近年のAIブームでは、ディープラーニングという機械学習技術の発展がスタートとなって、AIの活用が活発化しています。
ディープラーニングの火付け役となったのが、今回テーマとして取り上げる画像認識AIです。
画像認識AIにはどのようなものがあるのか、見ていきましょう。
画像認識とは
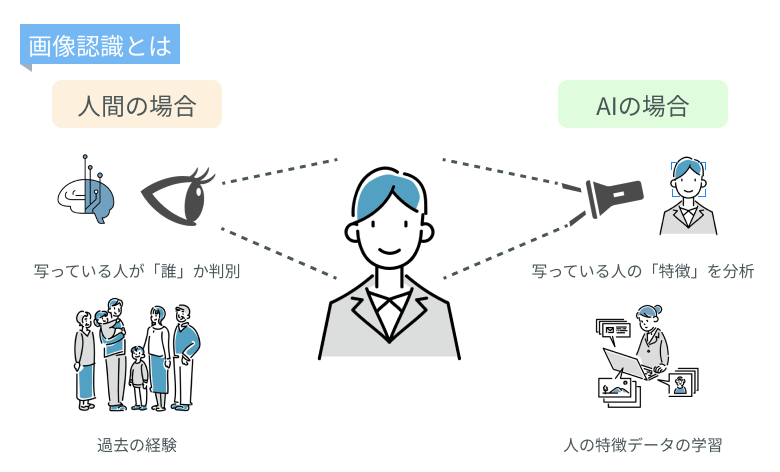
画像認識とは、コンピュータビジョンという分野で長年研究されてきました。
画像データを利用して、どこに何が写っているのかを判断するなどの処理をコンピュータで行えるようにするための研究です。
画像認識に機械学習を取り入れることで認識精度などを飛躍的に向上させることができました。
また、ディープラーニング技術を使用することで、画像を生成する画像生成モデルの研究も活発に行われています。
画像認識の種類
ディープラーニングを使用して画像認識をする場合、解きたいタスクによって主に以下の3つの種類があります。
- 画像分類(classification)
- 物体検出(detection)
- 画像セグメンテーション(segmentation)
画像分類
画像分類は、入力された画像が何かを識別します。
1枚の画像に対してそれが何かを予測するため、基本的には1つの物体が大きく写った画像を使用して学習したり、予測したりします。

物体検出
2番目の物体検出は、入力された画像のどこに何があるのかを識別する手法です。
「どこに」というのを認識するために、四角で囲んだ表現をすることが多いです。
