
今回は、画像分類の6つの代表的なアーキテクチャの特徴をご紹介いたします。
まずは、画像処理に特化したディープラーニングの一つであるCNNとは何かから見ていきます。
続いて「AIが目を持った」と言われるほど目まぐるしい発展を遂げる要因となった、アーキテクチャであるCNNはどのような変遷を辿ってきたのかを、画像認識モジュールを使用し、その精度を競うコンペティションから見ていきましょう。
CNNとは
CNN(Convolutional Neural Network:畳み込みニューラルネットワーク)とは、画像認識に特化したディープラーニング(Deep Learning)の1つです。
Convolutional Neural Networkの略称がCNNです。
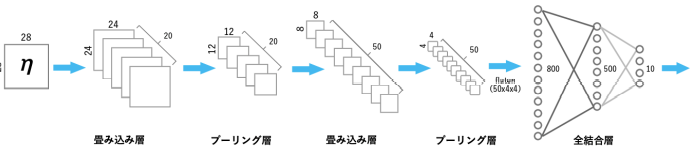
基本的には、「畳み込み層」&「プーリング層」の組み合わせを複数回繰り返したあと、最後に全結合層を繰り返して結果を出力します。
- 畳み込み層:エッジなどの特徴を抽出する層
- プーリング層:画像サイズを小さくする層
CNNについてはこちらの記事で詳しく解説しています。
畳み込みとは
畳み込みとは、フィルター(カーネル)を通して画像の特徴を抽出する画像処理です。画像の特徴がより強調されるのと同時に、「位置のズレ」にも強いモデルが出来ることで認識精度が上がります。
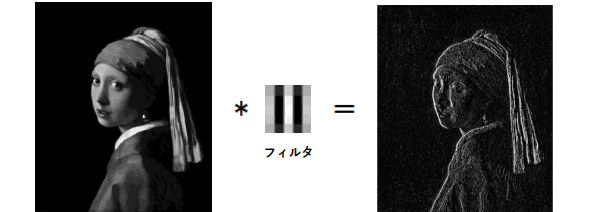
縦と横のフィルター(カーネル)を通すと…

プーリングとは
プーリングとは、縦・横方向の空間を小さくする演算のことです。画質を粗くする事でエッジがボケて境界があいまいになり、写真が多少シフトしても同じものだと認識できるようになります。
主なプーリングの方法はフィルターを通して、
- フィルター内の数値を平均させてプーリングする方法(mean pooling)
- 最大値を取るプーリング方法(max pooling)
の2種類です。ダウンサンプリングまたはサブサンプリングとも言われます。
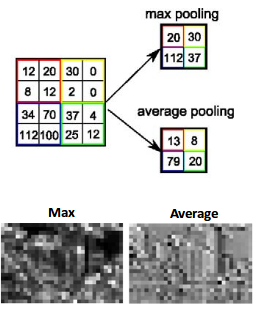
出典:quora
またCNN以外にも役に立つAI技術は数多くあります。
AI研究所の「ビジネス向けAI完全攻略セミナー」では1日でビジネスに使えるAI技術やAI作成方法をマスターできますので、ご興味のある方はぜひ受講をご検討ください。
画像認識競技会 ILSVRCとは
ILSVRCとは、ImageNet Large Scale Visual Recognition Challengeの略で、2010年から始まった大規模な画像認識の競技会です(2017年に終了)。チームに分かれて画像認識の精度を競う大会です。
