
さて今回は、画像セグメンテーションにおける代表的な3つのアーキテクチャの特徴についてご紹介していきます。
画像セグメンテーションとは、一言で言えば「領域ごとに分割された画像のクラスは何か」を識別することです。
それぞれの画像領域が、どのクラスに該当するのかを予測していくことになります。
視覚的に把握しやすいので、まずはセグメントされた画像を参照しながら、画像セグメンテーションとは何かを見ていきましょう。
その後で、実際にどのような仕組みによって画像の領域が分割されていくのかを3つのアーキテクチャを元に見ていくことにします。
画像セグメンテーション
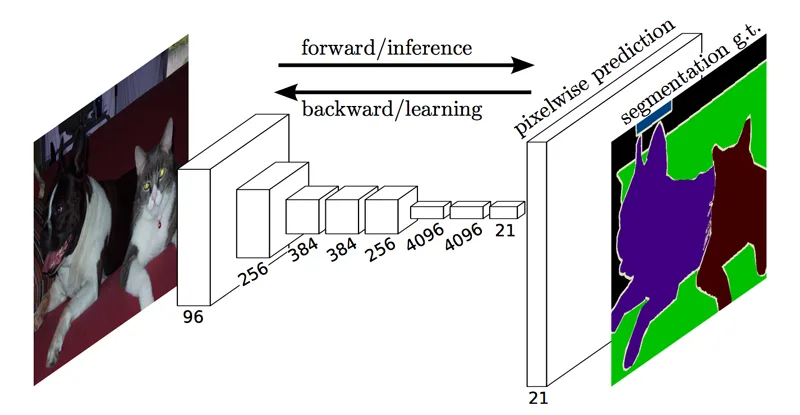
それでは、さっそく画像セグメンテーションについて見ていきましょう。
画像セグメンテーションは別名、セマンティックセグメンテーションとも呼ばれています。
画像の中でどの領域が何のクラスに分類されるかを、ピクセル単位で分類する手法になります。
そのため、Pixel-labelingとも呼ばれています。
このセマンティックセグメンテーションでは、ニューラルネットワークの出力ユニット数が、画像サイズ×分類クラス数となります。
ピクセルごとにラベル付けされた教師データを与えて学習することで、入力画像の各ピクセルがどのクラスに分類されるかの確率を出力できるようになります。

上図のようにいくつかの色分けがされており、視覚的な把握がしやすい画像になっているのが分かるかと思います。
このように、その領域が何を示しているのかというクラス分けをピクセル単位で分割していきます。
では、続いて以下の3つのアーキテクチャを見ていくわけですが、それぞれの構造やその意味に注目しながら画像セグメンテーションについて深堀りしていきましょう。
- FC
- SegNet
- U-Net
①FCN
まずは、FCNと呼ばれるアーキテクチャです。
FCN (Fully Convolutional Network)とは、畳み込み層とプーリング層で構成される(全結合層を持たない)アーキテクチャになります。
任意のサイズの入力画像からセマンティックセグメンテーションを行えるのが特徴です。
畳み込みを行って得た特徴マップをヒートマップ化していき、さらに逆畳込みすることによって、アップサンプリングして予測していきます。
FCNの欠点としては、フィルターサイズにより、大きさがマッチしない(特に大きい)対象物についてはうまく認識・分類ができない点が挙げられます。
出典:https://blog.negativemind.com/wp-content/uploads/2019/03/002l.jpg
