今回は、TensorFlowを使ってディープラーニングする方法について徹底解説します!
TensorFlowとは?
引用元:https://www.tensorflow.org/overview?hl=ja
TensorFlow(テンソルフロー、テンサーフロー)とは、Google社が開発している、ディープラーニング向けのフレームワークです。
ニューラルネットワークを使用した学習を行うための機能が、オープンソースで提供されています。
対応言語はC言語、C++、Python、Java、Goと幅広く、Pythonは3.6〜3.10のバージョンで利用できます。
TensorFlowについて、詳しくは「TensorFlowとは?TensorFlowを徹底解説」でわかりやすく解説しています。
TensorFlowを使用する際には、Kearsというライブラリが便利です。
裏側でTensorFlowを動かす事ができるライブラリで、非常に短いコードでディープラーニングのコードを実装できます。
今回はこちらのライブラリを活用しながら、試していただく内容になっています。
TensorFlowをインストールする方法
TensorFlowのインストールがまだの方は、是非こちらを使ってみてください。
Python、Tensorflow、その他諸々のセットアップ環境を、わずか1分で仮想環境としてGoogleが用意してくれるツールです。
https://colab.research.google.com/github/AIkenkyujo/blog/blob/master/Tensorflow_deeplearning.ipynb
上のリンクで開いたデータは、Googleのアカウントでログインすると使えます。
記事を読みながら、コードセル右の再生ボタン(セルを実行)を押し実行してみてください。
(一番最初にメッセージが表示されますが、「このまま実行」→「はい」で進めてください。)
TensorFlowを使ってディープラーニングをする方法
それではここから、TensorFlowを使ってディープラーニングをする方法をご紹介します。
この記事では、MNIST(エムニスト)という機械学習を学び始める際によく利用されるデータセットを利用して、ディープラーニングの学習モデルを構築しています。
MNISTとは、Mixed National Institute of Standards and Technology databaseの略で、0~9までの手書きの数字画像が含まれたデータセットです。
MINSTの中には28px×28pxの手書きの数字画像(0〜9まで)を数値化したデータが入っており、学習用のデータが60,000個、テスト用のデータが10,000個の、合計70,000個の手書き文字データが含まれています。
MNISTのデータはこちらからダウンロードできます。

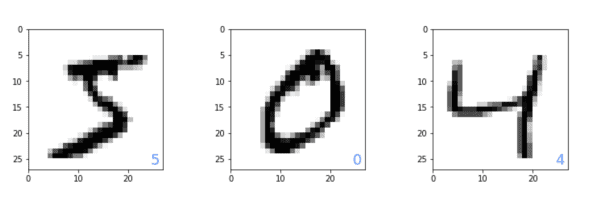
まずは、今回の問題を確認するため、ライブラリのインポートとデータのインポートをしましょう。
import matplotlib.pyplot as plt
%matplotlib inline# MNIST データインポート
(train_data, train_label), (test_data, test_label) = mnist.load_data()# データビジュアライズ
plt.figure(1,figsize=(12, 3.2))
plt.subplots_adjust(wspace=0.5)
plt.gray()
for i in range(3):
plt.subplot(1, 3, i + 1)
img = train_data[i, :, :]plt.pcolor(255 – img)
plt.text (24.5, 26, “%d” % train_label[i],
color=’cornflowerblue’, fontsize=18)
plt.xlim(0, 27)
plt.ylim(27, 0)
plt.show()
MNISTはサイトからダウンロードできますが、今回使用するKerasからも読み込めます。
「from keras.datasets import mnist」をimportするだけでMNISTデータがインポートできます。
MNISTのデータは画像データと言っても、数値のデータです。
train_dataに格納されたのは60000×28×28の配列で、i番目の画像はtrain_data[i, :, :]で取り出せます。
train_labelに格納されたのは、60000までの1次元配列で、train_label[i]には0~9までの正解ラベルの数値が格納されています。
ビジュアライズするプログラムは、60000個ある学習データの中から始めの3個を取り出し、グラフ描画用ライブラリのmatplotlibにて可視化をしています。右下に表示される青い文字は正解ラベルの数値です。
まずは今回の問題を確認するため、ライブラリのインポートとデータのインポートをしてみましょう。
from keras.utils import np_utils
# 学習データとテストデータの整形
num_classes = 10
train_data = train_data.reshape(60000, 784).astype(‘float32’)
train_data = train_data / 255
train_label = np_utils.to_categorical(train_label, num_classes)