ImageNetと呼ばれる1,400万枚以上の画像(画像数約 1,400 万枚 / 22,000カテゴリ)が含まれたデータセットを1,000クラスに分類し、どれだけ精度が高いかという画像分類タスクを競います。
「ImageNet Large Scale Visual Recognition Challenge(ILSVRC) 2012」で、AlexNetというCNNを使用したモデルが優勝し、ディープラーニングが注目を浴びるきっかけとなりました。
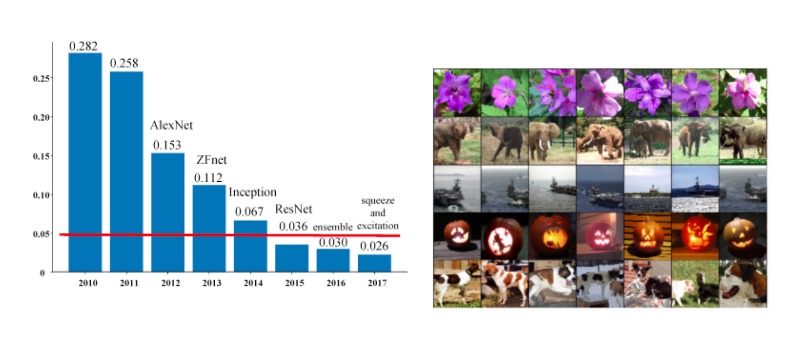
それでは、左図にあるように画像分類の6つの代表的なアーキテクチャの特徴をご紹介いたします。今や「AIが目を持った」と言われるまでにどのようなモデルが誕生し改良を重ねてきたのか。その変遷を辿っていきます。
画像認識についてはPythonで行うことも可能です。Pythonを使用した画像認識の方法については以下の記事で解説しています。
画像分類アーキテクチャ1:AlexNet
AlexNetは、冒頭でご紹介したディープラーニングの大きな転換期となったILSVRC2012の優勝モデルです。
古典的な画像認識アプローチであるSIFT + Fisher Vector + SVMに大差をつけて優勝し、ディープラーニングの火付け役となったモデルとなります。
構造がシンプルなため、他のネットワークのベースとして使用されることも多いモデルです。
畳み込み層が5層で、そのうちのいくつかにはMaxPooling層があります。また、出力層にはソフトマックス関数を持つ全結合層3層が使用されており、合計で8層により構成されています。
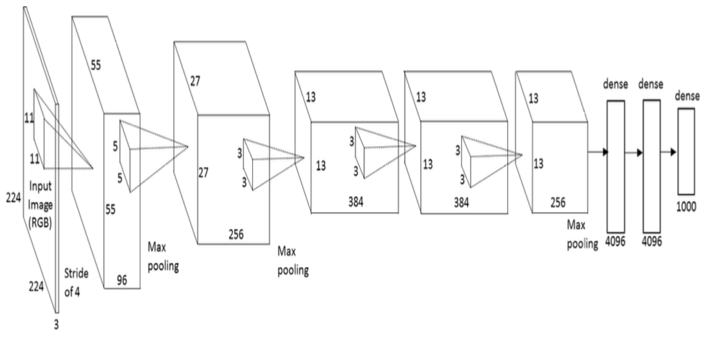
出典:researchgate
特徴としては、
- ReLU関数
- Dropout
- データ拡張
を採用している点です。
そうすることにより精度の向上に繋がりました。
データ拡張には、変換を行ったデータを保存する容量を拡張するために、リアルタイ ムで変換を行う工夫があります。
データ拡張の仕方には、平行移動・ゼロパディング・回転なども含まれ、このデータ変換の仕方は、他のデータセットでも必ず有用であるとは限らないことに注意が必要です。
画像分類アーキテクチャ2:VGG
続いてVGGについて見ていきましょう。
このVGGは、ILSVRC2014の2位、16層(VGG16)または19層(VGG19)からなるCNNを使用したモデルになります。
