今回は、強化学習の中でも代表的なアルゴリズムであるDQN(Deep Q-Network)について解説します。
DQNと検索すると、インターネットスラングが最初にヒットします。しかし、今回紹介するDQNは、Deep Q-Networkの略で、AI(人工知能)の最先端研究分野である強化学習のアルゴリズムです。
いきなり「DQNとは」と行きたいところですが、人工知能「DQN」を理解するためには、まずQ学習(Qラーニング)について理解している必要がありますので、そこからご説明していきます。
DQNに必要な「Q学習」とは
Q学習とは、ある状態のときにとったある行動の価値を、Qテーブルと呼ばれるテーブルで管理し、行動する毎にQ値を更新していく手法です。
次は、人工知能「DQN」の概念について解説していきます。
強化学習についてはこちらの記事で詳しく解説しています。
DQNとは?
DQNとは、「Deep Q-Network」の略です。
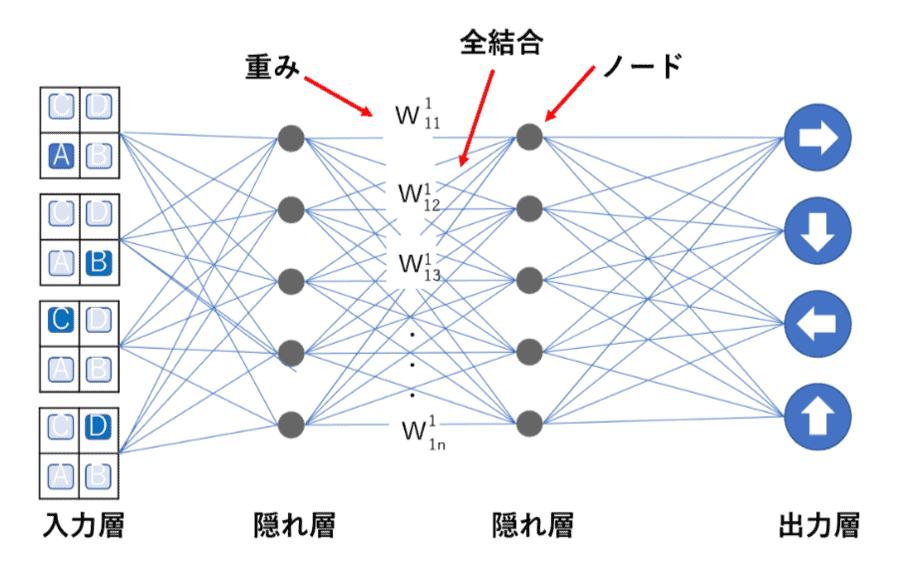
Q学習ではQ値を学習し、Qテーブルを完成させることに重きが置かれていましたが、DQNではQ学習にニューラルネットワークの考え方を含めています。
最適行動価値関数をニューラルネットを使った近似関数で求め、ある状態”_”のときに行動ごとのQ値を推定できれば、一番いいQ値の行動=取るべき最善の行動がわかるという仕組みです。
ある状態”sₜ”を入力し、行動”a”が出力層のノードとなるようなニューラルネットワークを使用して”Q(sₜ,aₜ)”の値を計算します。
こちらが一般的にディープラーニングと呼ばれるものです。
ディープラーニングは、隠れ層が複数の層あるニューラルネットワークによって重みを更新していく学習手法ですので、ディープニューラルネットワークを使用した強化学習のことを深層強化学習と呼んだりもしています。
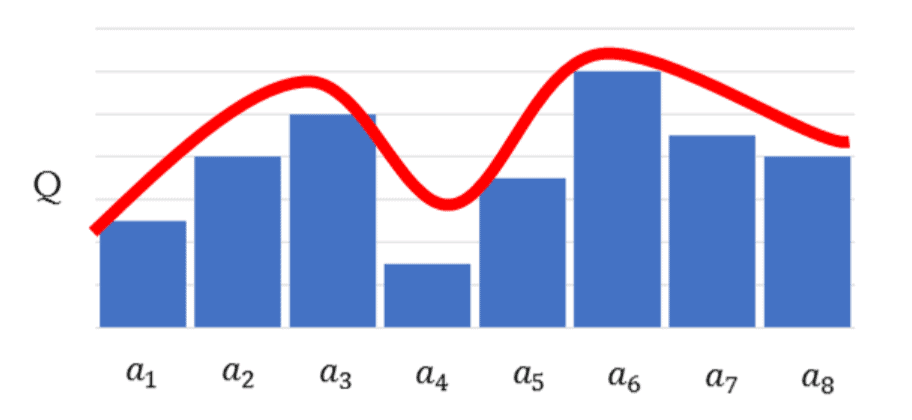
Q学習では、Qテーブルを更新していく仕組みのため、連続的な「状態」、例えばロボットアームの動きのようななめらかなものを表現しようとすると、Qテーブルが膨大な量となるため、現実的に計算ができなくなるデメリットがあります。
それに対し、DQNはQ値そのものを推定するのにニューラルネットワークを使うことで、Q値の近似関数を得てしまおうという考え方ですので、連続的な行動にも対応できるようになっています。
次は、実際にどうやってDQNで強化学習するのかを解説していきます。
ディープラーニングについて体系的に理解し、強化学習のプログラムも組めるセミナーも是非チェックしてみてください。