test_data = test_data.reshape(10000, 784).astype(‘float32’)
test_data = test_data / 255
test_label = np_utils.to_categorical(test_label, num_classes)
train_dataとtest_dataに格納されたデータは、ディープラーニングで使用するために60000×784(28×28)の配列に変換し、実数値として扱うためにfloat32型に変換しています。
また、各ピクセルの数値は0~255までの数字で白~黒を表現していますので、255で割ることによって0~1までの数値に正規化をしています。
train_labelとtest_labelに格納されたデータは、Kerasでラベルデータとして扱うために、np_utilsという変数を使って整形しておく必要があります。
今回は、このようなニューラルネットワークを構成していきます。
入力データは先程整形した784個の数値となります。
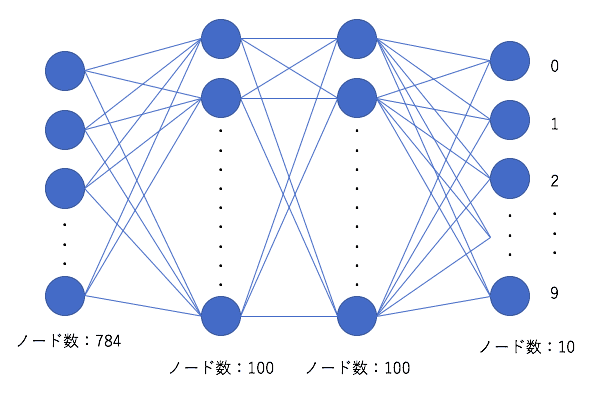
ニューラルネットワークの構造を設計します。
from keras.layers import Dense, Activation
from keras.optimizers import Adammodel = Sequential()
model.add(Dense(1000,input_dim=784, activation=’relu’))
model.add(Dense(100, activation=’relu’))
model.add(Dense(10, activation=’softmax’))
model.compile(loss=’categorical_crossentropy’,
optimizer=Adam(), metrics=[‘accuracy’])
model.addでは、各層のノード数、入力データ(input_dim:省略可能)と活性化関数(activation)を設定することで、ニューラルネットワークの設定ができます。
もしもう1層隠れ層を増やしたいな、となったら、このように追記するだけで簡単に層を増やすことができます!
model.add(Dense(100, activation=’relu’))
model.add(Dense(200, activation=’relu’))#追加!
model.add(Dense(10, activation=’softmax’))
model.compile(loss=’categorical_crossentropy’,
optimizer=Adam(), metrics=[‘accuracy’])
TensorFlowとKerasには、これらの活性化関数などの数式が実装されているため、実際に使用する際には呼び出すだけで使用できるのが良いところですね。
いよいよ学習です。
import time
startTime = time.time()
history = model.fit(train_data, train_label, epochs=10, batch_size=1000,
verbose=1, validation_data=(test_data, test_label))
score = model.evaluate(test_data, test_label, verbose=0)
print(‘Test loss:’, score[0])
print(‘Test accuracy:’, score[1])
print(“Computation time:{0:.3f} sec”.format(time.time()-startTime))
学習にかかった時間を表示するためにtimeというライブラリをimportしていますが、必須ではありません。
TensorFlowとKerasで学習を行うのは、model.fitというメソッドです。学習データと学習データのラベル、エポック数、バッチサイズ、検証データなどを指示するだけで学習がスタートします。
今回は、10エポック回しています。各エポックのval.accがテストデータに対しての正答率になります。
60000/60000 [==============================]-2s 30us/step-loss: 0.8391-acc: 0.7754-val_loss: 0.3050-val_acc: 0.9114
Epoch 2/10
60000/60000 [==============================]-1s 19us/step-loss: 0.2703-acc: 0.9217-val_loss: 0.2261-val_acc: 0.9343
Epoch 3/10
60000/60000 [==============================]-1s 16us/step-loss: 0.2077-acc: 0.9403-val_loss: 0.1867-val_acc:0.9439
Epoch 4/10
60000/60000 [==============================]-1s 15us/step-loss: 0.1717-acc: 0.9506-val_loss: 0.1635-val_acc: 0.9510
Epoch 5/10