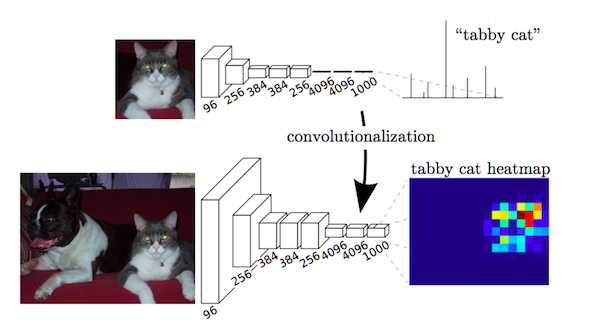
ヒートマップ
ヒートマップとは、画素ごとにセグメンテーション結果を可視化したものです。
FCNでは、一般物体認識のCNN(論文ではVGG-16)の全結合層を、Global Average Poolingと1×1 Convolutionに置き換えることによって、クラス分類の結果を下図のような2次元のヒートマップとして出力されるようになります。
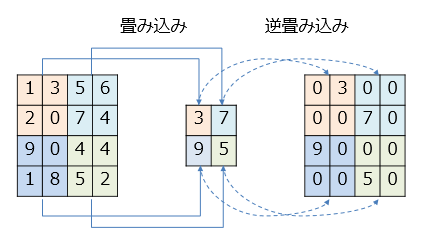
逆畳み込み(Deconvolution)
プーリングによって出力されるヒートマップは小さくなるため、小さい画像のアップサンプリングを行います。
この際に使用されるのが逆畳み込み(Deconvolution)になります。
畳み込み(convolution)の逆プロセスではないことに注意してください。
そのため誤解を生まないようup convolution・transposed convolutionなどとも呼ばれています。
逆畳み込みのパラメータには、kernel size・padding・stride + pixel数があります。
まず、特徴マップの各pixelをstrideで指定したpixel数ずつ空けて配置していきます。
次に、kernel size-1だけ特徴マップの周囲に余白を取ります。
最後に、paddingで指定されたpixel数だけ余白を削り、畳み込み処理を行っていきます。
特徴マップ
アップサンプリングで単純に入力画像と同サイズに拡大すると、物体の境界がぼやけます。
最終層の特徴マップから順にアップサンプリングで前の層と同サイズに拡大し、チャンネルごとに足し算しています。
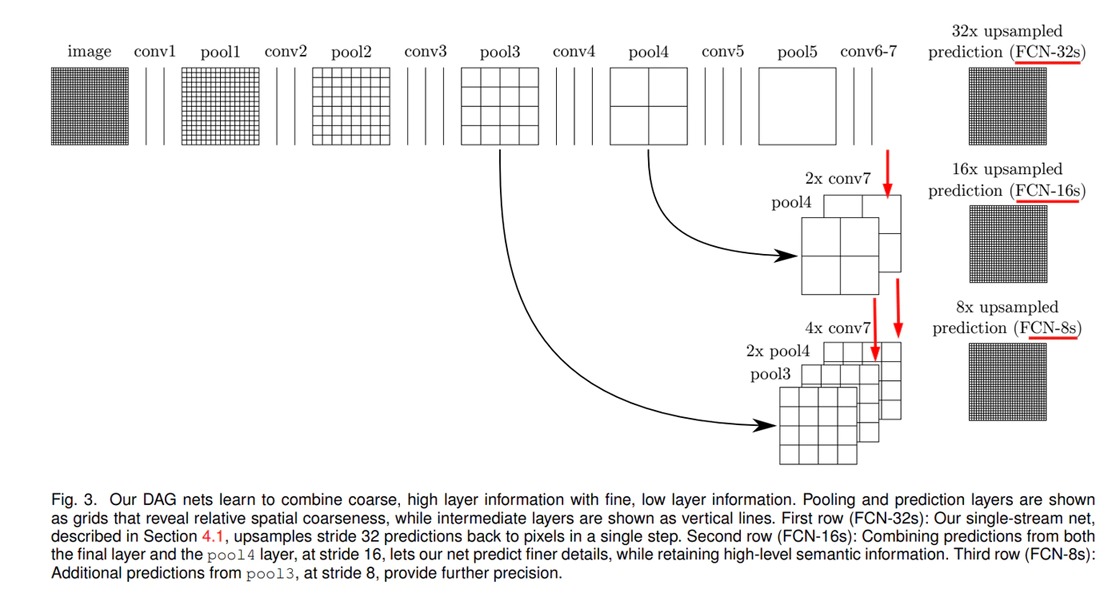
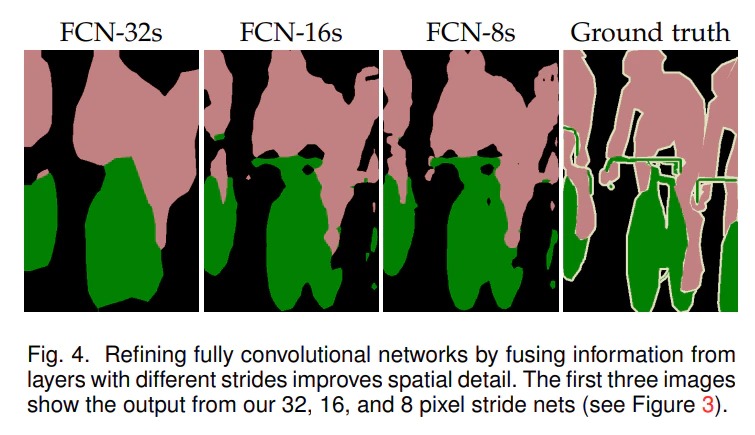
出典:https://qiita.com/minh33/items/6e42041dd5108d5fc2f0
②SegNet
SegNetとは、Encoder(エンコーダー)とDecoder(デコーダー)で構成されているアーキテクチャになります。FCNよりも多くの特徴マップを利用していますが、エンコーダーの特徴をコピーせず、Maxプーリングからのインデックスをコピーすることでメモリ効率を上げています。
SegNetの欠点としては、EncoderとDecoderが直列に接続されているため、特徴が伝搬する過程でピクセルの詳細情報が失われてしまい、元の画像に対してセグメンテーション(Segmentation)結果が粗くなりやすくなる点です。
