Python大好きなAI研究所のショウと申します。
前回の記事:ビッグデータを自動で集める?!ウェブスクレイピングをする方法~前編
では、学習データを集める手法の一つ、「スクレイピング」についてご紹介しました。
今回は実装編です。
テーマ
今回は、[架空の不動産ポータルサイト(なぜ架空かは、ご想像にお任せします。)から東京23区の、港区、千代田区、中央区の最新賃貸物件情報を集める。]ということをやってみましょう。
架空ですが、実際のモデルが存在します。
ここでのSeleniumを使ったスクレイピングの方法は他のサイトにも応用できるので、ご安心を。
そして、組み立て方は以下になります。
- どのサイトから、どんな情報をとってくるか考える。
- SeleniumからChromeブラウザを動かせるようにする。
- WebDriverElementを取得し、そのエレメントに対する動作を命令していく。
- 情報を取得していき、其の三と交互に繰り返す。
- 一通り、部分ごとに動かせていることを確認したら、全体を1から動かす。
- 例外が発生した箇所などを修正していく。
全体のソースコード
まずコード全体を示します。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Selectimport chromedriver_binaryimport time
import dillimport pandas as pddef set_pickle(df,filename):
with open(filename,’wb’) as f:
dill.dump(df,f)def make_df(data_set):
chiyoda_dict=[v for d in data_set for k,v in d.items() if k==”千代田区”]chuo_dict=[v for d in data_set for k,v in d.items() if k==”中央区”]minato_dict=[v for d in data_set for k,v in d.items() if k==”港区”]columns=list(minato_dict[0].keys())chiyoda_df=pd.DataFrame(chiyoda_dict,columns=columns)
set_pickle(chiyoda_df,”chiyoda_df.pkl”)
chuo_df=pd.DataFrame(chuo_dict,columns=columns)
set_pickle(chuo_df,”chuo_df.pkl”)
minato_df=pd.DataFrame(minato_dict,columns=columns)
set_pickle(minato_df,”minato_df.pkl”)def set_web_driver():
chromedriver_binary.add_chromedriver_to_path()
options=ChromeOptions()
# 下をコメントアウトすると、ヘッドレスモードで検証できます。
# options.add_argument(‘–headless’)
options.add_argument(‘–incognito’)
driver=Chrome(options=options)
# pref=13 は prefecture 13番目の東京を表している。
# ward=13101|13102|13103 は 13=東京 101=千代田区、あと2つ、102=中央区、103=港区を表している。
base_url=’https://www.dummyrealestatesite.com/search/rent/home/area.html?pref=13&ward=13101|13102|13103′
driver.get(base_url)
return driverdef main(driver):
try:
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,’//div[@id=”ListDataArea”]’)))
except:
time.sleep(1)# セレクトタグを取得
table_box_left=driver.find_element_by_xpath(‘//div[@class=”TableBox Right”]’)#set select display Count number to 10.