この四角の枠をバウンディングボックスと呼び、それぞれのバウンディングボックスの中にある物体が何かを検出します。

画像セグメンテーション
画像セグメンテーションは、入力された画像の領域に何があるのかを識別します。
境界線で区分けされた境界領域ごとに、何が写っているのかを識別できます。
セマンティックセグメンテーションや、ピクセルラベリングとも呼ばれます。
これは、領域の識別と入っても、画像の1ピクセル1ピクセルが何かを予測する事であるためです。
画像認識のアーキテクチャ
2012年に起こったディープラーニングのブレークスルーにより、画像認識の精度は急激に高くなりました。
当時、ILSVRCという画像コンペで、カナダのトロント大学のヒントン教授が率いるチームが、「AlexNet」と名付けたディープラーニングのアーキテクチャで精度を出したのです。
翌年以降は、様々な画像認識のアーキテクチャが発表されました。
アーキテクチャとは、画像認識のディープラーニングを行うための様々な工夫を行ったネットワーク構造を示し、様々な特徴を持ったアーキテクチャが研究されてきました。
近年では、これらのアーキテクチャを流用することで、少ない教師データからでも高精度の画像認識モデルを作成できる「転移学習」と呼ばれる手法が多く利用されています。
以下の表は、画像識別の種類とアーキテクチャ一覧です。
それぞれ代表的なものを集めましたので、この他にも非常に多くのアーキテクチャが存在しています。
画像識別の種類とアーキテクチャ一覧

画像識別アーキテクチャの論文を閲覧する方法
それぞれのアーキテクチャについて知るためには、もともとの研究論文を読むことが早道です。
