今回はボードゲームや自動運転、ロボットの制御などで活用が始まっている最新のAI(人工知能)の一つである、強化学習について解説します。
AIが自らデータを学び、動作を習得していく事ができる最新の技術を感じてみてください。
強化学習とは?
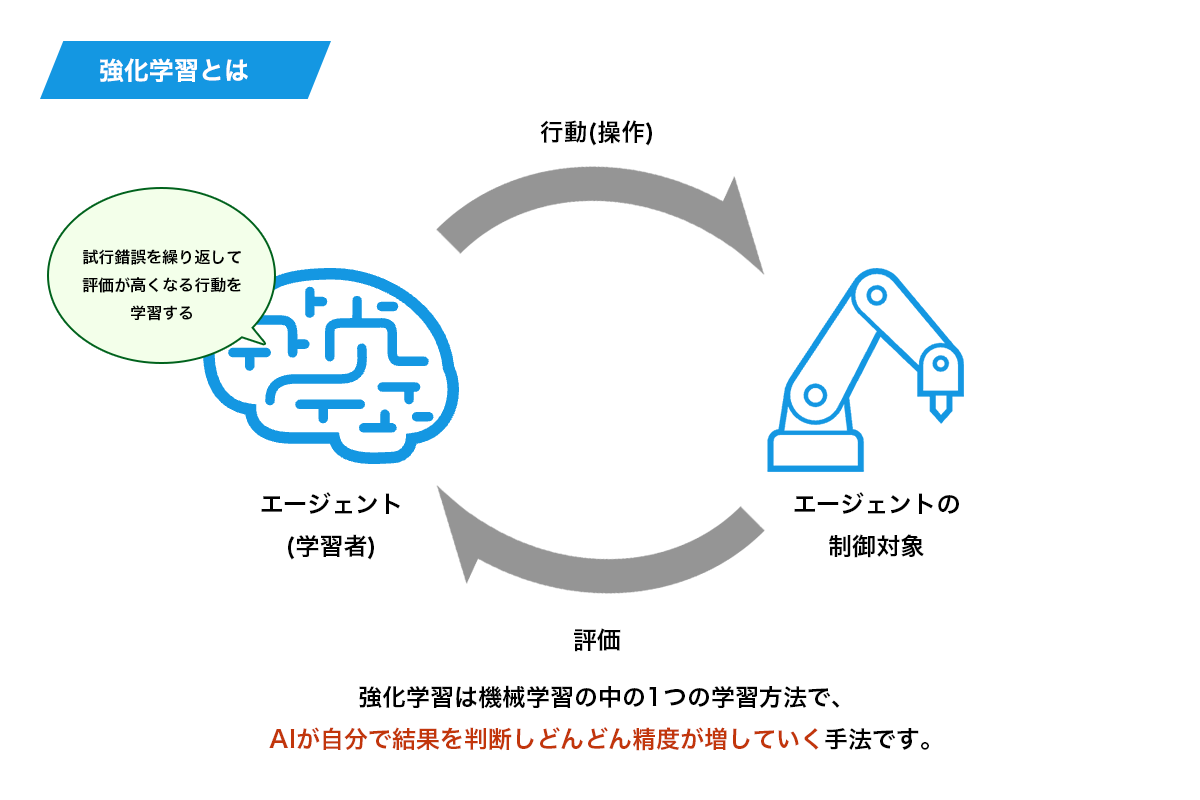
強化学習とは、機械学習と言われるAIの手法の一つです。
通常、AIに行動を教えようとする場合、人が「データ」とそれに対応する「答え」をセットで用意しておき、学習させることが多いですが、強化学習は違います。
強化学習では、点数が最も大きくなることを目的として、どのように行動すれば点数が最も大きくなるかを自ら探し出す学習を行います。
いろいろな行動を試してみて、一番良い行動を探し出す(探索)するという学習をするので、ある意味人間の動作に近くなるイメージです。
強化学習でAIを作成すると、「満点の行動を目指す」ことをしてくれるようになるので、AI自ら行動を改善してくれるようになるのです。
強化学習の事例3選
強化学習と一言で言っても、何ができるのかイメージしづらいかもしれません。
ここでは、強化学習でできることをまとめてみました。
①ゲーム
 2015年にDeepMind社が、Atariという会社が出していたゲームについて、強化学習を使用するAIに学習させ、49本のゲームのうち半数以上で人間に匹敵するか、それを上回るスコアを記録しました。
2015年にDeepMind社が、Atariという会社が出していたゲームについて、強化学習を使用するAIに学習させ、49本のゲームのうち半数以上で人間に匹敵するか、それを上回るスコアを記録しました。
強化学習を勉強する上でも、よく使用される題材です。
こちらも強化学習で作成した場合、どれだけ多く点数を取れるか、どれだけ良い結果を出せるかにAIが努めてくれるようになります。
そのほか、ボードゲームで有名なAlphaGoにはSelf-playという手法が用いられています。
- 強化学習の実装方法が学べる強化学習プログラミング講習はこちら
②自動運転
 自動運転の分野でも、強化学習が使われています。
自動運転の分野でも、強化学習が使われています。
日本の企業であるPrefferd Networks社が研究をしている内容では、車両の幅に対して道路が狭く、車が密集した交差点というような難易度の高い問題に対して強化学習を利用して自動運転を実施しています。
この技術を使うと、周囲を全て同時に集中して見ることができるため、前方向と同じように後方向にも躊躇なく移動します。
下の動画では、学習時には存在しない、人が操作する車からの回避という困難な問題も扱っています。(赤い車は、人間がその場で操作をしています。)
自動運転については下記記事でも詳しく解説しています。
③Googleのロボットアーム
 イメージ参照元:https://gigazine.net/news/20160310-google-deep-learning-robot/
イメージ参照元:https://gigazine.net/news/20160310-google-deep-learning-robot/
Google社は、ロボットアームの動作を最適化する研究を行っています。
どのような場合に、どのような動作をすれば最適なロボットアームの動きになるかを学習していくのですが、Googleは複数の学習を同時並行で進める分散型の自己学習を可能にしています。