AlexNet同様、全結合層を持っていることでパラメータが多くなり、その結果ネットワークが重いのが欠点です。(後述のGAPなどで改善)。
しかし、精度もよく使い勝手がいいため、この構造をベースにした研究が多く見られています。
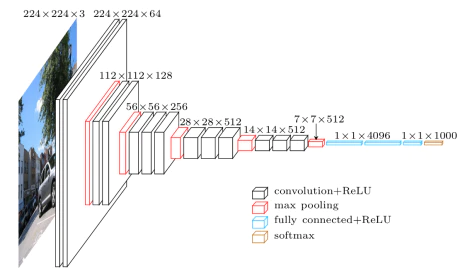
出典:qiita
大きな特徴としては、3×3の畳み込みを採用している点です。その結果、5×5のフィルターをかけた際の出力サイズと、3×3のフィルターを2回かけた際のサイズ が同じになります。
このように層が多重化することで、活性化関数の適用回数が増え、表現力が上がります。
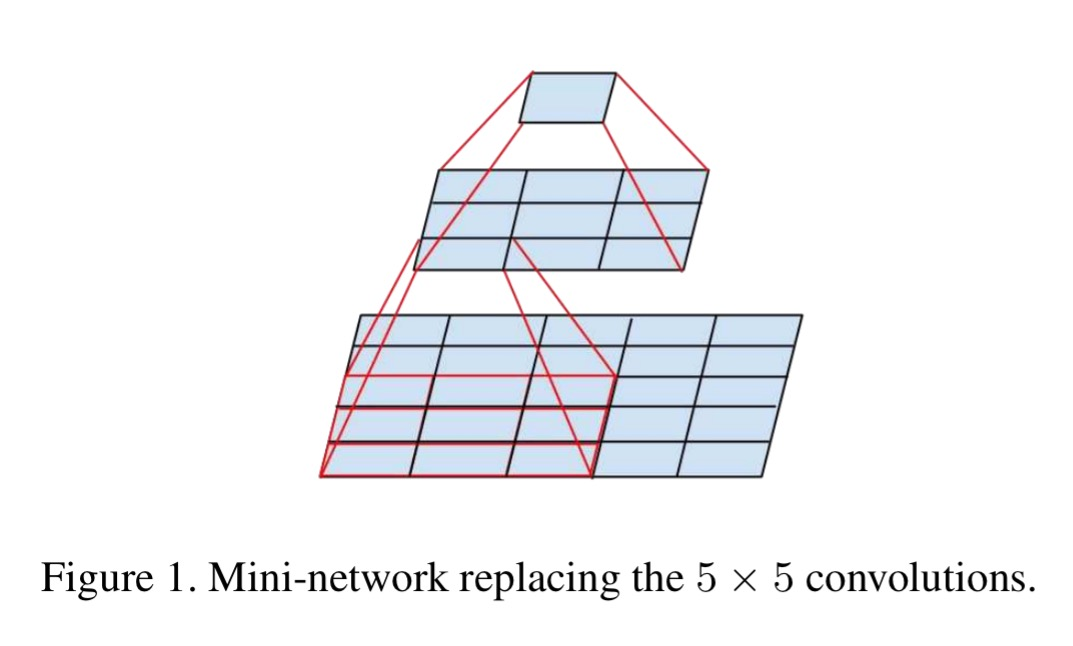
出典:acolyer
画像分類アーキテクチャ3:GoogleNet
続いて、前述のVGGが ILSVRC2014で二位を獲得した際の優勝モデルであるGoogleNetを見ていきましょう。このGoogleNetは、ILSVRC2014の優勝モデルで、22層で構成されているCNNを使用しています。
特徴としては、
- Inception module(複数種類の畳み込み)
- 1×1 Convolution(1×1の畳み込み)
- Auxiliary Loss(中間層における誤差の計測)
- global average pooling(フィルタ平均による出力)
の以上4つになります。
それぞれ具体的に見ていきます。
①Inception module
Inception moduleは、 1×1・3×3・5×5などの×の大きな畳み込みを、複数の畳み込み層を使って近似していきます。
複数の畳み込み層を並列に適用し、計算の結果を最後に連結して処理することで、非零つまり0以外のパラメータが減少でき(=スパース)、かつ多層化できることがメリットです。
GoogLeNetでは、Inception moduleを多数使うことでパラメーターが膨大な数になるため、各畳み込み計算の前に1×1 Convolutionを行い、次元を削減しています。
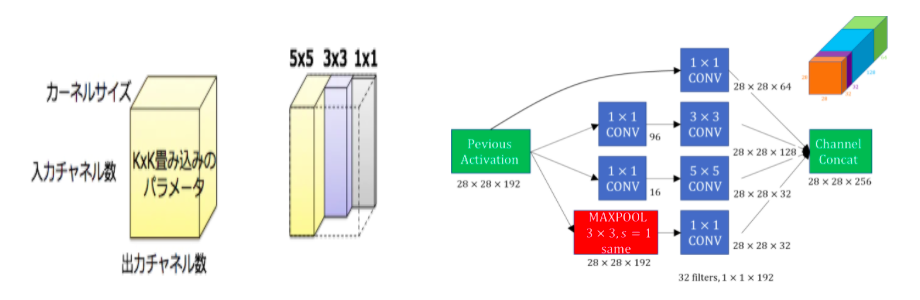
出典:qiita
出典:datahacker
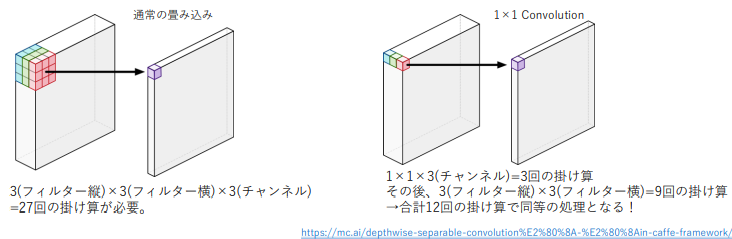
②1×1Convolution
1×1 Convolutionは、縦横方向の畳込みとチャンネル方向の畳込みを分割して計算するための手法になります。