display_count=table_box_left.find_element_by_xpath(‘.//select[@class=”DisplayedViewCount”]’)
display_count_select=Select(display_count)
display_count_select.select_by_value(’10’)# ページの更新が終わるまで待機
try:
WebDriverWait(driver,10).until(EC.invisibility_of_element_located((By.XPATH,’//div[@class=”BlockUI BlockMessage BlockElement”]’)))
except:
time.sleep(1)page_count=int(table_box_left.text.split(‘件中’)[0])# すべてのページ数を計算
all_next_page_numbers=int(page_count/10)
# 実際にデータを取得していく処理
data_set=[]for next_page in range(all_next_page_numbers):
time.sleep(3)
list_area=driver.find_element_by_xpath(‘//div[@id=”ListViewArea”]’)
data_list=list_area.find_elements_by_xpath(‘//table[@class=”DataList”]’)
try:
next_btn=driver.find_element_by_xpath(‘//li[@class=”NextPage”]/a’)
except:
next_btn=False
for dl in data_list:
trs=dl.find_elements_by_tag_name(‘tr’)
#物件の主要な情報
id_num=trs[0].find_element_by_xpath(‘./td[1]/input’).get_attribute(‘value’)
to_link=trs[0].find_element_by_xpath(‘./td[2]/h3/a’).get_attribute(‘href’)
room_name=trs[0].find_element_by_xpath(‘./td[2]/h3/a’).text
new_dict={‘物件名’:room_name,’個別ナンバー’:id_num,’リンク先’:to_link}
#交通の情報
transport_col=trs[1].find_element_by_xpath(‘./th[@class=”transportInfo”]’).text.split(‘\n’)
transport_row=trs[1].find_element_by_xpath(‘./td[@class=”transportInfo”]’).text.split(‘\n’)
transport_info=dict(map(list,zip(transport_col,transport_row)))
new_dict.update(transport_info)
#移動時間等の情報
walking_col=trs[1].find_element_by_xpath(‘./th[@class=”walkingInfo”]’).text.split(‘\n’)
walking_row=trs[1].find_element_by_xpath(‘./td[@class=”walkingInfo”]’).text.split(‘\n’)
walking_info=dict(map(list,zip(walking_col,walking_row)))
new_dict.update(walking_info)
#家賃などの情報
price_col=trs[2].find_element_by_xpath(‘./th[@class=”priceInfo”]’).text.split(‘\n’)
price_row=trs[2].find_element_by_xpath(‘./td[@class=”priceInfo”]’).text.split(‘\n’)
price_info=dict(map(list,zip(price_col,price_row)))
new_dict.update(price_info)
#初期費用などの情報
extprice_col=trs[2].find_element_by_xpath(‘./th[@class=”extpriceInfo”]’).text.split(‘\n’)
extprice_row=trs[2].find_element_by_xpath(‘./td[@class=”extpriceInfo”]’).text.split(‘\n’)
extprice_info=dict(map(list,zip(extprice_col,extprice_row)))
new_dict.update(extprice_info)
#その他部屋の情報
room_col=trs[3].find_element_by_xpath(‘./th[@class=”roomInfo”]’).text.split(‘\n’)
room_row=trs[3].find_element_by_xpath(‘./td[@class=”roomInfo”]’).text.split(‘\n’)
room_info=dict(map(list,zip(room_col,room_row)))
new_dict.update(room_info)
remarks_col=trs[3].find_element_by_xpath(‘./th[@class=”remarksInfomation”]’).text.split(‘\n’)
remarks_row=trs[3].find_element_by_xpath(‘./td[@class=”remarksInfomaiton”]’).text.split(‘\n’)
remarks_info=dict(map(list,zip(remarks_col,remarks_row)))
new_dict.update(remarks_info)
if ‘港区’ in transport_row[1]:
ward_name=’港区’
elif ‘中央区’ in transport_row[1]:
ward_name=’中央区’
elif ‘千代田区’ in transport_row[1]:
ward_name=’千代田区’
else:
ward_name=’東京都’
new_dict={ward_name:new_dict}
data_set.append(new_dict)
if next_btn:
