Scikit-learnは初めて利用する人には難しく、どうやって使うか分からないことも多いでしょう。
今回は、そんなScikit-learnの使い方について徹底解説します!
Scikit-learnの使い方を調べている人はぜひ参考にしてください。
Scikit-learnとは?
Scikit-learnは、Pythonで使用できるオープンソースプロジェクトのライブラリです。
読み方は「サイキットラーン」です。
オープンソースですので、誰でも自由に利用したり再配布でき、ソースコードを覗いてどんな計算が行われているかを確認することもできます。
Scikit-learnはかなり活発なユーザーコミュニティの中で開発・改良が加えられているため、ドキュメントも整備されているので初心者でもスムーズにScikit-learnを使い始めることができるようになっています。


Scikit-learnの使い方

Scikit-learnは、様々なアルゴリズムが含まれたライブラリですので、それぞれのアルゴリズムを呼び出して使用します。
ここでは、シンプルなコードを使用して概要をつかんでいただきます。
Scikit-learnを使ったプログラムは基本的に以下の構成となっています。
- ライブラリのインポート
- 学習データとテストデータの用意
- アルゴリズムの指定と学習実行
- テストデータでテスト
- 必要に応じて精度などをビジュアライズ
今回の題材となっているこちらのプログラムを解説していきます。
1.ライブラリのインポート
Scikit-learn全体をインポートすることもできますが、Scikit-learn自体が非常に多くの機能を持ったものですので、Scikit-learnの一部のみをインポートすることが多いです。
今回のプログラムでは、クラス分類問題でよく使われる、SVM(サポートベクターマシン)をインポートしています。
また、学習結果を表示するためのmetricsから、精度を出力できる
from sklearn.metrics import accuracy_score
accuracy_scoreもインポートしています。
2.学習データとテストデータの用意
学習データとテストデータを用意します。
今回は単純な問題で試したいので、0と1のみが含まれた多重リストを使用します。
train_dataが学習用の入力データ、train_labelが正解ラベルとなり、これが教師データとなります。
test_dataはテストデータで、あまり面白くありませんが学習データと同じ多重リストを用意しました。
このテストデータに対して学習済みモデルが正しく[0, 1, 1, 0]と判定できるかを確認します。
train_data = [[0, 0], [1, 0], [0, 1], [1, 1]]train_label = [0, 1, 1, 0]#テストデータを準備
test_data = [[0, 0], [1, 0], [0, 1], [1, 1]]
3.アルゴリズムの指定と学習実行
続いて、機械学習アルゴリズムを指定します。
先程インポートしたSVMの中から、クラス分類をするためのSVC(Support Vector Classification)を選択します。
学習実行をするには、clf.fit()を使用します。
実はScikit-learnは、様々な機械学習アルゴリズムに対応するために、多くのアルゴリズムにおいてclf.fit() = 学習実行という記述の仕方になっています。
clf.fit()の引数には、学習用のデータとラベルデータを指定するだけなので簡単ですね。
#アルゴリズムを指定
clf = svm.SVC(C=10, gamma=0.1)
#学習
clf.fit(train_data,train_label)
4.テストデータでテスト
学習が終わりましたので、用意しておいたテストデータを利用してテストを行います。
学習がclf.fit()だったのに対し、テストはclf.predict()を使用します。
こちらも引数にテストデータを入れることで学習済みモデルを利用した予測を行ってくれるため、非常に簡単にテスト部分を実装することが可能です。
test_label = clf.predict(test_data)
5.必要に応じて精度などをビジュアライズ
ここまでで学習とテストが終わっていますので、正解したかどうか、またその精度をビジュアライズします。
print(“テストデータ:{0},予測ラベル:{1}”.format(test_data,test_label))
print(“正解率= {}”.format(accuracy_score([0, 1, 1, 0], test_label)))
今回は非常に簡単なデータでしたので、以下のような正解率100%のモデルができたことが確認できます。
予測ラベル:[0 1 1 0]正解率= 1.0
Scikit-learnの使い方 応用編
簡単なプログラムでしたが、機械学習アルゴリズムを使ったクラス分類問題が行えたことが分かったと思います。
これを応用すると、様々なアルゴリズムでのクラス分類ができることがわかるでしょう。
例えば、代表的なアルゴリズムのインポートと学習方法は以下のように指定することで実行できます。
ロジスティック回帰
clf = LogisticRegression()
決定木
clf = DecisionTreeClassifier()
ランダムフォレスト
clf = RandomForestClassifier()
勾配ブースティング決定木
clf = GradientBoostingClassifier()
k近傍法
clf = KNeighborsClassifier()
ナイーブベイズ
clf = GaussianNB()
確率的勾配降下法(SGD:Stochastic Gradient Descent)
clf = SGDClassifier()
Scikit-learnの使い方 応用実装編
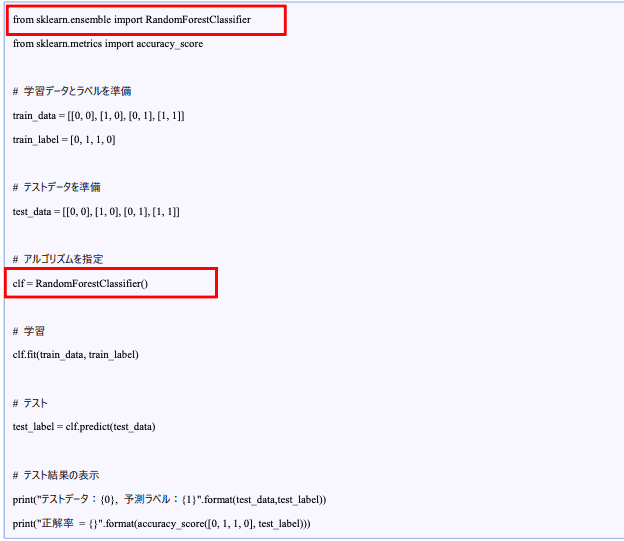
Scikit-learnでは、このような多数のアルゴリズムが用意されており、その名前を変えることで簡単に違うアルゴリズムを使用した学習が実行できます。
ここでは先程のプログラムを編集して、ランダムフォレストで先程の問題を解いてみます。
変更する箇所はたったの2箇所です。
本来はそれぞれのアルゴリズムにハイパーパラメーターがあり、引数で指定したり調整が必要ですが、そちらは次の機会にご紹介します。
Scikit-learnの使い方についてまとめ
今回はScikit-learnの使い方について解説しましたが、いかがだったでしょうか。
たくさんのアルゴリズムが実装されていますが、それらが非常に簡単に使えるライブラリ、それがScikit-learnであることがご理解いただけたのではないでしょうか。
ぜひいろいろなアルゴリズムを使ってScikit-learnを試してみてください。