パラメーターの次元数を減らせる・演算量を減らせる・層の多重化ができるといった特徴があり、ボトルネック層やPointwise Convolutionとも呼ばれています。
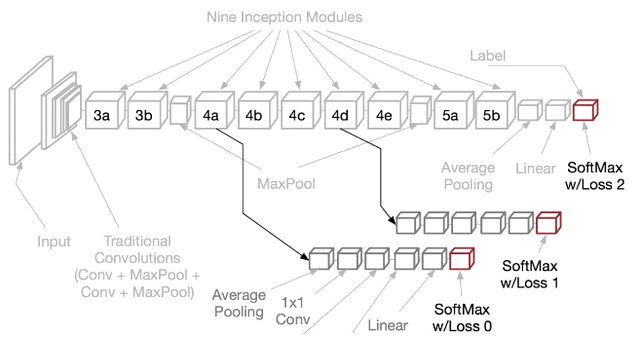
③Auxiliary Loss
Auxiliary Lossは、勾配消失問題を防ぐために、ネットワークの途中から分岐させたサブネットワークにおいてもクラス分類を行う手法です。
ネットワークの中間層に直接誤差が伝搬することで、中間層の勾配消失の防止・学習の効率化・ネットワークの正則化が実現されています。
このAuxiliary Lossは、サブネットワークなど複数の学習器を使うため、アンサンブル学習と同様の効果が得られると言われています。
出典:i.stack.
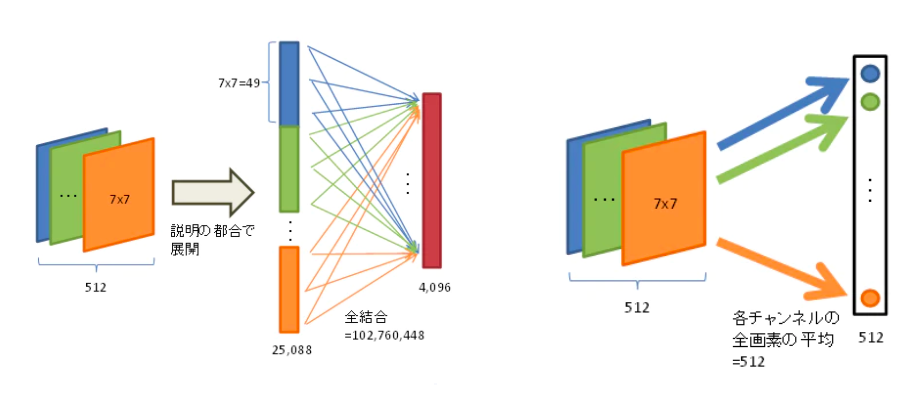
④Global Average Pooling(全体平均プーリング)
Global Average Pooling(GAP)は、ネットワークの最後の全結合層の代わりに取り入れられた手法になります。
各チャンネルの値の平均を算出することでパラメータ数を削減し、最後に全結合層に結果を渡していきます。フィルタ平均による出力により、過学習を抑制することができます。
出典:qiita
画像分類アーキテクチャ4:ResNet
ResNet(Residual Networks)は、ILSVRC2015の優勝モデルで152層で構成されるCNNになります。
勾配消失問題や劣化問題によって学習が進まない問題をResidual blockという手法を使って解決し、152層という非常に深い層を実現した表現力の高いネットワークと言えます。
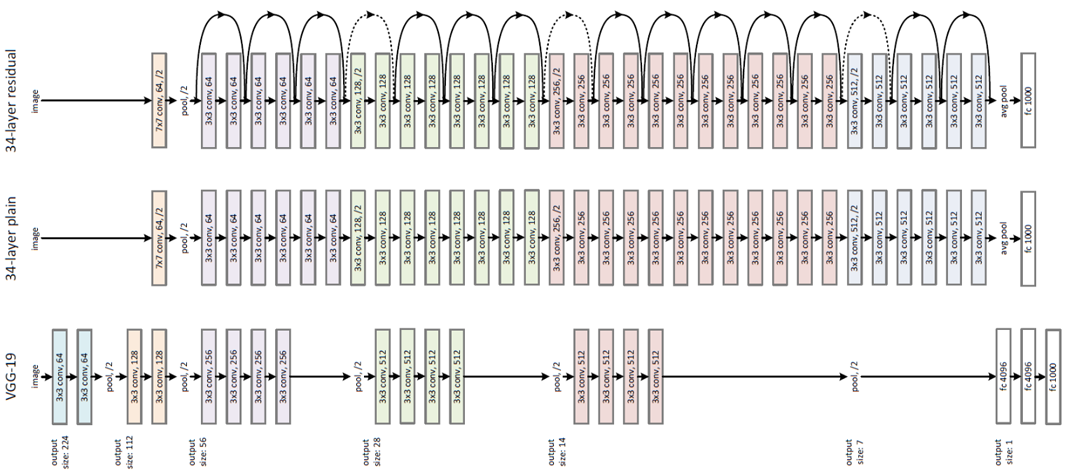
大きな特徴としては、先ほどのResidual Block(Shortcut Connectionを利用した残差ブロック)・Batch Normalization(バッチ正規化)が挙げられます。
まずはResidual Blockに使用されているShortcut Connectionという仕組みから見ていくことにしましょう。
Shortcut Connection
このShortcut Connectionは、ResNetのベースとなっており、勾配消失問題を解決するための仕組みになります。
通常、入力xに対の畳み込みを行って出力される関数H(x)を学習していきますが、層が深いと()との差がなくなってきます。Shortcut Connectionでは、この入力との差を、残差関数:Fx=Hx−xと置き、このFxを学習対象とする考え方を採用します。