多くの研究論文は、
- arXiv
- Google Scholar
といったサイトで見ることができます。
arXiv(アーカイブ)
物理学、数学、計算機科学、量的生物学、計量ファイナンス、統計学の、プレプリントを含む様々な論文が保存・公開されているウェブサイトです。
AI関連の論文も多数公開されています。
Google Scholar
Googleの提供する検索サービスの一つで、主に学術用途での検索を対象としており、論文、学術誌、出版物の全文やメタデータにアクセスできます。
ここから、画像分類、物体検出、画像セグメンテーションそれぞれの代表的なアーキテクチャについてまとめます。
画像分類の代表的なアーキテクチャ
画像分類の代表的なアーキテクチャを、下記にまとめました。
これ以外にも、非常に多くのアーキテクチャが存在しており、現在も研究が進んでいます。
この順番は、ディープラーニングの始まりからの進化として、歴史と同じように捉えていただくとわかりやすいです。
- AlexNet
- VGG
- GoogleNet
- ResNet
- DenseNet
- MobileNet
1.AlexNet
2012年のILSVRCの優勝モデルです。
それまでは、ディープラーニングではない機械学習の手法のSVM(サポートベクターマシン)というアルゴリズムを使用したアプローチが一般的でしたが、SVMに大差をつけて優勝し、ディープラーニングの火付け役となりました。
畳み込み層5層、全結合層3層の8層により構成される構造がシンプルなため、他のネットワークのベースとして使用されることも多いです。