driver.execute_script(“arguments[0].click();”,next_btn)
try:
WebDriverWait(driver,10).until(EC.invisibility_of_element_located((By.XPATH,’//div[@id=”SpinnerViewWindow”]’)))
except:
time.sleep(1)
make_df(data_set)
driver.quit()
if __name__==’__main__’:
main(set_web_driver())
ソースコードの説明
部分ごとにコードの説明をしていきます。
1. 必要なライブラリをインポートしていく
from selenium.webdriver import Chrome,ChromeOptions
# 2. WebDriverWaitのインポート
from selenium.webdriver.support.ui import WebDriverWait
# 3. expected_conditionsを別名ECでインポート
from selenium.webdriver.support import expected_conditions as EC
# 4. Byのインポート
from selenium.webdriver.common.by import By
# 5. Selectのインポート
from selenium.webdriver.support.ui import Select
# 6. chromedriver_binaryのインポート
import chromedriver_binary
# 7. timeのインポート
import time
# 8. dillのインポート
import dill
# 9. pandasを別名pdでインポート
import pandas as pd
各ライブラリごとの説明
1. ChromeとChromeOptionsのインポート
Chromeクラスは、クロームブラウザを操作する、Driverオブジェクトを作るために必要です。
ChromeOptionsでオプションを指定します。
例えば、incognitoを指定すると、プライベートモードで動かせたり、headlessを指定するとヘッドレスモード(ブラウザは立ち上がらないが、裏で動いている) でブラウザを起動できます。
2. WebDriverWaitのインポート
WebDriverWaitは待機時間の設定をするために必要です。
3. expected_conditionsを別名ECでインポート
expected_conditionsは先に呼び出したWebDriverWaitと連携させ、HTML要素がどんな状態の時に実行処理を待つのかを細かく指定できます。
4. Byのインポート
ByはECに渡す引数(タプルで渡す)にXPATHを使うのか、CSSセレクターを使うのかを指定するために使います。
5. Selectのインポート
Selectはselectタブを扱えるようにしてくれるものです。
Seleniumでは通常の使い方をするとselectタブを認識してくれないので、このライブラリをインポートしなければなりません。
6. chromedriver_binaryのインポート
chromedriver_binaryは、クロームウェブブラウザを立ち上げるのに必要です
7. timeのインポート
timeにはWebDriverWaitで対応しきれない時間調整を行ってもらいます。
8. dillのインポート
dillはPickleファイルを簡単に取り扱うためのモジュールで、pip install dillで取得できます。
9. pandasを別名pdでインポート
最終的にデータを可視化したり、調査したりする際に便利なので、pandasを別名pdでインポートします。
別名(alias)を使いインポートするのは、単純に名前が長いより、短いほうが書きやすいからです。
データを保存するための関数を用意する
Pickle形式で保存する関数
with open(filename,’wb’) as f:
dill.dump(df,f)
set_pickle関数の引数に、DataFrameにしたスクレイピングの結果と保存するファイルの名前を渡します。
それをwith openとdill.dumpを使い、Pythonで直接編集できるように保存します。
データフレームに変換する関数
# 1.
# 一区域ごとの辞書を作成。
# items()メソッドを使いキーとバリューに分け、内包表記で辞書のリストを作る。
chiyoda_dict=[v for d in data_set for k,v in d.items() if k==”千代田区”]chuo_dict=[v for d in data_set for k,v in d.items() if k==”中央区”]minato_dict=[v for d in data_set for k,v in d.items() if k==”港区”]# 2.
# 列名を辞書のキーからとってくる。
# キーは全ての辞書で一律なので、どの辞書から取ってきてもいい
columns=list(minato_dict[0].keys())# 3.
# データフレームに変換して、Pickleで保存。
# 三区域分繰り返す。
chiyoda_df=pd.DataFrame(chiyoda_dict,columns=columns)
set_pickle(chiyoda_df,”chiyoda_df.pkl”)chuo_df=pd.DataFrame(chuo_dict,columns=columns)
set_pickle(chuo_df,”chuo_df.pkl”)minato_df=pd.DataFrame(minato_dict,columns=columns)
set_pickle(minato_df,”minato_df.pkl”)各ライブラリごとの説明
- DataFrameに直す関数です。引数にスクレイピングしたデータを受け取ります。
- 一区域ごとにDataFrameに直す前の整形作業をしていきます。
- DataFrameメソッドを使い、リストからデータフレームを作っていきます。その際に列名を指定しあげる必要があるので、columns変数に辞書のキーを格納します。データフレームに変換して、set_pickle関数でPickleに保存していきます。
スクレイピングの準備
ブラウザを立ち上げる。
# 1.
# クロームブラウザを立ち上げるのに必要なchromedriver_binaryを使えるようにする。
chromedriver_binary.add_chromedriver_to_path()# 2.
# ブラウザにして欲しい動作をオプションで指定するためにoptionオブジェクトを作る。
options=ChromeOptions()# 3.