このように残差関数を式変形すると、Hx=Fx+xとなり、xを足すという簡単な実装で実現できるというわけです。
変換が必要ない場合はFxの重みを0にし、小さな変換が求められる場合は差分を学習しやすくなります。
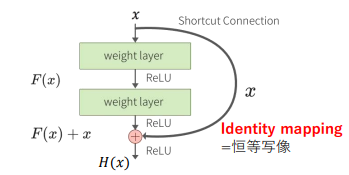
出典:deepage
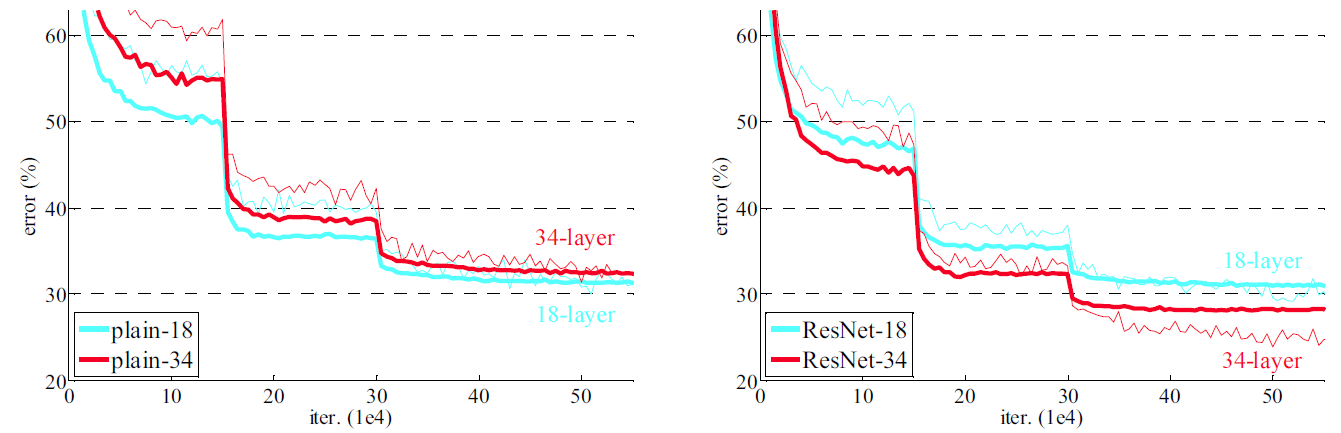
一般的に層を深くしていくことで、画像分類の精度は高まると言われています。
ただ、層が深くなるにつれて、精度が劣化していく問題も同時に生じてしまうトレードオフの関係にもなっています。そのため、単純に層を深くすれば良いというわけではありません。
このように、劣化問題 (degradation problem)とは勾配消失問題は起こっていないにも関わらず、層を深くした際に精度が劣化してしまう問題であるため、この問題を改善するために使用されているのがShortcut Connectionになります。
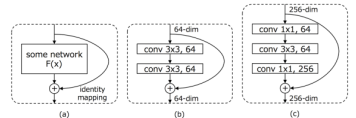
Residual block
Residual block(残差ブロック)とは、上記で見てきたShortcut connectionを使用し、層の入力を参照した残差関数を学習することで深いネッ トワークの学習を進みやすくしやすくする手法になります。
Planeアーキテクチャは、3 x 3 の2つの畳み込み層で構成されており、ResNet-18、ResNet-34のResidual blockとして使用されています。
ottleneckアーキテクチャは、1×1、3×3、1×1の3つの畳み込み層で構成されており、ResNet-50、ResNet-101、ResNet-152のResidual blockとして使用されています。
Batch normalization(バッチ正規化)
ResNetには、Residual blockの他に、もう一つの特徴がありました。それが、Batch normalization(バッチ正規化)です。
このバッチ正規化は、ミニバッチ学習をする際のデータの偏りなどによって入力の分布が大きく変化してしまい、学習が効率的に進まない内部共変量シフト (internal covariate shift:データの分布が訓練時と推論時で異なる状態) の問題を解決するための手法になります。
各レイヤが独立して学習が行えるようになるため、勾配消失や勾配爆発が起きづらく、学習が安定化・高速化が期待できます。
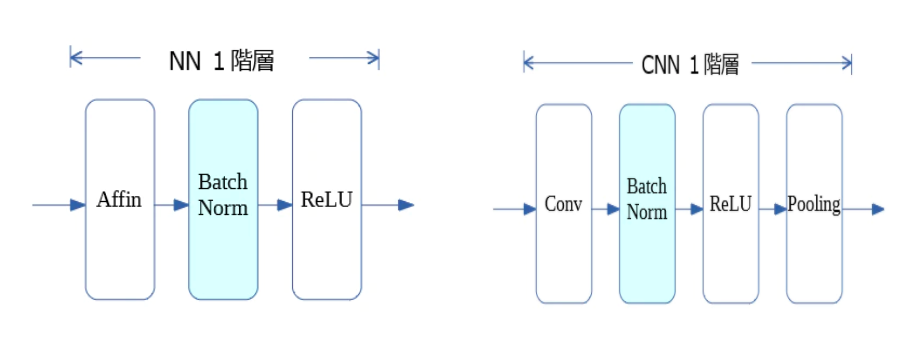