特徴として、「ReLU関数」「Dropout」「データ拡張」といった工夫により精度が上がりました。
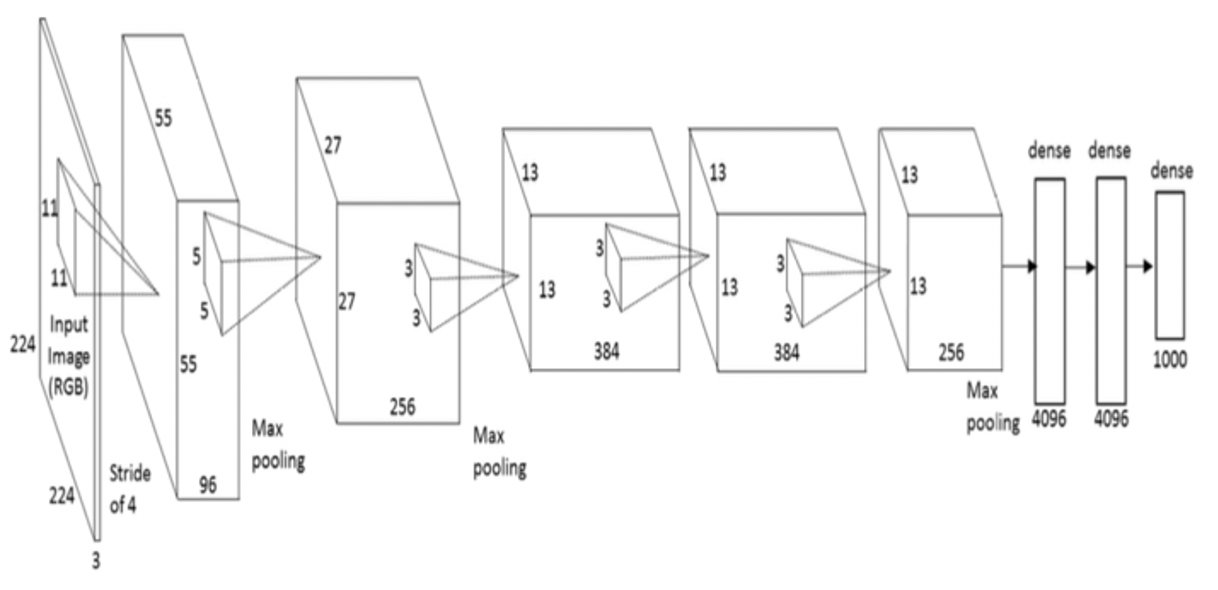
引用:researchgate
2.VGG
2014年のILSVRCの2位のモデルです。
16層(VGG16)または19層(VGG19)からなるCNNモデルです。
精度もよく使い勝手がいいため、この構造をベースにした研究が多く見られ、3×3の畳み込みを利用しているのが特徴です。
AlexNet同様に、全結合層を持っていますが、この全結合層により学習パラメータが多くなるため、ネットワーク全体の計算量が多くなり重いモデルとなっています。
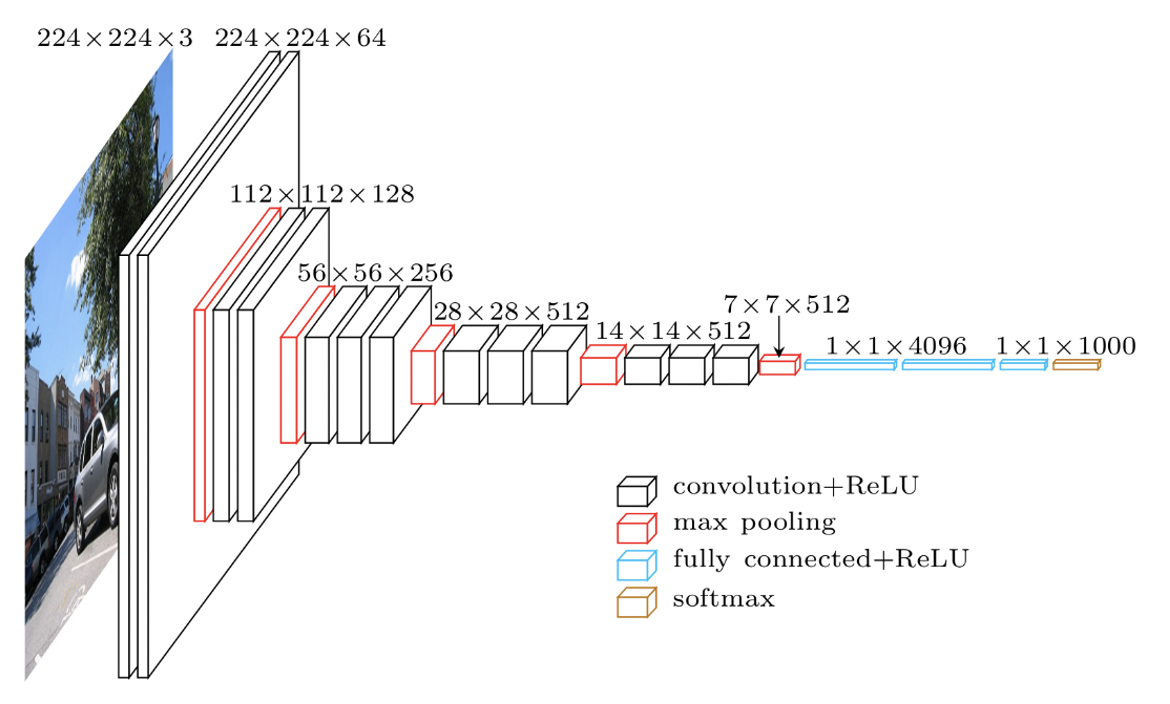
引用:qiita
3.GoogLeNet
2014年のILSVRCの優勝モデルで、22層で構成されるCNNです。
Inception module(複数種類の畳込み)、Auxiliary Loss(中間層における誤差の計測)、global average pooling(フィルタ平均による出力)が特徴です。
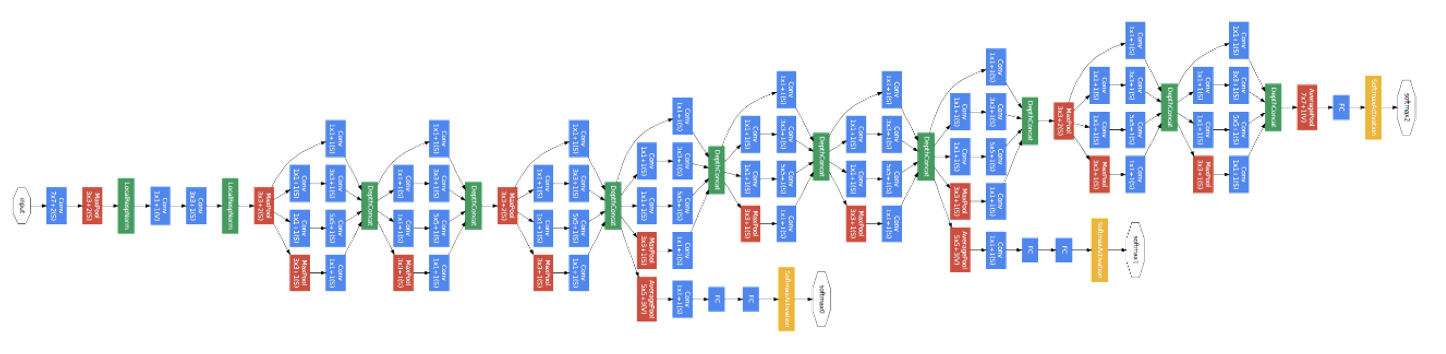
引用:medium
4.ResNet
2015年のILSVRCの優勝モデルで、152層で構成されるCNNです。
勾配消失問題によって学習が進まない問題をResidual blockという手法を使って解決し、表現力が高い非常に深い層を実現したネットワークです。
