今回は、強化学習用シミュレーションライブラリ「OpenAI Gym」の使い方について徹底解説します!
OpenAI Gymとは?

強化学習用シミュレーションライブラリ「OpenAI Gym」とは、イーロン・マスクらが率いる人工知能(AI)を研究する非営利団体「OpenAI」が提供するプラットフォームです。
CartPole問題やブロック崩しなど、いくつかの環境(ゲーム)が用意されており、強化学習を学ぶことができます。
シミュレーション環境と、強化学習アルゴリズム間のインタフェースを確立されているため、初心者でも強化学習を学びやすくなっています。
「OpenAI Gym」の機能
「OpenAI GYM」はOpenGLを利用した描画ができ、一部3Dでの描画も可能です。
物理演算エンジンは含まれていないため、複雑な物理シミュレーションをする場合には、自分で物理計算のコードを書く必要があります。
より高度なシミュレーションを行うには、ゲームエンジンであるUnityや、物理演算エンジンのOpen Dynamics Engineを使用することもあります。
OpenAI Gymのインストール方法
OpenAI Gymは、プログラミング言語Pythonの環境下で動作させることができます。
そのためPythonのインストールと、それに付随するPycharmなどの統合開発環境のインストールが必要になってきます。
OpenAI Gymは単独でインストールすることもできますが、強化学習ライブラリChainerRLにも含まれています。
強化学習をPythonで行なうには、ChainerRLのような強化学習ライブラリを使用することが前提となることが多いため、以下の手順でライブラリをインストールするのが一番おすすめです。