このBatch normalizationを行うタイミングは、全結合や畳み込みの後、活性化関数(ReLUなど)の前に行われます。ネットワーク構造の全体像を表す図では活性化関数と同様に記載を省略されることが多くなります。
ResNet以降のモデルでは、このBatch normalizationが標準的に用いられるようになりました。
メリットとしては、各ノードの値をミニバッチ単位で正規化することで、パラメータのスケールを揃えることができることが挙げられます。また、重みの初期値に注意を払う必要を抑え、正則化しても機能するため、L2正則化やDropoutの必要性が低下します。
画像分類アーキテクチャ5:DenseNet
DenseNetは、ResNetを改善したモデルになります。従来よりコンパクトなモデルになりますが、高い性能を持っているのが特徴です。
その仕組みに、ショートカット接続をたくさん入れている点が挙げられます。そうすることで、層と層の間の情報伝達をしやすくし、元の情報を加味しながら学習を進めることを可能にしました。
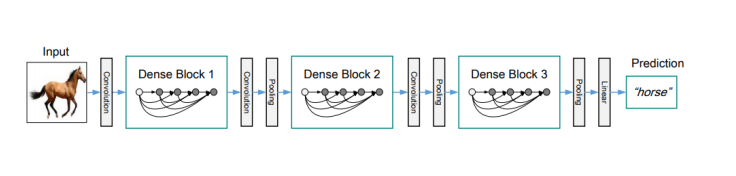
出典:arxiv
このように自身より前の層の出力を入力に含めて計算することで、層間が密(dense)になっていることから、DenseNetと呼ばれています。
その仕組みとして、
- Dense Block
- Transition Layer
が挙げられます。
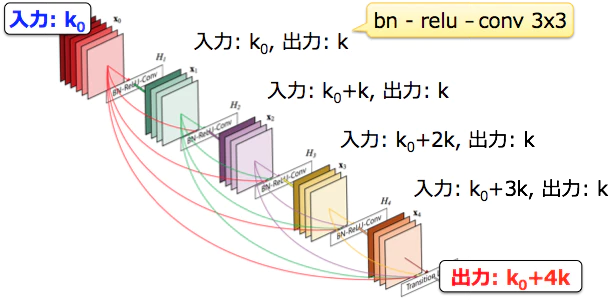
Dense Block
Dense Blockとは、前の層の出力全てを連結した特徴マップを入力としていく畳み込みのブロックのことです。
Dense Blockの中で増やすフィルターの数kは、成長率パラメータ(Growth rate)と呼ばれています。成長率はハイパーパラメータですが、 k=32に設定される事が多いです。
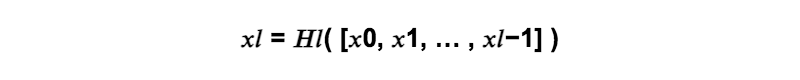
xl:第l層の出力
Hl:Batch normalization、ReLU、3×3 Convolution
※実際には、次元削減のためBottleneckを使用。
bn – relu – conv 1×1 – bn – relu – conv 3×3
Transition Layer
Transition Layerとは、Dense Blockで大きくなったチャンネル数を圧縮するダウンサンプリングの役割を持つレイヤーになります。1×1 Convolution、2×2 Average Poolingで構成されています。