# プライベートモードをオプションで指定する。
options.add_argument(‘–incognito’)# 下をコメントアウトすると、ヘッドレスモードで検証できます。
# options.add_argument(‘–headless’)# 4.
# driverオブジェクトを作ると同時にブラウザを立ち上げる。
driver=Chrome(options=options)# 5.
# スクレイピングするサイトのURLを指定する。
# URLのパラメーターに渡す値pref=13は
# prefecture 13番目の東京を表している。
# ward=13101|13102|13103 は 13=東京 101=千代田区、あと2つ、102=中央区、103=港区を表している。
base_url=’https://www.dummyrealestatesite.com/search/rent/home/area.html?pref=13&ward=13101%7C13102%7C13103’# 6.
# URLへアクセスする。
driver.get(base_url)# 7.
# 最後にDriverオブジェクト返す。
return driver
- chromedriver_binaryをChromeに渡すパスに設定します。
- ChromeOptionsから、optionsオブジェクトを作成。options.add_argument()で、ブラウザに対するオプションが設定できます。
- プライベートモードでブラウザが立ち上がるように、オプションで指定する。
- Driverオブジェクトを作成すると、ブラウザが立ち上がります。
- スクレイピングの対象となるURLを事前に設定しておく。(実際にブラウザを操作して、物件検索結果のURLをコピペする。)パラメーターのpref=13は東京都を指し、wardは区域を指している。
- getメソッドを使い、指定したURLへアクセスする。
- 最後にDriverオブジェクトを関数の外へ返してあげる。
スクレイピングのmainとなる関数
ページが正常に表示されているかを確認する
try:
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,’//div[@id=”listViewArea”]’)))
except:
time.sleep(1)
mainとなる関数を用意して、引数にdriverオブジェクトを渡し、Try Except文を使い待機時間を指定します。
まず、Tryの中ですが、WebDriverWaitメソッドで何秒間待つかを指定します。
untilメソッドで、引数に渡した条件が達成されるまで、指定した時間で待機させます。
そして、指定条件で出てくる、ECのpresence_of_element_locatedは、XPATHで取得したHTML要素がDOM上に現れるているかを判定します。
10秒たっても要素が確認できない、もしくはそもそも要素が無いなら例外が発生し、Except以下の処理が行われます。
ここではとりあえずtime.sleep()を使い、1秒間待機させて、様子を見ることにします。
セレクトリストを扱えるようにする
# セレクトタグを取得
# find_element_by_xpathを使いselectタグが入っているDIVタグをXPATHで取得する。
table_box_left=driver.find_element_by_xpath(‘//div[@class=”tableListBox Left”]’)# 2.
# 1ページに物件を10件表示する設定を行う
# 1. で取得したDIVタグの要素からXPATHを使いselectタグの要素を取得する。
display_count=table_box_left.find_element_by_xpath(‘.//select[@class=”displayedViewCount”]’)# 3. ここでSelect()を使いselectタグを操作できるようにする。
display_count_select=Select(display_count)# 4. select_by_value()でオプション値を文字列で指定する。
# 今回は表示件数を最小値である10件にする。
display_count_select.select_by_value(’10’)
- find_element_by_xpathを使いセレクトタグが入っているDIVタグの要素を取る。
- DIVタグの要素から再度、find_element_by_xpathを使いセレクトタグを取得する。
- 実際にセレクトタグを扱えるようにする。
- select_by_valueを使いオプション値を文字列で指定する。
表示件数を最小値の10件にしているのは、表示件数がデフォルトの20件より多いと、<ConnectionErrorが頻繁に発生したためです。
環境が違うとConnectionErrorは起こらない可能性があります。
その時はもっと表示件数を増やしてもいいかもしれません。
ページの更新が終わるまで待機させる
# 今回は表示件数を変えたので、
# 表示件数が更新されるまで待機させる。
try:
WebDriverWait(driver,10).until(EC.invisibility_of_element_located((By.XPATH,’//div[@class=”BlockUI BlockMessage BlockElement”]’)))
except:
time.sleep(1)
ページが正常に表示されているかを確認する
で説明したのと全く一緒の方法を使い、ページの更新が終わるのを待機してから処理を進めます。
すべてのページ数を計算する
# 総物件数が表示されています。
# そこから、テキスト情報を抜き出し、
# ‘件中’を使いsplit()で分けて、総物件数を取得します。
# 後で計算ができるようにInt型に直します。
page_count=int(table_box_left.text.split(‘件中’)[0])# すべてのページ数を計算
all_next_page_numbers=int(page_count/10)