後ほど説明するOpenAI gymの実行環境としては、公式にはPython 2.7または3.5のLinuxとOSXとなっています。
Windowsでも今回ご紹介する範囲は対応可能ですので、Pythonのバージョンは3.5に設定してインストールをしてみてください。
まずPycharmをインストールして、Pycharmを起動します。
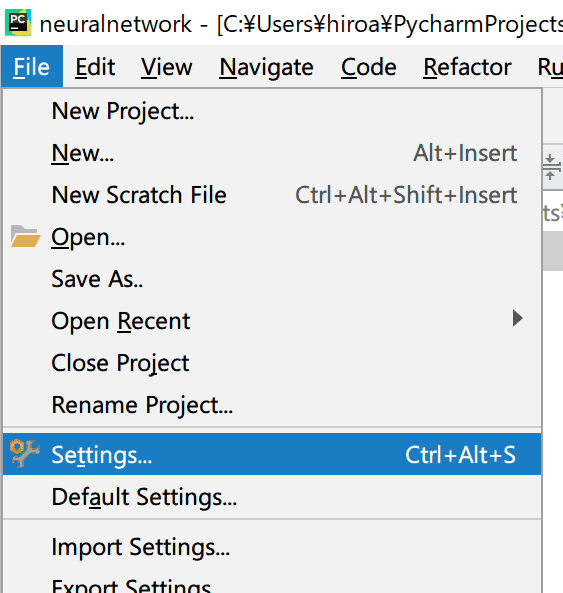
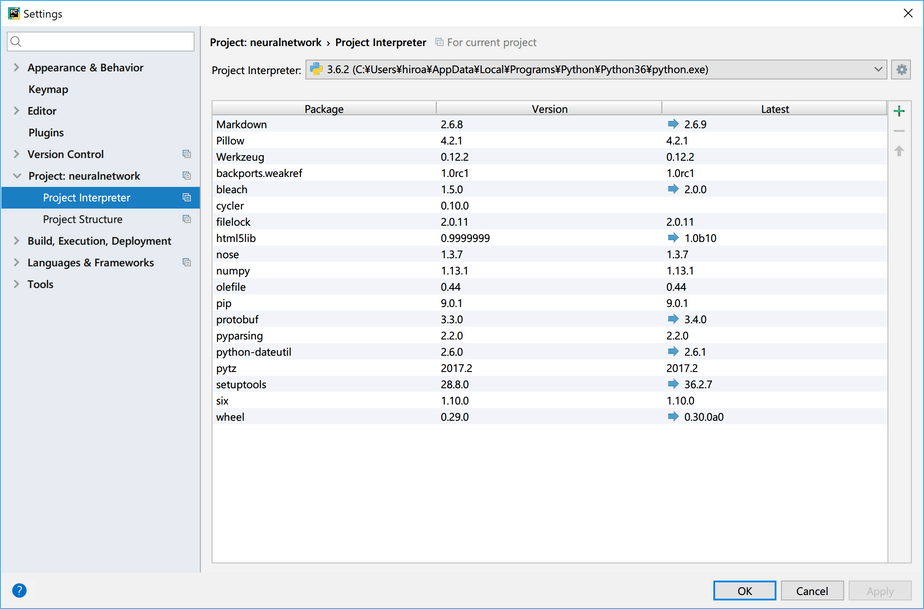
そして[File] – [Settings]で設定画面を開きます。
次に「Project :xxx」>「Project Interpreter」で、「+」マークを選択します。
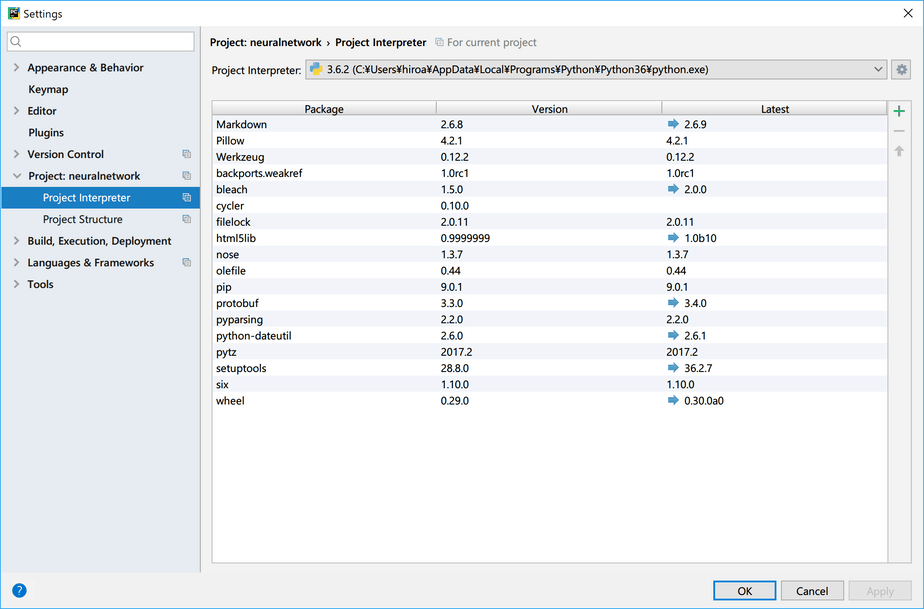
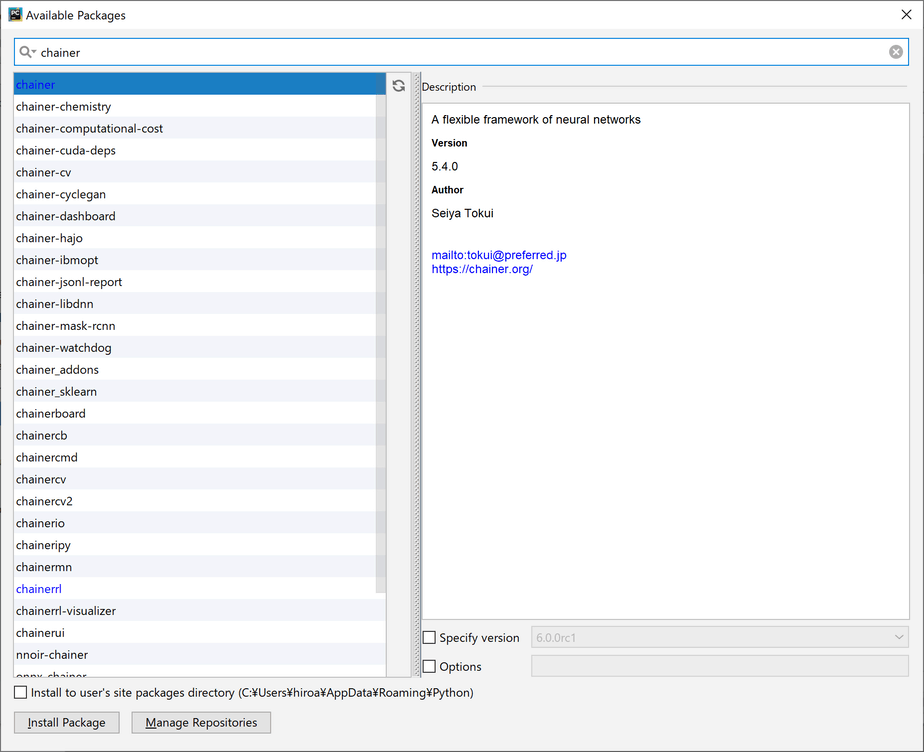
検索ウィンドウで以下のライブラリを検索し、表示されたライブラリを選択します。
- Chainer
- ChainerRL
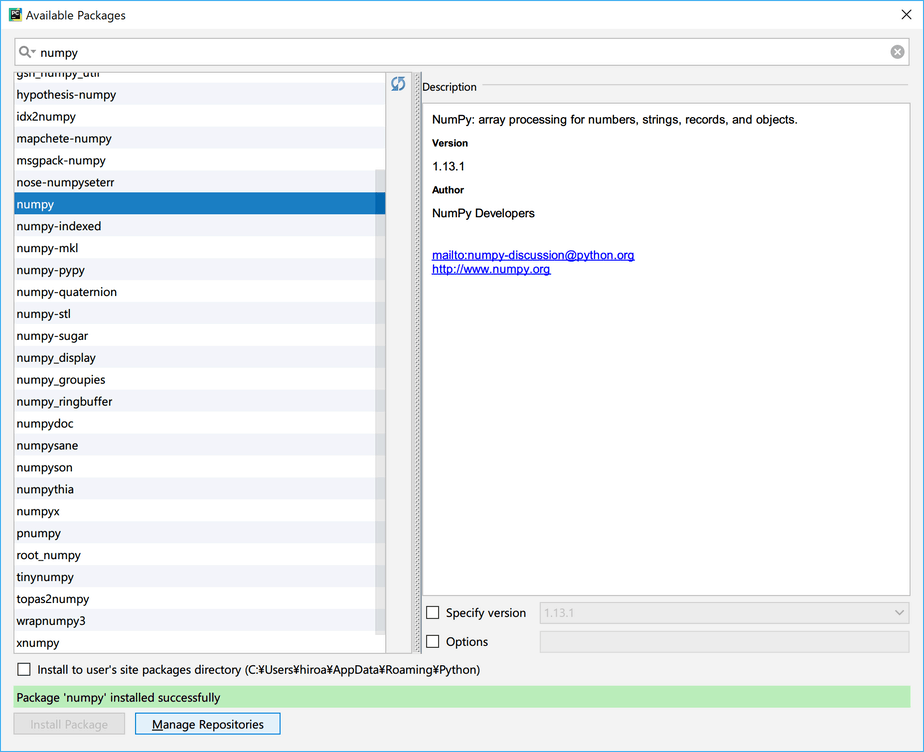
「Package ‘numpy’ installed successfully」が表示されたらインストールの完了です。
右上の「×」ボタンでダイアログを閉じる画面までいきます。
さらに、[OK]を押せばダイアログを閉じるのが完全に完了します。
また、上記手順でうまく動作しない場合などのため、公式サイトで紹介されているインストール手順も確認しておきましょう。
フル機能を使用するためには、OSXやUbuntuの環境が必要です。
Gym機能の最低限をインストールするには、以下のコードを実行します。
pip install gym
まずは、この最低限の機能で色々なことを試すのをおすすめします。
その後、より複雑なことを試したいと思ったら、以下の手順ですべての機能をインストールすることができます。
すべての環境をインストールするには、いくつかのシステムパッケージをインストールする必要があります。
OpenAI Gymのスペックについては下記になります。
brew install cmake boost boost-python sdl2 swig wget
Ubuntu 14.04 (non-mujoco only):
apt-get install libjpeg-dev cmake swig python-pyglet python3-opengl libboost-all-dev \
libsdl2-2.0.0 libsdl2-dev libglu1-mesa libglu1-mesa-dev libgles2-mesa-dev \
freeglut3 xvfb libav-tools
Ubuntu 16.04:
apt-get install -y python-pyglet python3-opengl zlib1g-dev libjpeg-dev patchelf \
cmake swig libboost-all-dev libsdl2-dev libosmesa6-dev xvfb ffmpeg
Ubuntu 18.04:
apt install -y python3-dev zlib1g-dev libjpeg-dev cmake swig python-pyglet python3-opengl libboost-all-dev libsdl2-dev \
libosmesa6-dev patchelf ffmpeg xvfb
OpenAI Gymのシミュレーション環境一覧