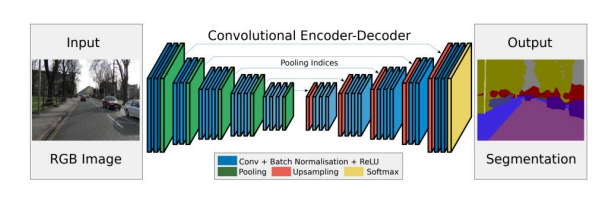
上記のように、EncoderとDecoderで構成されるモデルをEncoder-Decoder構造と言います。
この構造は、画像セグメンテーションに特化したディープラーニングで広く使用されているモデルになります。
ではそもそも、このEncoder-Decoder構造とは一体どのようなモデルなのでしょうか。詳しく見ていきましょう。
Encoder-Decoder構造
まず、Encoderとは、次元を圧縮していく(ダウンサプリング)ことにより、入力された画像から特徴マップを抽出することです。
その抽出した特徴マップを元の次元に復元(アップサンプリング)していくのですが、この特徴マップと元画像のピクセル位置の対応関係をマッピングしていくことをDecoderと言います。
Encoderでは、プーリング層によりmax-pooling indexとして大まかな位置記憶しておきます。
そしてDecoderで、特徴マップをそのindex位置にアップサンプリングしていき、逆畳込みを行います。そのため逆pooling(unpooling)とも呼ばれています。
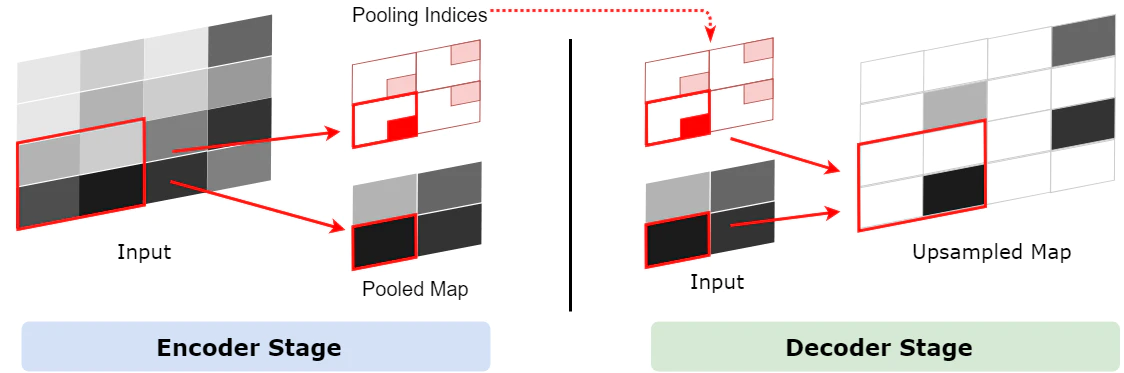
出典:https://qiita.com/cyberailab/items/d11862852eccc17585e8
③U-Net
U-Netは、畳み込み層とプーリング層で構成されるアーキテクチャで、学習に使う画像の数が少なくてもセグメンテーションの精度が良いモデルです。
学習および学習後の処理が高速なのが特徴のアーキテクチャとなります。
ネットワークの形がU字型に見えるので、U-Netと呼ばれています。
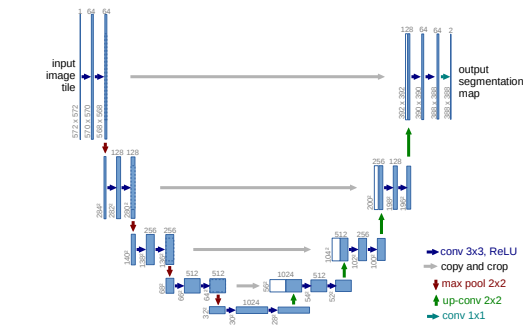
出典:https://arxiv.org/pdf/1505.04597.pdf
※論文のネットワークは、電子顕微鏡に写った細胞かそうでないかを分類する2クラス分類です。
スキップ接続
スキップ接続は、Encoderの各層で出力される特徴マップをDecoderの対応する各層の特徴マップに連結 (concatenation)する手法になります。
スキップ接続の目的は、小さくなった特徴マップでもDecoderに直接連結することで情報の保持をなるべく抑制することです。
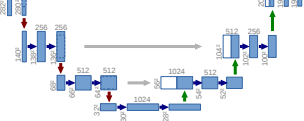