ページ送りの目安にするため、総物件数を整数型に直して変数に格納します。
そして、総物件数を表示件数で割り、総ページ数を計算します。
1ページごとに処理を行う
# 実際にデータを取得していく処理
# 1.
# 全ての物件情報を格納するための空のリストを作る。
data_set=[]
# 2.
# Forループで1ページずつ順番に10件分の物件情報を取得していく。
for next_page in range(all_next_page_numbers):
# 3.
# スクレイピングのマナーとして一回のリクエスト毎に約1~3秒くらい間隔を設ける
time.sleep(3)
# 4.
# 物件情報が格納されているDIVタグをXPATHで取得する。
list_area=driver.find_element_by_xpath(‘//div[@id=”listViewArea”]’)
# 5.
# 取得したDIVタグの中にあるtableタグをXPATHを使い取得する
data_list=list_area.find_elements_by_xpath(‘//table[@class=”dataViewList”]’)
# 6.
# 始めに「次へボタン」があるかどうかの判定を行う
try:
next_btn=driver.find_element_by_xpath(‘//li[@class=”nextPage”]/a’)
except:
next_btn=False
- すべてのデータを収納するための、空のリストdata_setを作成する。
- 全てのページ数が格納してある、all_next_page_numbersをFor文で回し、1ページずつ10件分の物件情報を取得していく。
- time.sleep()で1ページごとに3秒間待機。これはスクレイピングの作法でサーバーに負担がかからないようにするため任意で行う。秒数は何秒でもいいが、2、3秒が無難。
- 物件情報が格納されているDIVタグをXPATHで取得する。
- 表示されたページには、物件情報10件分のテーブルタグがあり、その要素をXPATHを使い取得する。
- 物件情報を取得する前に、次のページに移動するためのネクストボタンの要素を取得しておく。ここでもしラストの表示件数のページになると、ネクストボタンが存在しないので、Falseを入れてループを抜ける処理の判定に使えるようにする。
一件ずつ物件情報を取得する
# 10件分の物件情報が格納してあるdata_listから、
# 一件ずつ情報を取り出していく。
for dl in data_list:# 2.
# find_elements_by_tag_nameで複数個のtrタグを取得する。
trs=dl.find_elements_by_tag_name(‘tr’)# 3.# 物件の主要な情報をXPATHとget_attributeを使って取り出していく。
id_num=trs[0].find_element_by_xpath(‘./td[1]/input’).get_attribute(‘value’)
to_link=trs[0].find_element_by_xpath(‘./td[2]/h3/a’).get_attribute(‘href’)
room_name=trs[0].find_element_by_xpath(‘./td[2]/h3/a’).text# ループ内で一時的に利用する変数new_dict作り、
# 同時に物件の主要な情報で初期化する。
new_dict={‘物件名’:room_name,’個別ナンバー’:id_num,’リンク先’:to_link}
#交通の情報
transport_col=trs[1].find_element_by_xpath(‘./th[@class=”transportInfomation”]’).text.split(‘\n’)
transport_row=trs[1].find_element_by_xpath(‘./td[@class=”transportInfomation”]’).text.split(‘\n’)
transport_info=dict(map(list,zip(transport_col,transport_row)))