ネットスラングの「DQN」
DQNと検索して最初に出てくるページや、皆さんが真っ先に思い浮かぶのはネットスラングの方かもしれません。
こちらのDQNは「ヤンキー」や「知識に乏しい人」という意味になり、あまり良い言葉としては使われません。強化学習においてのDQNとは全く違う言語になるので注意した方が良いでしょう。
DQNの学習手順
DQNは以下のような学習手順で学習します。
- Q-networkに状態を入力し、Q(sₜ,aₜ;)を求める
- ε-greedy法に従い、行動をして報酬を求め、sₜ,aₜ,Rₜ,sₜ₊₁,Q(sₜ,aₜ)を保存
- 誤差関数を求め、Q-networkの重みを更新
- 設定した試行ステップごとにTarget-Networkの重みを更新
- ①溜めている過去sₜ,aₜ,Rₜ,sₜ₊₁,Q(sₜ,aₜ)のから任意の個数を取得
- ②そのデータを利用して、設定したミニバッチ数でTarget-networkの重みの学習を行なう
(Experience Replay) - ③求められたTarget-networkの重みをQ-networkと同期
- 更新された重みが適用されたQ-networkで、①から③を繰り返す
まず、Q-networkに状態を入力し、重みの学習をスタートします。
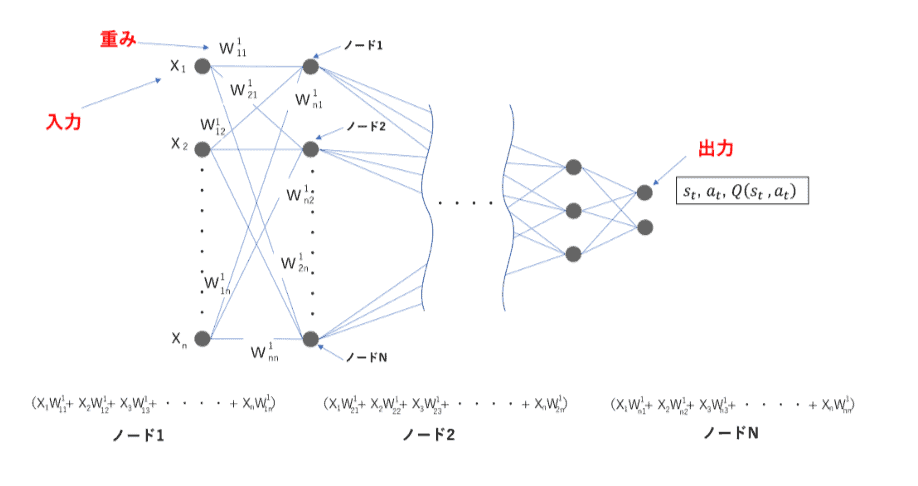
出力された値で実際に行動をしてみます。
行動の基準には、ε-greedy法と呼ばれる手法が使われますが、こちらは後ほどご紹介します。
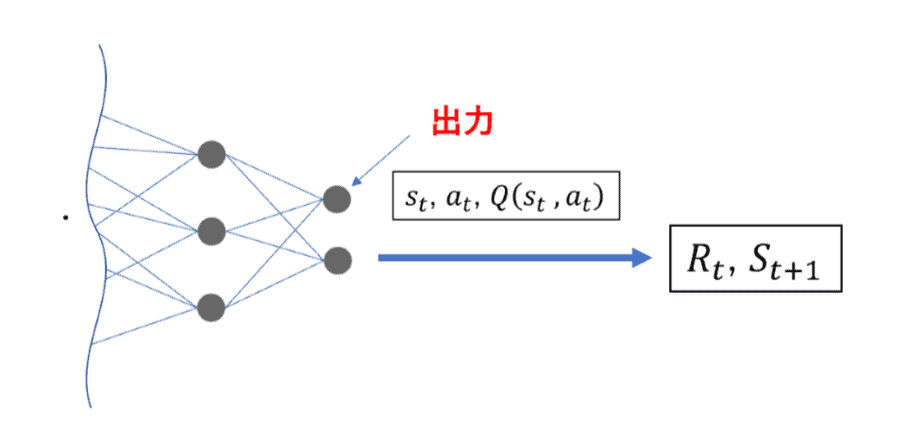
続いて、誤差関数(TD誤差)を用いて誤差を求めます。
R(s,a)+γmaxₐ′Q₀ᵢ₋₁(s′,a′)−Q₀(s,a)が、教師あり学習で言うところの教師ラベル時刻ₜで、状態s₁であった場合に行動a₁を採用したとすると、出力層の値はQ(s₁,a₁)となります。
出力層の値Q(s₁,a₁)が目標値Rₜ₊₁+γmaxQ(sₜ₊₁,a)と近くなればいいことになります。
誤差関数を求め、更新する新しい重みを最適化アルゴリズムにしたがって計算し、新しい重みを適用して学習を進めます。
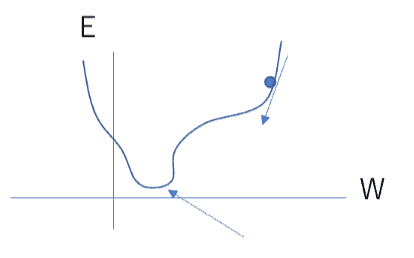
ここまでは通常のニューラルネットワークと同じ仕組みですが、DQNはもう1つのニューラルネットワークを使うことが特徴となっています。
そのもう1つのニューラルネットワークを、Target-Networkと呼んでいます。