Encoderではpadding=0の畳み込みを行って特徴マップが少しずつ小さくなっているため、 Encoderの特徴マップの中央部分を切り出して、Decoderの特徴マップとサイズを一致させて連結しています。
Encoderで出力された特徴マップを、別チャンネルとしてDecoderの特徴マップに追加する形で連結しています。
まとめ
さて、如何でしたでしょうか。
これまで3つのアーキテクチャをご紹介させていただきました。
まず画像セグメンテーションとは、画像の中でどの領域が何のクラスに分類されるかを、ピクセル単位で分類する手法でした。
視覚的な把握がしやすいのが特徴です。
この画像セグメンテーションが、どのような仕組みになっているのかを、「FCN」「SegNet」「U-Net」の3つのアーキテクチャを元に解説してきました。
以下にこれらをまとめた表を用意しましたので、参考にしてみてください。
画像セグメンテーションのアーキテクチャ一覧
| 用語 | 概要 | 特徴 |
|---|---|---|
| FCN | 畳み込み層とプーリング層のみで構成されるアーキテクチャにより、任意のサイズの入力画像からセマンティックセグメンテーションを行える。 | ヒートマップ 一般物体認識のCNNの全結合層を、Global Average Poolingと1×1 Convolutionに置き換えることによって、クラス分類の結果が2次元ヒートマップとして出力されるようになる。 逆畳み込み(Deconvolution) プーリングによって出力されるヒートマップは小さくなるため、小さい画像のアップサンプリングを行う。 この際に使用されるのが逆畳み込み(Deconvolution)。 特徴マップの利用 アップサンプリングで単純に入力画像とどうサイズに拡大すると、物体の境界がぼやける。 最終層の特徴マップから順にアップサンプリングでの前の層と同サイズに拡大し、チャンネルごとに足し算している。 |
| SegNet | セマンテックセグメンテーションのエンコーダー・デコーダーアーキテクチャ。 | FCNよりも多くの特徴マップを利用しているが、エンコーダの特徴をコピーせず、Maxプーリングからのインデックスからコピーすることでメモリ効率をあげている。 |
| U-Net | 畳み込み層とプーリング層で構成されるアーキテクチャで、ネットワークの形がU字型に見えるのでU-Netと呼ばれる。 | スキップ接続 Encoderの各層で出力される特徴マップをDecoderの対応する各層の特徴マップに連結(concatenation)する手法。 |