# 4.
# 辞書のupdateメソッドを使い、
# 物件情報の一塊を順次、
# new_dictに付け足していく。
new_dict.update(transport_info)
#移動時間等の情報
walking_col=trs[1].find_element_by_xpath(‘./th[@class=”walkingInfomation”]’).text.split(‘\n’)
walking_row=trs[1].find_element_by_xpath(‘./td[@class=”walkingInfomation”]’).text.split(‘\n’)
walking_info=dict(map(list,zip(walking_col,walking_row)))
new_dict.update(walking_info)
#家賃などの情報
price_col=trs[2].find_element_by_xpath(‘./th[@class=”priceInfomation”]’).text.split(‘\n’)
price_row=trs[2].find_element_by_xpath(‘./td[@class=”priceInfomation”]’).text.split(‘\n’)
price_info=dict(map(list,zip(price_col,price_row)))
new_dict.update(price_info)
#初期費用などの情報
extprice_col=trs[2].find_element_by_xpath(‘./th[@class=”extpriceInfomation”]’).text.split(‘\n’)
extprice_row=trs[2].find_element_by_xpath(‘./td[@class=”extpriceInfomation”]’).text.split(‘\n’)
extprice_info=dict(map(list,zip(extprice_col,extprice_row)))
new_dict.update(extprice_info)
#その他部屋の情報
room_col=trs[3].find_element_by_xpath(‘./th[@class=”roomInfomation”]’).text.split(‘\n’)
room_row=trs[3].find_element_by_xpath(‘./td[@class=”roomInfomaiton”]’).text.split(‘\n’)
room_info=dict(map(list,zip(room_col,room_row)))
new_dict.update(room_info)
# 備考欄の情報
remarks_col=trs[3].find_element_by_xpath(‘./th[@class=”remarksInfomation”]’).text.split(‘\n’)
remarks_row=trs[3].find_element_by_xpath(‘./td[@class=”remarksInfomation”]’).text.split(‘\n’)
remarks_info=dict(map(list,zip(remarks_col,remarks_row)))
new_dict.update(remarks_info)
- ページ送り処理のループ内で、またループ処理を行い、物件情報を一件ずつ取得していきます。data_listには、ページに表示されている10件分の物件情報が一件ずつ格納してある。
- trタグに格納してあるのは、物件の詳細情報です。(家賃や間取りなどの情報)
- 先程のtrタグから、詳細情報を取り出して行きます。
- 一時的な辞書new_dictを物件の主要な情報で初期化する。
続いて交通情報などを取り出していく。
thタグには詳細情報のタイトルが、tdタグには詳細情報の数値などが格納してあります。
それをテキスト情報(.text)で取ってきて、splitメソッドを使い、改行コード(\n)で分けて、リストにします。
そして、その各リストを辞書にするため、
zipメソッドで1行づつバラし、mapメソッドで一行ずつが対になったリストを順番に作成していきます。
最後にそれをdictメソッドで辞書に変換します。
5.辞書のupdateメソッドを使い、
new_dictに新しい辞書を連結していきます。
そして、同じような作業を繰り返していきます。
一区域ごとに物件情報の辞書を作成していく
# 住所から区域名を調べ、
# 一時的な変数ward_nameに区域名を入れる。
if ‘港区’ in transport_row[1]:
ward_name=’港区’
elif ‘中央区’ in transport_row[1]:
ward_name=’中央区’
elif ‘千代田区’ in transport_row[1]:
ward_name=’千代田区’
else:
ward_name=’東京都’# 2.
# 先程作ったnew_dictをバリュー、
# 区域名が入ったward_nameをキーとする辞書を作り、
# new_dictに上書きする。
new_dict={ward_name:new_dict}# ループの外で作ったdata_setリストに
# appendメソッドを使って、物件情報の辞書を付け足していく。
data_set.append(new_dict)
- 区域ごとに情報を分けたいので、keyを区域名が入ったward_nameに、
- valueをnew_dictにして、一番最初に作ったdata_setリストにappendメソッドを使用し、付け足していく。
次のページに変移する処理
# もし、があるなら、
# 次へボタンをクリックする。
if next_btn:
driver.execute_script(“arguments[0].click();”,next_btn)# 2.