Shortcut Connection、Residual block(残差ブロック)、Batch normalization(バッチ正規化)という特徴を持ちます。

引用:medium
5.DenseNet
ResNetを改善したモデルで、従来よりコンパクトなモデルにもかかわらず、高い性能を持つことが特徴です。
ショートカット接続をたくさん入れることで、層間の情報伝達をしやすくしています。
自身より前の層の出力を入力に含めて計算することで、層間が密(dense)になっていることから、DenseNetと呼び、Dense BlockとTransition Layerを特徴に持ちます。

https://arxiv.org/pdf/1608.06993.pdf
6.MobileNet
モバイル端末でも使用できるほど計算量やメモリ使用量が小さく、精度と計算負荷のトレードオフを調整できるネットワークです。
VGG16比で学習速度が約3倍速、モデルサイズが約180分の1という結果が出ています。
畳み込み層を Depthwise Convolution (空間方向の畳み込み) と Pointwise Convolution (チャネル方向の畳み込み:1×1 Convolution) に分解して計算する「 Depthwise Separable Convolution」を行うことで、計算コストを下げることができています。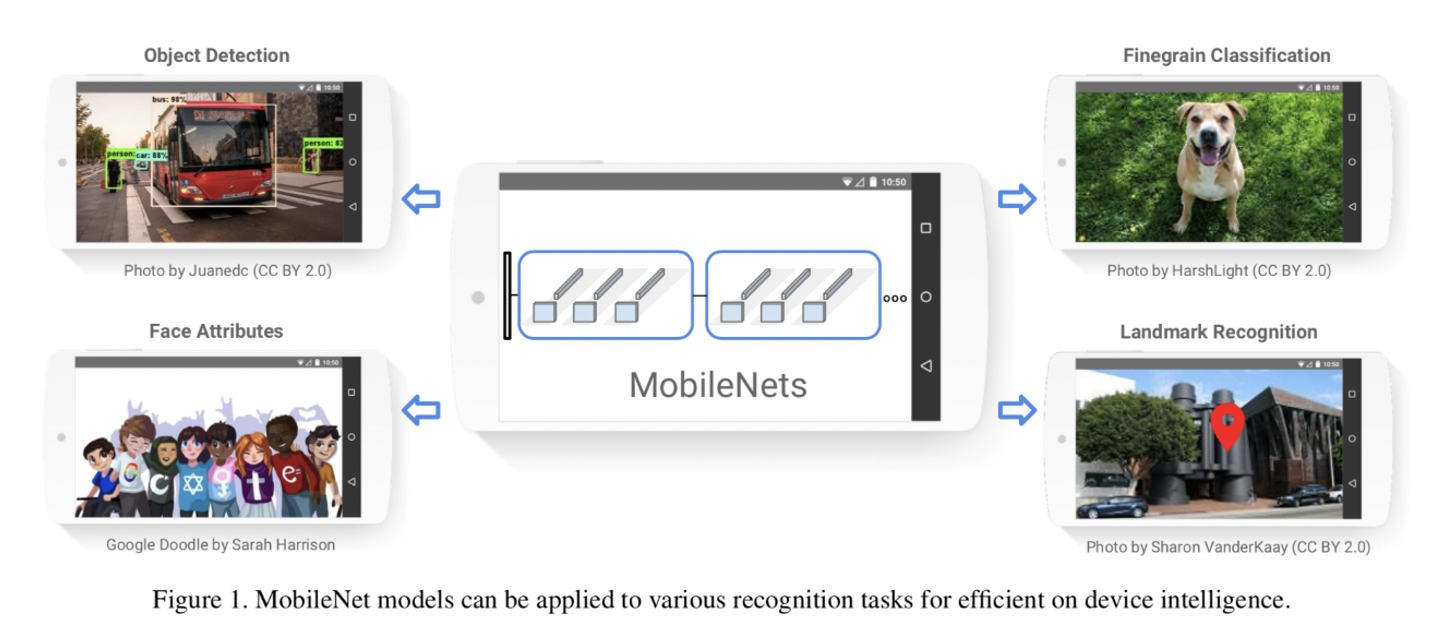
https://arxiv.org/pdf/1704.04861.pdf
物体検出の代表的なアーキテクチャ
物体検出の代表的なアーキテクチャを下記にまとめました。