OpenAI Gymでは様々な環境が用意されていますが、この中でも一般的なものをいくつかご紹介します。
それぞれの環境の詳細説明はリンクにあるgihubのコードに含まれていますので、是非覗いてみてください。

左右に動くカートの上に乗った棒を落とさないように、バランスを取るシミュレーション環境です。
カートを左右にうまく動かすことで、棒を倒さないようにすると報酬が得られます。

2つのリンク機構により動作する、単純なロボットアームです。
真ん中のリンク部分が左右の回転をすることにより、振り子の原理でアームを上のバーまで振り上げることができたら報酬が得られます。
- Mountain Car

2つの山の間にいる車が、前後に勢いをつけ、坂を登ろうとします。
車が右の山の頂上にあるゴールまで到達できたら、報酬が得られます。

4つの足を持ったアリの3Dモデルが、いかに早く前に進むことができるかをシミュレーションできる環境です。
3D環境は、MuJoCoと呼ばれる物理演算エンジンを使用しているため、フルインストールが必要なのと、こちらは有償での提供となります。
OpenAI Gymで強化学習を行なっている活用事例
それでは、実際にOpenAI Gymを使って強化学習をしたプログラムを見てみましょう。
今回紹介するのは「CartPole問題」という、強化学習を行う上で一番始めによく試される問題です。
まずはOpenAI gymのGithubより、CartPole問題の詳細を確認します。

摩擦のないトラックに沿って動くカートにポールが取り付けられており、カートは横向きに+1または-1の力が加えられるようになっていて制御できます。
振り子が倒れないように左右の力を与え、維持できるようにすることが目的です。
ポールが直立したままで、維持できたタイムステップごとに+1の報酬が与えられます。
エピソードは、ポールが垂直から15度を超えるときに終了するか、またはカートが中心から2.4ユニット以上移動すると終了します。