この研究では、14台のロボットを使った分散型自己学習を行い、人間よりも速い速度で動作をマスターしています。
強化学習の仕組みとは?

強化学習の概要が理解できたところで、強化学習の仕組みについて徹底解説します。
通常の機械学習では、問題と解答は常に静的に定められており、「これが入れば、これが解答」と決まっているのですが、強化学習では、「これが入っても、状況に応じて対応を変える」ことを学習させることになります。
つまり、強化学習の場合はシステムの出力に応じて周りの環境が変化していくような場合も想定するので、他の機械学習とは少し違う特徴を持っています。
試行錯誤や様々な方策を凝らして、満点の行動を目指すもっとも人間らしい学習手法である強化学習。
その強化学習においては、マルコム決定過程(=MDP Markov decision process)によってアルゴリズムを解析していく方策が一般的です。
マルコフ決定過程とは、「環境」を表す数理モデルのことで、方程式や状態価値関数などの数学的手法で表現されます。
- 状態(state)
- 行動(action)
- 遷移確率(transition probability)
- 報酬(reward)
の4つの構成要素で成り立っています。
もらえる報酬を最大化するような行動はどのようなものかを定式化していく方法といえます。
強化学習が実際に使われているゲーム

Deepracer(ディープレーサー)の正式名称は「AWS DeepRacer」。
1/18スケールのレーシングカーを使い、自律走行のレースゲームを通して強化学習を学ぶことができるAmazonのサービスです。
DeepRacerは車にコースを走らせて、様々な行動を試してゴールにたどり着くための行動を自律的に学習させる強化学習のアプローチをとります。
なので教師あり学習のように多くのデータを必要としません。
DeepRacerにおいては、ゴールに向かって走行する主体であるエージェントは車になります。
環境はコースに該当し、状態(state)はカメラ画像になります。
エージェントがゴールに到達するための行動(action)は、ステアリングをどう切るかや、どのくらいのスピードで走行するかなどです。
報酬(reward)はエージェント(車)がゴールに到達するまでに、いかに正しい道のりを経たかによって大きな報酬がもらえます。
強化学習にとって、良い行動をしたら報酬をもらえるインセンティブを設定する報酬関数という概念が重要となります。
強化学習を楽しみながら学んでいくには、DeepRacerはかなりおススメです。
とはいえ、DeepRacerのコードの実装はPythonを使いますから、強化学習の基礎知識やPythonプログラミングは必須。
書籍などでPythonの知識を身に着けておくと良いでしょう。
Pythonについては以下の記事でも詳しく解説しています。
強化学習に便利なプラットフォーム3選
強化学習をするためのプラットフォームはいくつかありますが、言語としてはPythonができればフレームワークを使うだけで簡単に実装できます。
今回は強化学習で有名なプラットフォームを3つご紹介します。
1.ChainerRL
強化学習で実装されているアルゴリズムが多いです。
初心者でも分かりやすいと言われているChainerと組み合わせて使用できるため、初学者にはオススメです。