画像検出と同様、これ以外にも非常に多くのアーキテクチャが存在しており、現在も研究が進んでいます。
同じようなアーキテクチャ名が並びますが、R-CNN系の中でもFaster R-CNN以降のアーキテクチャは、End-to-End Learningと呼ばれています。
Fast R-CNN以前は、①物体がどこにあるか、という認識と、②それが何か、を別々で判断するため、Not End-to-End Learningと呼ばれていました。
End-to-End Learningは、①物体がどこにあるか、②それが何かを一気にディープラーニングで行ってしまうという考え方になっており、ボトルネックとなっていた①物体がどこにあるかの速度や精度を向上する事ができるようになってきています。
- R-CNN
- Fast R-CNN
- Faster R-CNN
- YOLO
- SSD
1.R-CNN
領域探索と画像認識するモデルを組み合わせて物体検出をするアーキテクチャです。
2,000箇所の物体がありそうな領域に対してCNNの予測を行うため、識別に時間がかかります。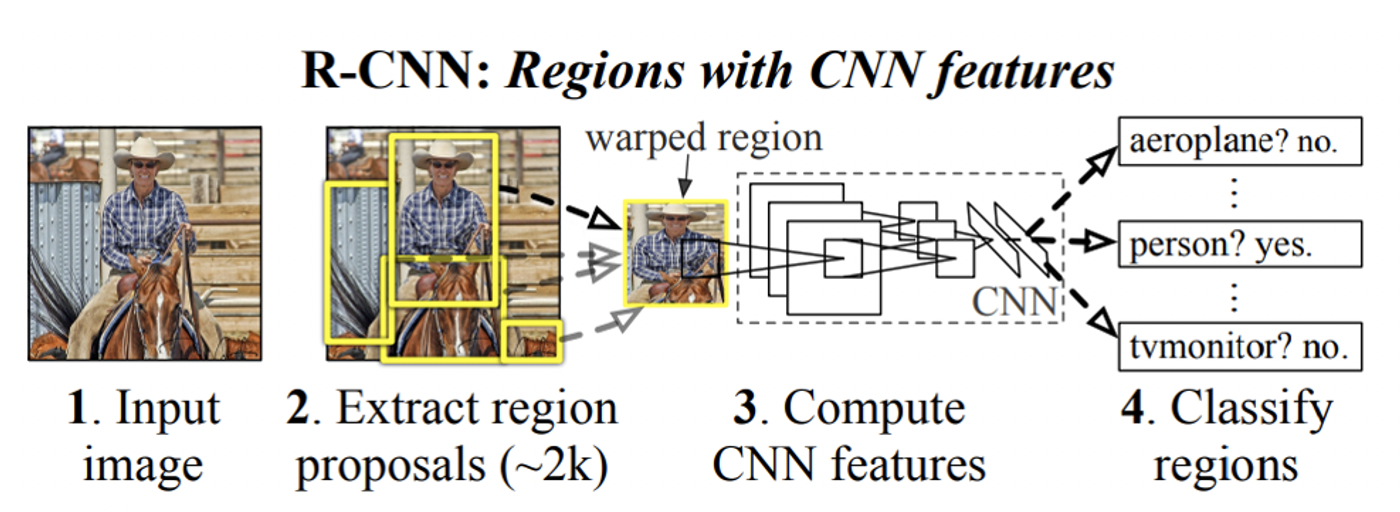
引用:CVPR
2.Fast R-CNN
R-CNNを改良し、演算時間を大幅に早めたアーキテクチャです。
RoI poolingと、 Multi-task Lossというアイデアを採用することで、VGG16を用いたR-CNNより9倍の学習速度、213倍の識別速度で、 SPP-netの3倍の学習速度、10倍の識別速度を持ちます。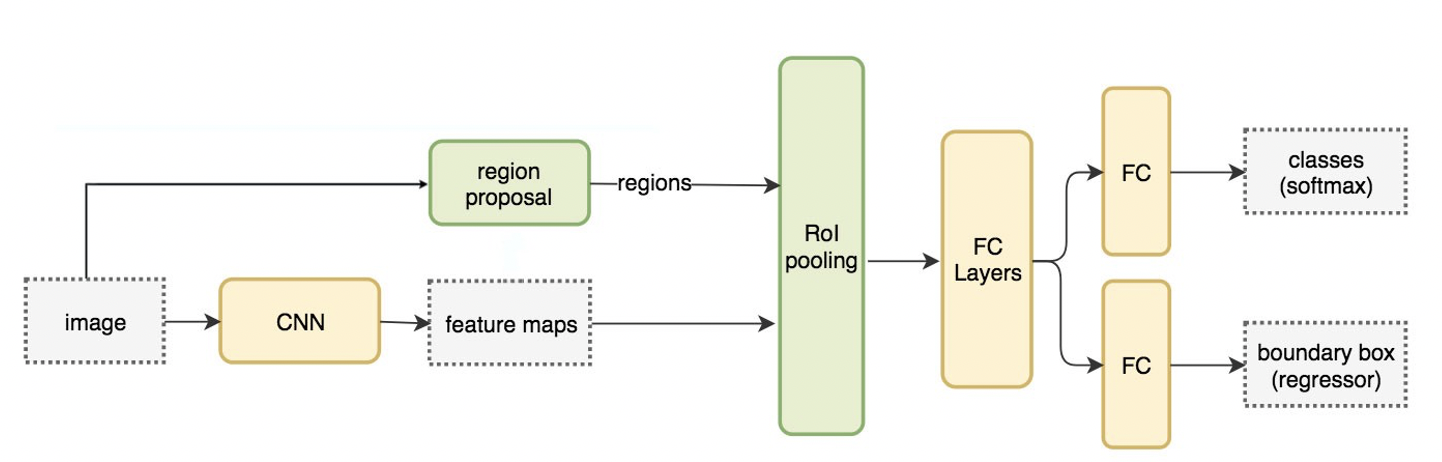