このダウンサンプリングを行う層は重要な要素になるため、Dense Block間にPooling層を導入しました。
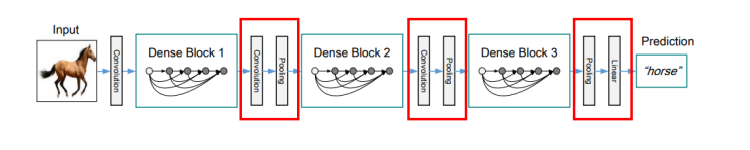
出典:arxiv
画像分類アーキテクチャ6:MobileNet
最後にMobileNetを見ていきましょう。このMobileNetは、モバイル端末でも使用できるほど計算量やメモリ使用量が小さく、精度と計算負荷のトレードオフを調整できるアーキテクチャになります。
VGG16と比べて学習速度:約3倍・モデルサイズ:約180分の1という結果も実現している優れモノです。
出典:harxiv
Depthwise Separable Convolution
計算負荷を抑制した仕組みにはDepthwise Separable Convolutionが使用されています。
Depthwise Separable Convolutionとは、畳み込み層をDepthwise Convolution (空間方向の畳み込み) とPointwise Convolution (チャネル方向の畳み込み:1×1 Convolution) に分解して計算することで、計算コストを下げることができる仕組みのことです。
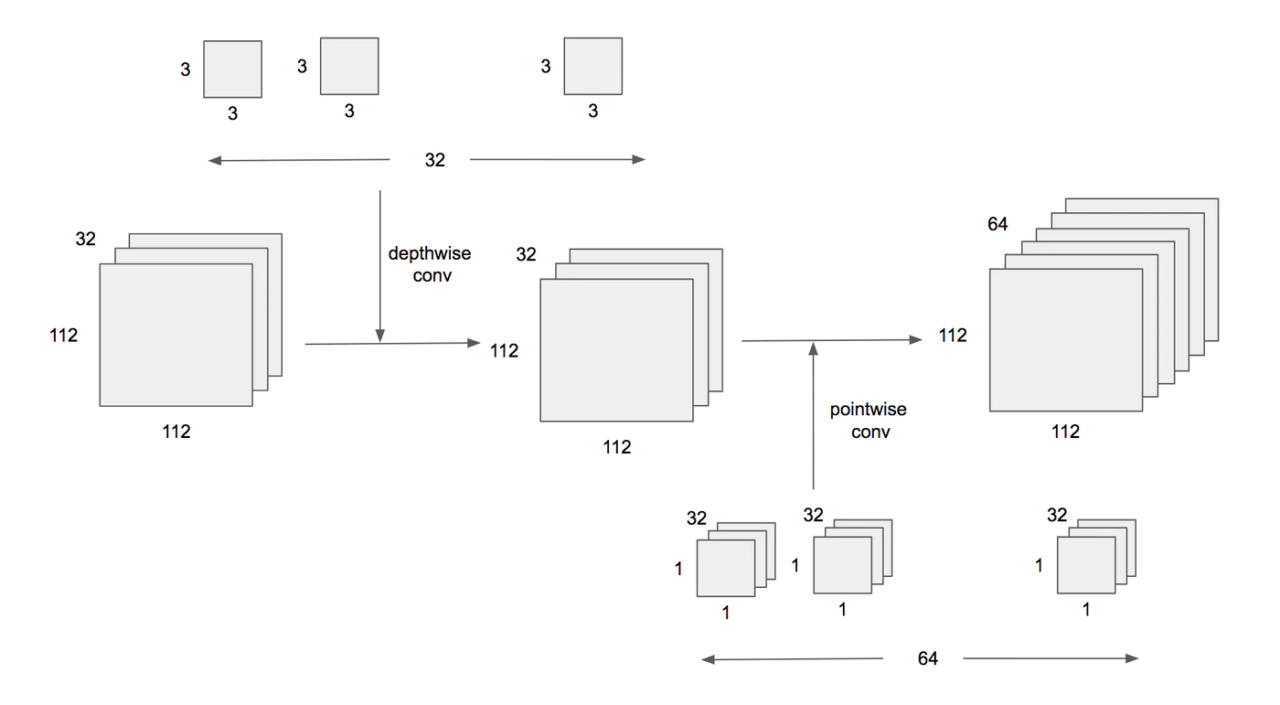
出典:qiita
(参考) Depthwise Separable Convolutionの計算量削減
入力の特徴マップのサイズをDF・DF・M、出力の特徴マップのサイズをDF・DF・N、カーネルのサイズをDK・DK・M・Nとします。
- 通常の畳み込みの計算コスト
DK・DK・M・N・DF・D = DK^2MNDF^2 - Pointwise convolutionの計算コスト
※空間方向の畳み込みを行わないため、DK = 1
M・N・DF・DF=MNDF^2 - Depthwise Separable Convolutionの計算コスト
DK^2NDF^2 + MNDF^2 = DK^2 + MNDF⇒ 通常の畳み込みとDepthwise Separable Convolutionの計算量を比較
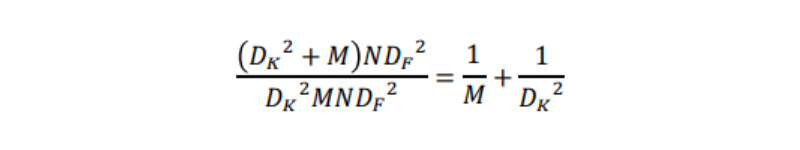
例えば、入力の特徴マップのチャンネル数M = 32、カーネルサイズDK = 3とすると、約9倍ほど計算コストが下がったといえます。
出典:qiita
冒頭で、精度と計算負荷のトレードオフを調整できると言いました。