Chainerについては下記で詳しくまとめています。
2.RLlib
RLlibは強化学習で実装されているアルゴリズムも多く、学習状況も見やすいです。
RLlibでは、強化学習がどのように実装されているのかを確認するのは、少し難しい部分もあります。
3.Keras-RL
こちらは、強化学習で実装されているアルゴリズムは少なめです。
どのように実装されているかは見やすく、メジャーなKerasと組み合わせて使えます。
強化学習で利用するアルゴリズム5選
強化学習を行う上でのアルゴリズムがいくつかあります。
それらは基本的に、上述したQ学習(Qラーニング)を元にしています。
ここではどのような種類があるかを確認してみましょう。
1.Q学習(Qラーニング)
ある状態の時にとったある行動の価値を、Qテーブルと呼ばれるテーブルで管理し、行動する毎にQ値を更新していく手法です。
学習時にはQテーブルを更新していくことで、学習済みモデルはQテーブルとなります。
単純な仕組みで動作しますが、連続的な「状態」、例えばロボットアームの動きのような滑らかなものを表現しようとすると、Qテーブルが膨大な量となるため、現実的に計算ができなくなるデメリットがあります。
2.DQN(Deep Q Network)
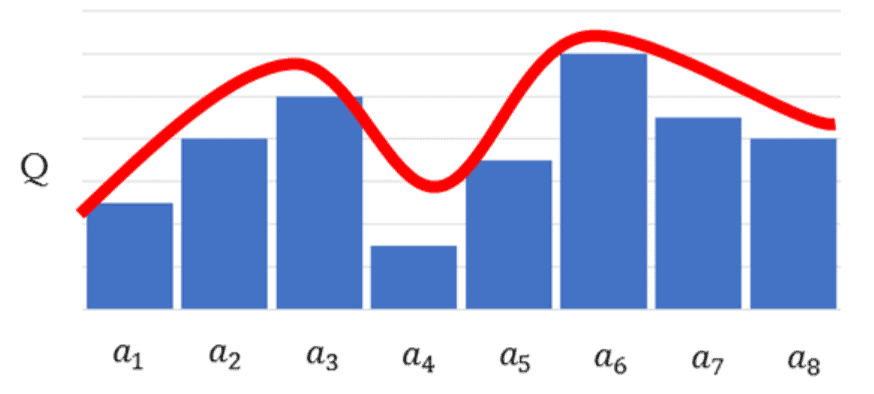
DQNとは、Deep Q Networkの略です。
Q学習ではQ値を学習し、Qテーブルを完成させることに重きが置かれていましたが、DQNではQ学習にニューラルネットワークの考え方を含めています。
最適行動価値関数を、ニューラルネットを使った近似関数で求め、ある状態のときに、行動ごとのQ値を推定できれば、一番いいQ値の行動=取るべき最善の行動が分かるという仕組みです。
更に詳しく知りたい方は下記の記事を参考にしてください。
3.DDQN(Double DQN)
DQNでは、前の状態を過大評価してしまうという問題があったため、最適行動を選択するQ関数とその時のQ値を評価するQ関数の2つを混ぜて学習をさせることで、誤差計算を安定させたモデルです。
4.A3C(Asynchronous Advantage Actor-Critic)
DQNでは、基本的に1つのエージェントが行動して得た経験を学習データとして使って学習します。
1つのエージェントの経験しか利用しないため、学習の進みが遅く、なかなか学習が進まない(時間がかかる)事がありました。
そこで、A3Cでは、エージェントを複数作っておき、それぞれの経験を元に学習させることでオンライン学習ができるようにしています。
エージェントを複数作ることで学習もより早く進むようになっています。
5.Rainbow
DDQNやA3Cを始めとする、DQNをベースにしたアルゴリズムを全部乗せしたアルゴリズムと言われています。
Pythonを使って強化学習を試す記事は、こちらにまとめてありますので見てみてください。
また以下の動画を参考にすると、Pythonで実装しながら強化学習を学べます。
強化学習を導入するメリット
強化学習は行動を学習するため、人間が行えることを代替する分野での活用に期待が持たれています。
しかし、現状ではビジネスシーンで強化学習が完璧に活用されているところは実はほとんどありません。