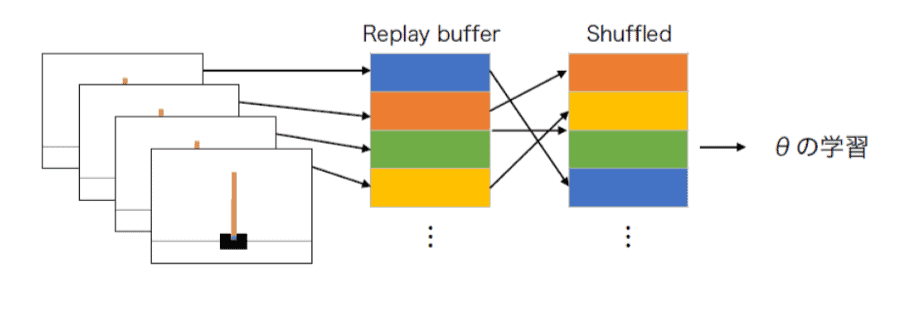
溜めている過去sₜ,aₜ,Rₜ,sₜ₊₁,Q(sₜ,aₜ)のから任意の個数を取得し、そのデータを利用して設定したミニバッチ数で、Target-networkの重みの学習を行ないます。
この手法をExperience Replayと呼びますが、詳細は後述します。
求められたTarget-networkの重みをQ-networkと同期し、Q-networkの学習を続けます。
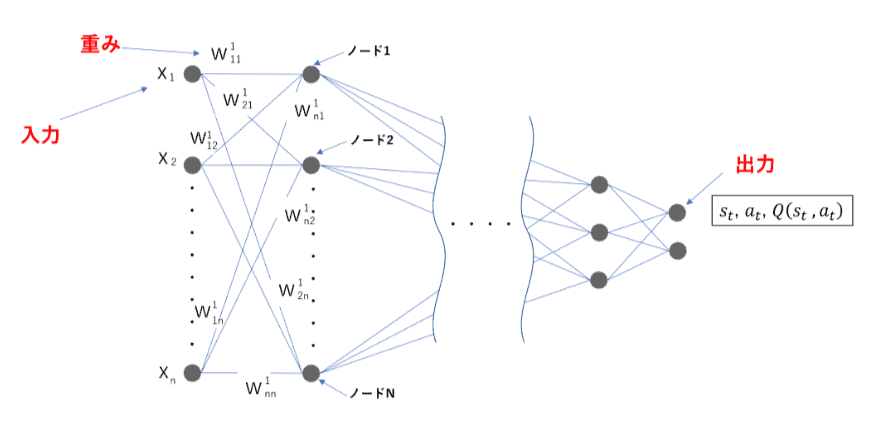
このようにして、Q-networkでの学習を一定行い、それを元にTarget-networkの学習、その結果をさらにQ-networkに適用して学習…ということを続けて行なうのがDQNの特徴です。
学習済みモデルは、このニューラルネットワークの重みが適用されたものになるため、ある状態を入力することでQ値が出力され、最もQ値が高い行動ノードが選択される、という仕組みになっています。
DQNで使う用語2選
DQNの学習手順で紹介した用語をまとめておきましょう。
DQNは様々なアルゴリズムが複雑に絡まり合うため、少し分かりづらいところがあるかもしれませんが、ひとつひとつ確認してみてください。
DQNで使う用語1.ε-greedy法
行動選択の一定数をランダムに選択することで、他にいい行動がないかを探索させる手法です。
強化学習では、最適な行動を見つけ出すために、Q値の高い行動を選択することが求められますが、そうするとデメリットがあります。それは、試行の最初の頃にQ値が高い行動を見つけると、とにかくその行動を取り続けるということです。
一見いいことのようにも見えますが、Q値が高いと言ってもそれまでの行動の中でたまたま高いだけですので、もしかしたら試行していない行動の中に、もっといい行動が存在しているかもしれません。
ε-greedy法は、ある適当な定数を用意(ε=0.3)し、行動選択の際に0~1の間の乱数を生成し、その値がε以下であればランダムに行動を選択するという手法です。
つまり、基本的にはQ値が高い行動を取るけれども、たまには別の行動も試行してみよう、という考え方なのです。
DQNで使う用語2.Experience Replay
従来のQ学習のように、1ステップごとにそのステップの内容(experience)を学習するのではなく、メモリ(replay buffer)に各ステップの内容を保存しておき、メモリから内容をランダムに取り出して(replay)ニューラルネットワークに学習させる方法です。