# ページが更新されるまで待つ
try:
WebDriverWait(driver,10).until(EC.invisibility_of_element_located((By.XPATH,’//div[@id=”SpinnerrWindoww”]’)))
except:
time.sleep(1)# 3.
# 物件情報をデータフレームにして保存する
make_df(data_set)
# 4.
# 最後にブラウザを落とす。
driver.quit()
①表示件数10件分のループが終わったら、次のページに映るため、先程のnext_btnを判定する。もし、next_btnがFalseでなかったら、Javascriptを実行するexecute_scriptメソッドでnext_btnをクリックさせる。
②そして更新が終わるまで待機させる。
ちなみに、Seleniumに用意されているClickメソッドでは「クリックできません」というエラーが頻繁に表示され、とても不安定です。
Javascriptから実行させると安定してクリックできます。(たまに失敗しますけど。)
そしてこの部分こそが、
Seleniumを使っていて良かった最大の利点部分。
通常だとhrefからURLを抜き取って、そのURLへアクセスするのですが、ここではURL部分にJavascript:goPage(ページ番号);として、直接Javascriptが動きます。
すると非同期通信が発生し、ページリロードせずとも次のページが再描画されます。
実際、このようなリンクに遭遇した時、リンクをクリックした時のURLを確かめてください。
URLに変化はないはずです。
一番最初にやった、23区のうち3区域の物件情報のページに行くために、URLにパラメーターをつけた方法等が使えません。
この部分を解決するために今回はSeleniumを使用しました。
driver.quit()
③すべての物件の情報が取得できたら、最初に作っておいた、make_df関数を使います。
3区域分のデータフレームを作成し、pickleファイルで保存します。
④最後にブラウザを、quitメソッドを使用して停止させます。
以上です。
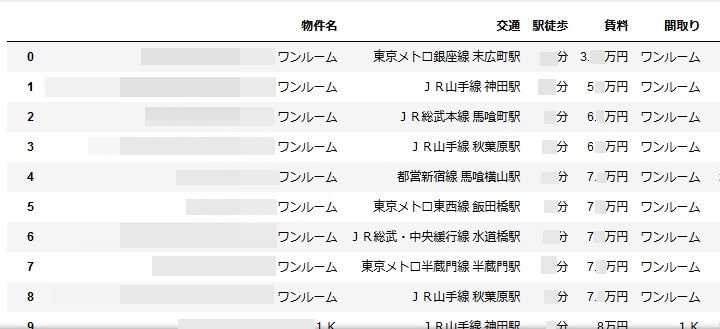
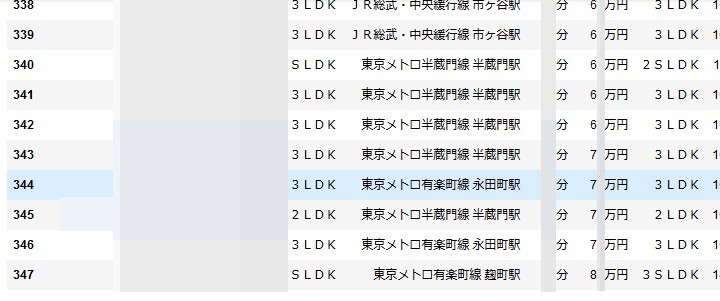
notebookでデータフレームの一部を表示するとこんな感じになります。(物件名などにはモザイクがかかっています)
終わりに
これで家賃ごとに検証したり、色々と捗りますね。
重回帰分析を行えば、家賃の予測などにも使えます。
細かく学習用データを作っていくなら個別ページに飛び、物件詳細ページから情報を取ってきてもいいかと思いますが、当然時間はかかります。
大体この方法で取得した、物件数は1500件程度。実行時間は30分ほどかかりました。
人の手でやっても変わらないような時間ですが、自動化することによって、他の作業をすることができますし、定期的にスクレイピングできて、物件情報を更新またはストックできます。
スクレイピングを禁止しているサイトも多いので、今回の方法を試す際には自己責任でお願いします。
長くなりましたが、ここまでお読み頂きありがとうございました。