionで画像生成の精度をより向上させるには、テキスト入力においていくつかのポイントがあります。Stable Diffusionに限らず、画像生成AIを使用する上で知っておくと便利です。
英語でテキスト入力する
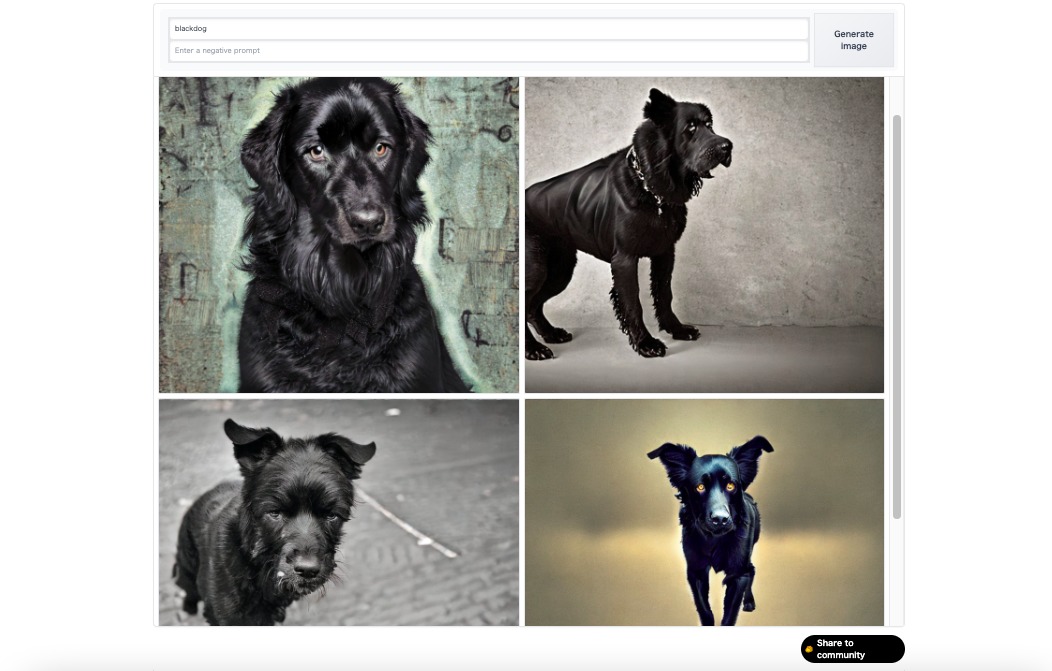
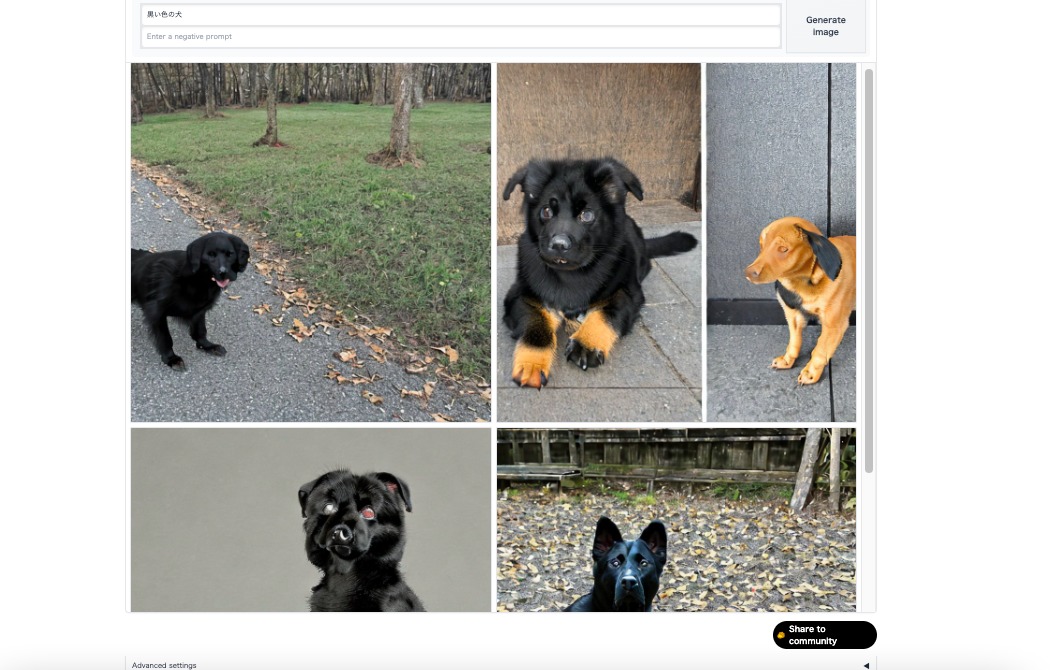
多くの画像生成AIサービスは、日本語でのテキスト入力も理解しますが、理解度は今なお曖昧な部分があります。
例えば、Hugging Faceに日本語で「黒い色の犬」と入力した際と英語で「Blackdog」と入力した際の画像を比較すると仕上がりに大きな差が感じられました。
日本語テキストで入力した画像は、所々が黒い等やや不完全な犬が出力された事に対し、英語でテキスト入力を行うとイメージに近い画像が出力されました。
このことから、日本語ではなく英語でテキスト入力する事を推奨します。
具体的で詳細な指示を出す
テキストの記述にはルールはなく、自由に書くことができますが、どのような画像を生成したいのか具体的なイメージをテキスト入力しましょう。
単語より文章でテキスト入力を行い画像を出力する方がよりレベルの高い画像を出力する傾向にあります。
尚、テキストを記述する際は、優先順位を高くしたい表現から先に記述しましょう。
テキスト記述の順番を入れ替える事で生成画像に変化が生じる場合もあります。
万が一、どのようにテキスト入力を行えば良いのか迷った際は、先述したように見本となるテキストがあらかじめ設定されていますので、お試しください。
Stable Diffusionは誰でも簡単に画像生成できる!
今回は、Stable Diffusionの特徴や使い方を徹底解説しました。
Stable Diffusionは誰でも簡単に画像生成可能な画像生成AIです。
Stable Diffusionを気軽に試してみたい方は、今回ご紹介した「Hugging Face」や「Dream Studio」などのサービスを活用してみてください。
Stable Diffusionを活用する事でオリジナル画像やキャラクター等の作成が可能です。






