
今回ご紹介していくのは、「教師データ」とは何か?また、それに付随した機械学習に必要なデータ作成方法についてです。
機械学習を実施する際には、この「教師データ」と呼ばれるデータが必要なのですが、このデータが具体的にどのようなデータなのか?また、機械学習に必要な教師データのようなデータをどのように作成していくのか?をこれから見ていきます。
教師データとは
まず初めに教師データとは、AIが学習していく際に必要なデータのことです。「あるデータが入ると、これが答えです」というように、データのラベル、つまりデータに対する正解を用意する必要があります。
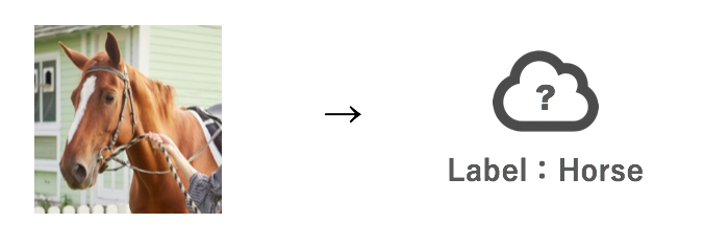
下図を例にとると、「一枚の馬の画像に対して、これは馬ですよ」という1つのラベル(正解)を付与していきます。
このように、データとその答えが常に静的に決められているものを「教師データ」と言います。
この教師データを、機械学習の実施において必要十分な量を用意して学習させていくことで目的に応じたAIモデルを作成することができます。
「教師データ」のイメージ図
機械学習に必要なデータ作成方法
続いてこのデータをどのように作成していけば良いのかを順を追って見ていきたいと思います。
上述したように、機械学習を実施していく前に行っていくのが、その学習に必要な「教師データ」なのですが、その作成方法を見ていきます。
①学習分類を決める
まず最初に、学習分類を決めていきます。学習分類を決めるとは、どのようなタスク(課題)を解決するAIを作るのかを決めるということです。
一般的に “AIが何でもかんでもやってくれる” と思われがちですが、この学習分類を決めていくのは人間の仕事になります。
この学習分類には、教師あり学習・教師なし学習・強化学習と大きく3種類あります。また教師あり学習には、クラス分類と回帰があり、教師なし学習には、クラスタリングと異常検知というタスクがそれぞれあります。
このように学習分類には、さまざまな種類があり、どのようなタスクを解決したいのかによってこれらの学習分類を選んでいきます。
クラス分類
与えられたデータが、どの分類(カテゴリー)に当てはまるのかを識別する学習方法
回帰
さまざまな関連性のある過去の数値から未知の数値を予測する学習方法
クラスタリング
未知の集合を、いくつかの集まりに分類させる学習方法
異常検知
正常な行為を学習し、それと大きく異なるものを異常として識別する
強化学習
実際に行動した際に得られる報酬を計算し、未来の価値を最大化する学習方法
②データの収集と整理
①でどのようなタスクを解決したいのかが明確になったあとは、そのタスクを解決させるためのデータの収集・整理をしていきます。
この工程も人間が行っていく仕事になります。
まずは、とにかく一回データを集めましょうということで、データの収集をしていきます。
世の中にあるデータには、「プライマリーデータ」と「セカンダリーデータ」と大きく二つあります。多くの場合、これらを上手く組み合わせてデータを収集していきます。
プライマリーデータ
自ら企画して集めたアンケートや自社の売上情報など
セカンダリーデータ
自ら企画して集めていない公的な統計データや新聞記事など
たとえば、自社の売上情報(プライマリーデータ)に、天気の情報(セカンダリーデータ)を追加したデータのようにさまざまな種類のデータを混ぜ合わせたデータを収集していきます。
このように一見関係のないようなデータを組み合わせることによって、より中身のある意味をもった情報になります。

続いて、収集されたデータの整理をしていきます。
通常この工程のことを「データの前処理」と言います。
データの前処理とは、機械学習の前に行うもので、収集したデータを学習しやすいようにデータを整えていくことです。
以下に、「データの前処理」の一例を挙げてみます。
標準化、正規化
データの数値を一定のルール(0〜1の値など)に基づいて値を変形する手法
One-Hotエンコーディング
数値ではないデータを数値(0, 1)で表現する手法
欠損値、外れ値の処理
何らかの理由により、データ内にある欠落している部分やデータ内の値から大きく外れ値に対して、その値を補完や削除していく手法
次元削減
学習に使用するデータの情報を、可能な限り状態を維持したままそのデータを説明する次元を削減する手法
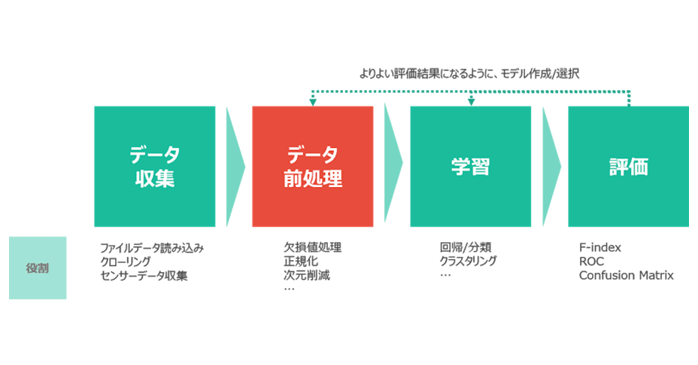
参照:https://cdn-ak2.f.st-hatena.com/images/fotolife/i/imslotter/20010201/20010201072310.png
このデータの前処理は非常に重要な作業で、AIの作成手順の8~9割の時間を割くこともあります。
ただ、Gabage in Gabage out(ゴミのようなデータを入れたらゴミのようなAIしかできない)という言葉もあるくらい、きちんと整理されたデータが非常に重要になります。
このように、AIは自動的に出来上がるものではなく、多くの手間をかけて開発する必要があります。
その中で特に重要な工程が、このデータの前処理となります。
③アノテーションの付与
データの収集・整理を終えたあとは、下図のように、一枚の馬の画像に対して、これは馬ですよという1つのラベルを付与していきます。
このように、画像を見てどのカテゴリーに当てはまるのかを基本的に人間の手で判別していきます。
データアノテーションの需要が高まっている現在では、この工程を円滑に進めるためのサービス「Appen(アッペン)のデータアノテーション代行サービス紹介」などもあるので、ぜひ参考にしてみてください。
まとめ
ここまで如何だったでしょうか。上述したように、機械学習を実施していく際に必要不可欠なのが、「教師データ」というものです。
このデータとその答えが常に静的に決められている「教師データ」は、収集したデータに対してアノテーション(上図のように、ある画像に対する正解)を付与していくことで作成することが出来ます。
世の中に出回っているデータの全体像を把握することで、何の変哲もないデータが価値のあるデータとして活用できるデータへと変貌していきます。
このデータを使用して機械学習を行ったAIは、望んでいるようなタスクの解決をしてくれることでしょう。