引用:medium
3.Faster R-CNN
Fast R-CNNを改良し、物体候補を検出するアルゴリズムにRegion Proposal Networkを使用することでEnd to Endで学習できるようにしたアーキテクチャです。
畳み込みレイヤーとRPNと分類/回帰ができるネットワークで構成されています。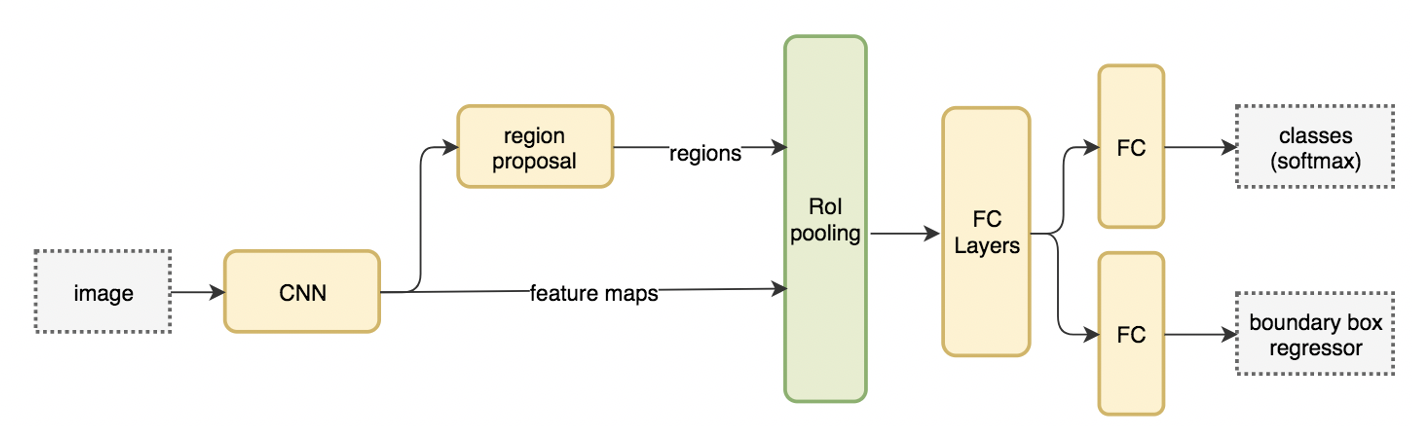
引用:medium
4.YOLO
Faster R-CNN以前は物体候補の生成→候補を分類/回帰という流れで分類問題として物体検出を行っていたのに対し、バウンディングボックスとクラスの識別を同時に(会期問題として)行うことで、リアルタイムに近い処理速度を出したアーキテクチャです。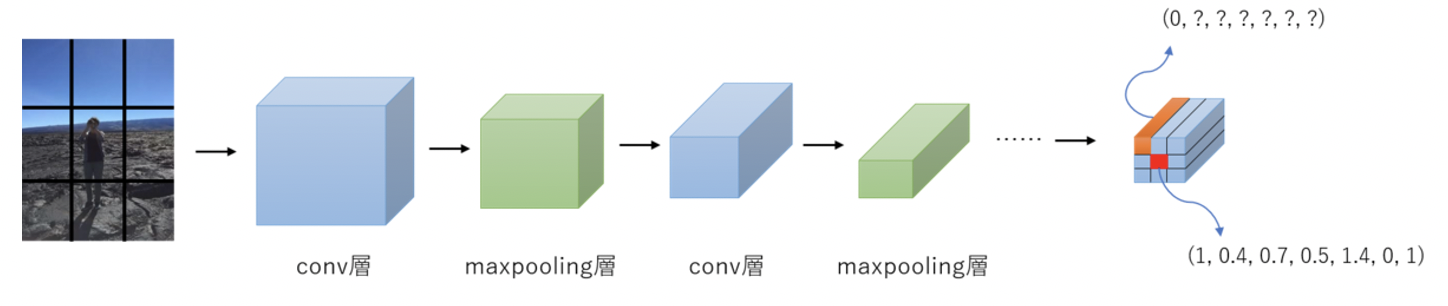
引用:hatenablog
5.SSD
処理速度がYOLO v1よりも高速で、Faster R-CNNと同程度の認識精度をもつアーキテクチャです。
https://arxiv.org/pdf/1512.02325.pdf
画像セグメンテーションの代表的なアーキテクチャ
画像セグメンテーションの代表的なアーキテクチャを下記にまとめました。
画像検出や物体検出と同様、これ以外にも非常に多くのアーキテクチャが存在しており、現在も研究が進んでいます。
- FCN
- SegNet
- U-Net
1.FCN