各ステップごとにそのステップの内容を学習すると、時間的に相関が高い内容(つまり時刻tの学習内容と時刻t+1の学習内容はとても似ている)をニューラルネットワークが学習するので、学習が安定しづらい(過学習が起きやすい)という問題が発生します。
Experience Replayはこの問題を解決する工夫です。
DQNが学べる講座
AI分野で働くことを目指している人に人気になっているのが、DQNや強化学習に関する知識や技術を学べる講座です。色々な講座がある中で、特におすすめのものをいくつか紹介します。
強化学習の学習方法についてはこちらの記事を参考にしてみてください。
AIエンジニア育成講座
実践的に学べるAIエンジニア育成講座は、DQNを学びたい人におすすめの講座です。
受講者数1万人突破、満足度98.8%以上の実績がある人気の講座で、3日間でディープラーニングなどAIエンジニアに必要な知識を学ぶことができます。
会場受講、ライブウェビナー、eラーニング、様々な受講形式に対応しているのが魅力です。会場に行くだけではなく、場所を選ばずにDQNを学ぶことができるので、仕事をしながら知識を学びたいという人にも向いています。
強化学習プログラミングセミナー
強化学習プログラミングセミナーは、AI研究所が提供しているAI技術者を目指す人向けの講座です。受講形式はeラーニングとなっているため、時間や場所を選ばず自分の好きなペースで学習できます。
強化学習の基本的な知識や仕組み、実装に必要なライブラリや設定項目、機械学習用ライブラリの扱い方など、基礎から応用まで学べるカリキュラムが組まれています。
インターネット環境とパソコンさえあれば学習できるので、誰でもすぐ始めることができます。
1日で応用レベルまで完全制覇できることを目指すカリキュラムになっていますが、講座で使われる会場受講と同等内容の動画は、申し込み後1年間いつでも視聴できるので、じっくり学びたい人も安心です。
DQNについてまとめ
今回は、DQN(Deep Q-Network)を使って強化学習する方法を解説いたしました。
DQNを始めとする深層強化学習アルゴリズムは、ディープニューラルネットワークを使用したディープラーニング(深層学習)が元になっているため、ディープラーニングを理解していないと難しくなってしまいます。
ディープラーニングについて体系的に理解し、強化学習のプログラムも組める強化学習プログラミングセミナーも活用しながら、DQNを始めとする深層強化学習アルゴリズムについて、是非学んでみてください。
最後まで読んで頂き、ありがとうございました。