強化学習の状態設定
状態の設定は、このようになっています。
| 番号 | 状態 | 最小値 | 最大値 |
|---|---|---|---|
| 0 | カートの位置 | -4.8 | 4.8 |
| 1 | カートの速度 | -Inf | Inf |
| 2 | ポールの角度 | -24° | 24° |
| 3 | ポールの速度 | -Inf | Inf |
強化学習の行動設定
行動設定は、下記のようになっています。
| 番号 | 行動 |
|---|---|
| 0 | 左にカートを押す |
| 1 | 右にカートを押す |
強化学習の報酬設定
この問題では「ポールが倒れなければ、1タイムステップごとに1の報酬が得られる」と言う行動を、報酬として設定しています。
エピソードの終了条件
今回は、この3つの終了条件が設定されています。
- ポール角が±12°以上になること
- カートの位置が±2.4を超える(カートの中央がディスプレイの端に達する)
- エピソードの長さが200以上になった場合
こちらのどれかを達成するとエピソードが終了となります。
CartPole問題を自分で実装する手順
それでは、このCartPole問題を実際にPythonのプログラムを書くことで実装してみます。
まずは学習は全くせず、常にカートを右に移動(行動)させるというプログラムを書いてみます。
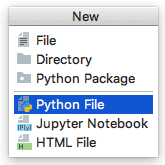
最初に[File]-[New]で新しくファイルを作成します。
![最初に[File]-[New]で新しくファイルを作成](https://ai-kenkyujo.com/wp-content/uploads/2019/05/14014.png)
ダイアログボックスから「Python File」を選びます。
「Name」に「cartpole_practice.py」と入力し、[OK]をクリックします。
![「Name」に「cartpole_practice.py」と入力し[OK]をクリック](https://ai-kenkyujo.com/wp-content/uploads/2019/05/14016.png)
そして、ライブラリをインポートします。
import gym
CartPoleのインスタンスを作成し、状態を初期化します。
#CarPoleの読み取りセット
env = gym.make("CarPole-v0")
observation = env.reset()
AIの行動を実際に起こしてみて、行動が行われた後の状態を確認します。
今回は、「ずっと右に動かし続ける動作」をさせてみます。
#実行
for i in range(50):
action = 1 #右に押す
observation, reward, done, info = env.step(action) #情報を取得
print("observation = " + str(observation))
print("reward = " + str(reward))
ビジュアライズします。
env.render() #ビジュアライズ
ビジュアライズを終了します。
#終了env.close()[Run]-[Run]で「cartpole_practice.py」を選択し、先ほど書いたソースコードを実行します。
そうすると以下のようなアニメーションが表示され、指定した行動を起こしてくれます。

すると、以下のような結果が表示されます。
observation = [ 0.02977195 0.15301161
-
0.04499931
-
0.2864956 ]reward =
1.0
observation = [ 0.03283218 0.34874546
-
0.05072922
-
0.5930245 ]reward = 1.0
observation = [ 0.03980709 0.54453946
-
0.06258971
-
0.90124568]reward = 1.0
observation = [ 0.05069788 0.74045105
-
0.08061463
-
1.212927 ]reward = 1.0
これで、実際にAIを強化学習で行動させることに成功しました。
強化学習が学べるセミナー
AI開発に使用する機械学習の一種である強化学習は、セミナーに参加するのが効率的です。 ただ、どのセミナーに参加すれば良いのか、迷ってしまう人もいるでしょう。 そこで、おすすめの強化学習セミナーを紹介します。
AI研究所の強化学習プログラミング講習
強化学習のセミナーとしておすすめなのは、AI研究所の「強化学習プログラミング講習」です。 AIのニューラルネットワークと、プログラミング言語Pythonに関する知識を持っている人が、強化学習を学ぶことを想定しているセミナーです。 強化学習について、基礎から学習を進めていきます。そして、最終的にはロボットアームの操作やシミュレーションなど、実践的な内容も含まれています。 そのため、強化学習に関して詳しくない人が、短期間で実践的なスキルを身に付けることも不可能ではありません。
AI研究所の強化学習プログラミングセミナーは、eラーニング形式です。実際のセミナーの内容を録画した動画を視聴しながら、学習を進めていきます。 そのため、スケジュール調整をする必要がなく、自分のペースを保てるのがメリットです。また、視聴を開始してから1年間は、動画を何度でも見直すことができます。 よって、わからない部分を改めて視聴したり、何度も視聴して理解を深めたりといった利用も可能です。 日常生活が忙しくて、リアルタイムのセミナーは受けづらい、周囲のペースに合わせて学ぶのは辛いという人におすすめです。
OpenAI Gymについてまとめ
今回は、OpenAI Gymでの強化学習方法について解説しましたがいかがだったでしょうか。
OpenAIは、インストールするだけで様々なシミュレーション環境を用意でき、楽しく強化学習を学ぶことができることが分かっていただけたかと思います。
是非さまざまな環境でも試してみてください。