畳み込み層とプーリング層のみで構成される(全結合層を持たない)アーキテクチャにより、任意のサイズの入力画像からセマンティックセグメンテーションを行えます。
畳み込みを行って得た特徴マップをヒートマップ化し、逆畳込みすることによって、アップサンプリングして予測する仕組みをとっています。
2.SegNet
画像セグメンテーションのエンコーダー・デコーダーアーキテクチャです。
FCNよりも多くの特徴マップを利用していますが、エンコーダの特徴をコピーせず、Maxプーリングからのインデックスからコピーすることでメモリ効率を上げているのが特徴です。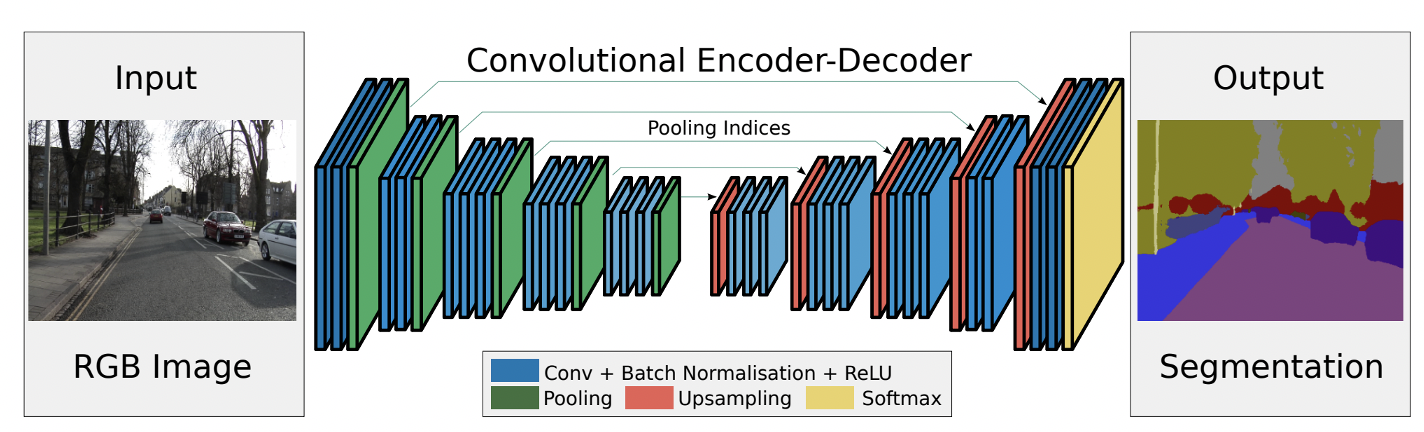
https://arxiv.org/pdf/1511.00561.pdf
3.U-Net
畳み込み層とプーリング層で構成されるアーキテクチャで、学習に使う画像の数が少なくてもセグメンテーションの精度がよく、学習および学習後の処理が高速なのが特徴です。
ネットワークの形がU字型に見えるのでU-Netと呼ばれています。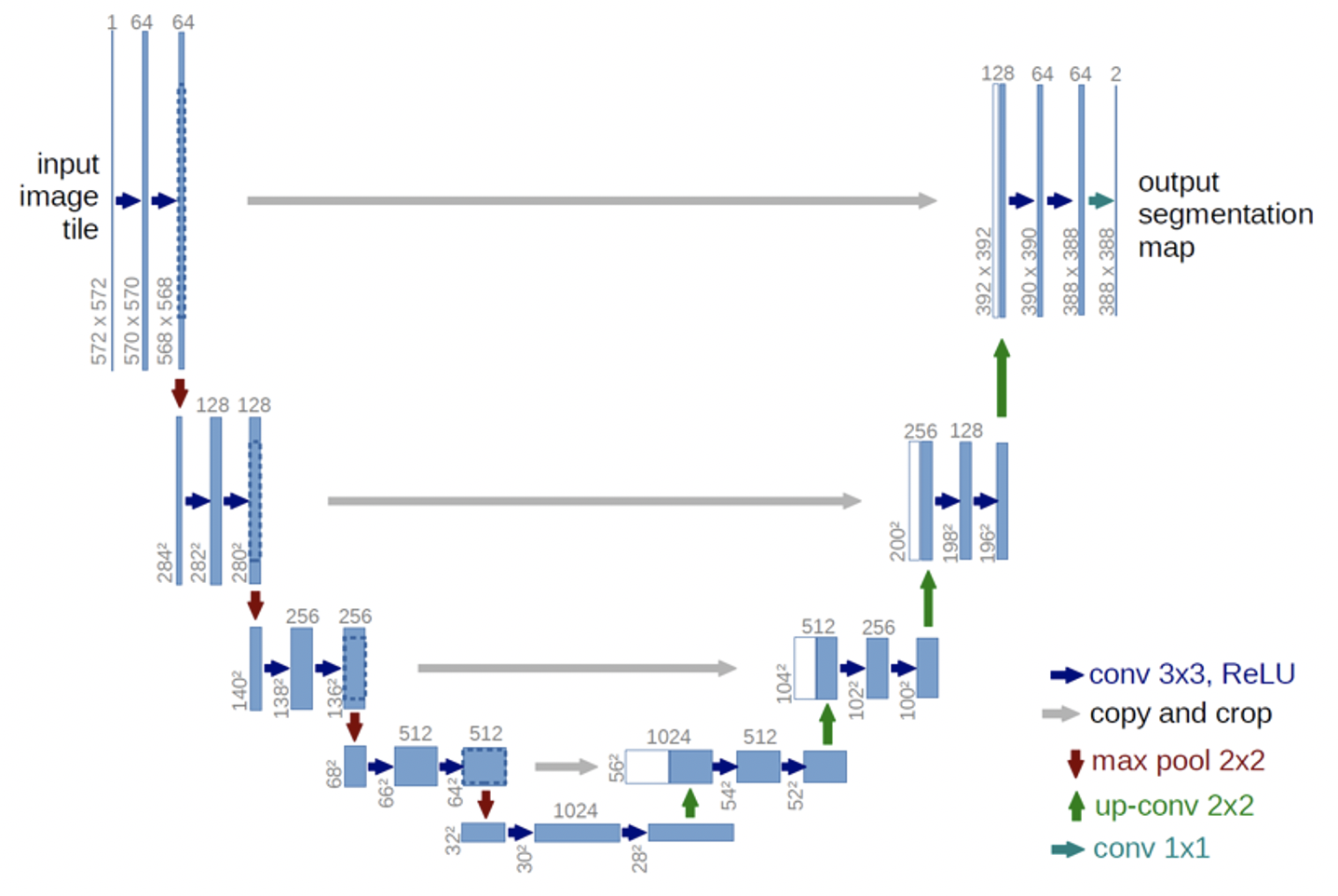
https://arxiv.org/pdf/1505.04597.pdf
まとめ
いかがだったでしょうか?
一言で画像認識と行っても、画像識別や物体検出、画像セグメンテーションなど、様々なタスク解決手法があることと、その中にも様々なアーキテクチャが研究されてきていることがわかりますね。
AIエンジニアは、日々公開される最新の研究論文などをチェックしつつ、実務に活用することが求められますので、是非様々な論文をチェックしてみてください。