このMobileNetは、αとρという二つのハイパーパラメーターを調整することにより、ネットワークの深さなどを調整しなくても、精度(Accuracy)と負荷のトレードオフを調整することができます。
まず、Width Multiplier(α) は、チャンネル数を制御するパラメータになります。
1.0が基本の値で、0.0に近づけていくほど精度が下がり、代わりにパフォーマンスが高まります(下図 Table6)。値を小さくすることで計算量・パラメーター数共に少なくなります。
次にResolution Multiplier(ρ)ですが、こちらは入力画像サイズを制御するパラメータになります。Width Multiplier(α)と同様に、1.0が基本の値で、0.0に近づけていくほど精度が下がり、代わりにパフォーマンスが高まります。
一方、値を小さくして計算量は少なくなるが、下図(Table 7)のようにパラメーター数は減らないのがWidth Multiplier(α)との違いになります。
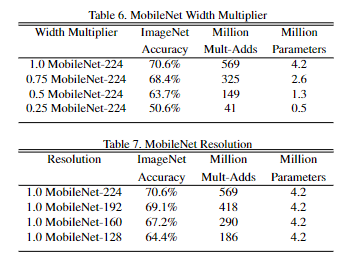
出典:arxiv
まとめ
さて、いかがだったでしょうか。これまで6つのアーキテクチャをご紹介させていただきました。
まずは、ILSVRC2012で優勝したAlexNetでした。このモデルによって、ディープラーニングが一躍脚光を浴びることとなりました。
続いて、このAlexNetよりも層を深くしたVGGやGoogleNetが登場し、記録を向上させてきました。
さらに層を152層に深くしさらに勾配消失も抑制したResNet、そのResNetを改良しより高い精度を持つDenseNetが登場していきました。
最後のMobileNetは、現在ではVersion3まで開発されているモバイル端末でも使用されているモデルでした。
以下は、6つのアーキテクチャを簡単にまとめた表ですので、参考にしてみてください。
【画像分類における代表的な6つのCNNネットワーク】
| CNNネットワーク名 | 概要 |
|---|---|
| AlexNet | 2012年のILSVRCの優勝モデル。 |
| VGG | 2014年のILSVRCの2位のモデル。 |
| GoogleNet | 2014年のILSVRCの優勝モデル。22層で構成されるCNN。 |
| ResNet | 2015年のILSVRCの優勝モデル。152層で構成されるCNN。 |
| DenseNet | ResNetを改善したモデル。 従来よりコンパクトなモデルだが、高い性能を持つことが特徴。 |
| MobileNet | 計算量を軽減した軽量なモデル。 |