60000/60000 [==============================]-1s 15us/step-loss: 0.1458-acc: 0.9581-val_loss: 0.1395-val_acc: 0.9588
Epoch 6/10
60000/60000 [==============================]-1s 16us/step-loss: 0.1257-acc: 0.963-val_loss: 0.1234-val_acc: 0.9642
Epoch 7/10
60000/60000 [==============================]-1s 21us/step-loss: 0.1118-acc: 0.9674-val_loss: 0.1172-val_acc: 0.9652
Epoch 8/10
60000/60000 [==============================]-8s 135us/step-loss: 0.1000-acc: 0.9711-val_loss: 0.1110-val_acc: 0.9667
Epoch 9/10
60000/60000 [==============================]-2s 26us/step-loss: 0.0903-acc: 0.9736-val_loss: 0.1062-val_acc: 0.9674
Epoch 10/10
60000/60000 [==============================]-1s 17us/step-loss: 0.0814-acc: 0.9766-val_loss: 0.0992-val_acc: 0.9686
Test loss: 0.09917270675133914
Test accuracy: 0.9686
Computation time:19.885 sec
学習が進んでいく様子を確認してみましょう。
loss関数と精度をエポック毎にビジュアライズしてみます。
plt.subplots_adjust(wspace=0.5)plt.subplot(1, 2, 1)
plt.plot(history.history[‘loss’], label=’training’, color=’black’)
plt.plot(history.history
[‘val_loss’], label=’test’,
color=’cornflowerblue’)
plt.ylim(0, 10)
plt.legend()
plt.grid()
plt.xlabel(‘epoch’)
plt.ylabel(‘loss’)plt.subplot(1, 2, 2)
plt.plot(history.history[‘acc’], label=’training’, color=’black’)
plt.plot(history.history[‘val_acc’],
label=’test’, color=’cornflowerblue’)
plt.ylim(0, 1)
plt.legend()
plt.grid()
plt.xlabel(‘epoch’)
plt.ylabel(‘acc’)
plt.show()
結果はこのようになりました。
左がloss関数、右が精度です。
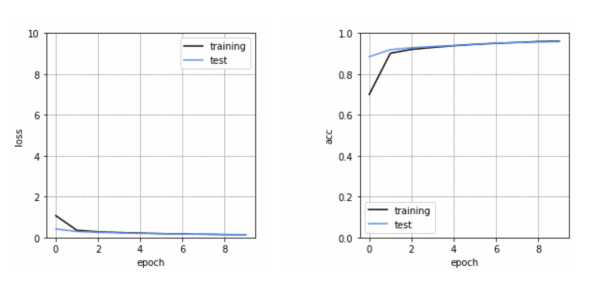
epochが進むごとに、Trainingの精度が上がっていくにもかかわらず、Testの精度が下がっていくような状況になると、学習データにフィットしすぎている過学習(オーバーフィッティング)という状態になっている可能性があります。
今回はそのようなことは見られませんので、問題なく学習が進んだと言えます。
最後に、それぞれの画像に対して予測された数字がいくつだったのか、そして、間違ったものがどれかを表示してみましょう。
96枚の画像を表示するプログラムになっています。
import numpy as np
n_show = 96
y = model.predict(test_data)
plt.figure(2,figsize=(12, 8))
plt.gray()
for i in range(n_show):
plt.subplot(8, 12, i + 1)
x = test_data[i, :]x = x.reshape(28, 28)
plt.pcolor(1-x)
wk = y[i, :]prediction = np.argmax(wk)
plt.text(22, 25.5, “%d” % prediction, fontsize=12)
if prediction != np.argmax(t
est_label[i, :]):
plt.plot([0, 27], [1, 1], color=’cornflowerblue’, linewidth=5)
plt.xlim(0, 27)
plt.ylim(27, 0)
plt.xticks([], “”)
plt.yticks([], “”)
plt.show()
青い線が表示されている部分が、予測を間違えたものです。

TensorFlowについてまとめ
いかがだったでしょうか。
TensorFlowとKerasを使うことで、簡単にニューラルネットワークが構築できることがご理解いただけたのではないでしょうか。
途中に出てきたニューラルネットワークの層の数やノード数を変更して、精度が上がったり下がったりするのを体感してみてください!