強化学習では膨大な試行をすることで学習を行いますが、非常に多くの時間や調整・制御が必要になるためです。
ここでは、どのようなことに強化学習が活用できるかをまとめてみました。
ロボットの制御ができる
ロボット制御と書きましたが、ロボットをはじめとする動作の制御で活用できます。
例えば、様々なセンサーを搭載したような産業機械もそうですし、家電などのモーター制御で動作・更新するものも、自ら最適な行動を探し出すという意味では強化学習が活用される部分になっています。
Fintech(フィンテック)で活用できる
Fintechと呼ばれる、金融サービスとITを結びつけた部分での活用も期待されています。
どのように行動すれば最善の行動か、ということを学習することができますので、今後金融業界のAI活用として期待がされています。
AIのミスが少なくなる
学習を強化すると、普段のAIの機械学習がより精密になってAIのミスや間違いが少なくなります。
ですので、強化学習は医療や自動運転など、重要な箇所でのAIに利用することが多いです。
初心者の強化学習の始め方

強化学習は無料のプログラミング言語Pythonと、上述したプラットフォームを使用することで、なんと無料で始められます。
Pythonのフレームワークはオープンソースのものがほとんどです。
プログラミング言語を動作させるPycharmやAnacondaなどの統合開発環境によっては金額がかかる場合もありますが、基本は無料でスタートできると考えて良いでしょう。
実際に無料で強化学習を試そう
最先端で難しそうに感じる強化学習ですが、実際に強化学習を無料で簡単に試すことができるようになっています。
いくつかのステップは必要ですが、是非強化学習を体感してみてください。
強化学習を試すための準備として、以下の環境構築が必要です。
- Pythonのインストール
- Pycharmのインストール
- ChainerとChainerRLのインストール
- OpenAI Gymのインストール
これらをインストールしておけば環境が整うため、強化学習をすぐ始めることが可能になります。
強化学習をより簡単に学ぶには?
強化学習について詳しく説明してきましたが、初心者の方にはなかなか理解しづらい内容ですよね。
そんな時は強化学習を体系的に学ぶことができるセミナーを受講するのがおすすめです。
強化学習の仕組みから実践的なプログラミングまで行うことができ、初歩的なCartPole問題から、実践的なブロック崩しゲームの学習実装までを学ぶことができます。
受講者数1万人を突破したAI研究所が開催している「強化学習プログラミング講習」は、強化学習の基礎知識と仕組みを理解し、実務で使える実装スキルを1日で取得できる人気のセミナーです。
強化学習についてのよくある質問
それでは強化学習についてよくある質問をまとめてみました。
強化学習についてまとめ
今回は強化学習についてとても詳しく解説しましたが、いかがだったでしょうか。
AIは、画像認識によって目を手に入れ、強化学習によって行動を手に入れると言われているくらい、ディープラーニングの活用範囲の中でも最先端で注目をされている技術です。
本格的なビジネス活用はもう少し先かもしれませんが、今からどのような考え方でAIが人間のような行動を手に入れていくのかを理解しておくことは非常に重要かもしれませんね。
ぜひこの機会に強化学習を理解して、機械学習への知識をもう一歩深く知ってみてください。