今回は、AI(人工知能)の一つ、機械学習においてとても有名なアルゴリズムを紹介したいと思います。機械学習を行う上で、SVM(Support Vector Machine)はデータの分類をするためにも重要な手法です。
今回はそんなSVMのメリットやデメリットに加えて、実装方法について徹底解説します!
SVM(サポートベクターマシン)とは?
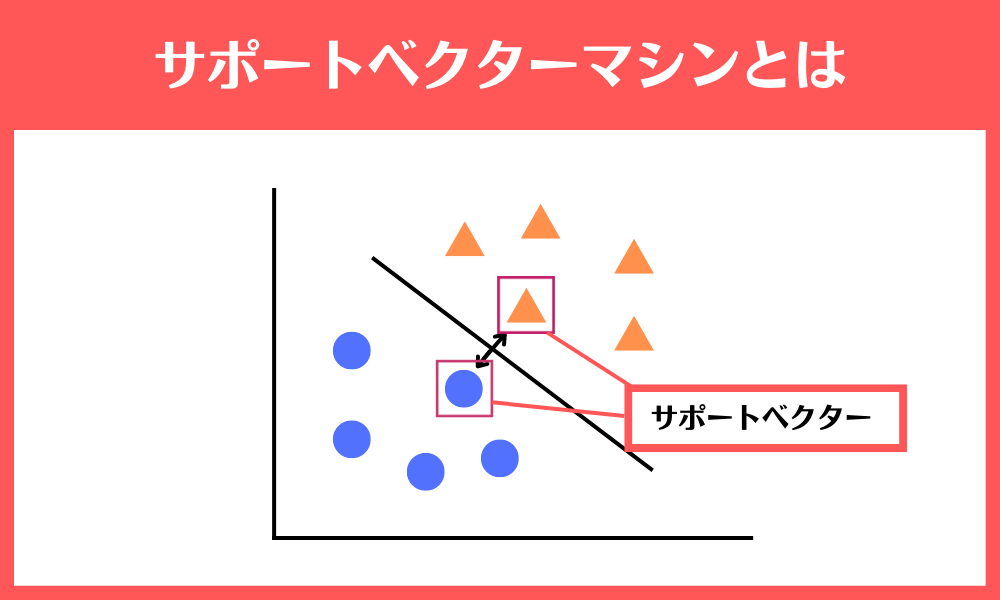
SVMは、教師あり学習のクラス分類と、回帰のできる機械学習アルゴリズムです。
それぞれSVC(Support Vector Classification)、SVR(Support Vector Regression)と書かれることもあります。
SVMは、少ない教師データで高い汎化性能を持てることが特徴で、計算も早く過学習も起こしづらいです。使い勝手が良いため、今でも様々な分野で活用されているアルゴリズムです。
ただし、データがばらついたり偏ると、計算量が膨大になったり(次元の呪い)、学習が非常に非効率なため、データのサンプル数が多い場合(100,000サンプル以上)はメモリ使用量や実行において難しくなるデメリットがあります。
SVMの仕組みってどんな?
SVMは、パーセプトロンに
- カーネル関数
- マージン最大化
を加えて次元を増やすことで、非線形の分割を線形に分割できるようにしているアルゴリズムです。SVMを解説していく上で、「カーネル関数」と「マージン最大化」は重要な概念です。
境界に最も近いサンプルとの距離(マージン)が最大となるような超平面で分離する計算をしています。言葉だけで説明していると難しいと思いますのでひとつずつ紐解いていきましょう。
線形のモデルの解決方法
下に用意した図を観てください。 図にプロットしてあるオレンジの点と青い点を分類する問題があると考えてください。
これらの点を学習することで、いい感じにオレンジと青を分類できるようになったモデルは、新しい点が打たれた際にその点が青なのかオレンジなのかを当てることができるようになるはずです。
この考え方が、基本的なクラス分類問題の考え方です。
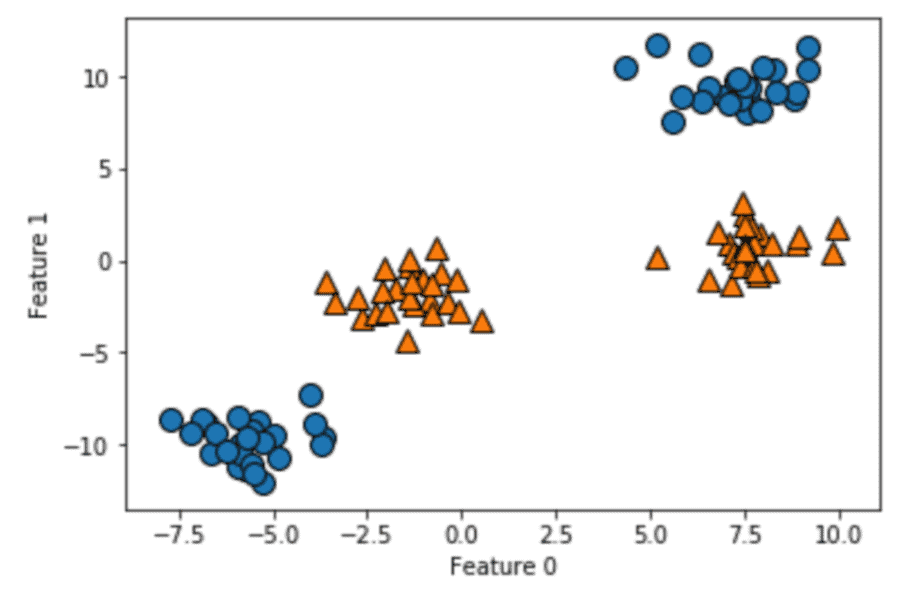 一番シンプルな分類問題の解決方法は、線形モデルと言われるものです。線形モデルはこの2つの点を分類するのに、直線を引くことで分けようとすると思ってください。
一番シンプルな分類問題の解決方法は、線形モデルと言われるものです。線形モデルはこの2つの点を分類するのに、直線を引くことで分けようとすると思ってください。
データ分類のために線を引けば、分類線以上のデータと分類線以下のデータに分類することができます。
単純に分類すべきデータが2つに分かれていれば線形分離は容易にできます。しかし、今回のデータでは直線では分離することはできません。
なぜなら、無理に線を引こうとすると図の通り、青い丸とオレンジの三角のいデータに被ってしまうからです。
無理やり線を引いても、オレンジと青は分離できません。 このことを、「線形分離できない」といいます。 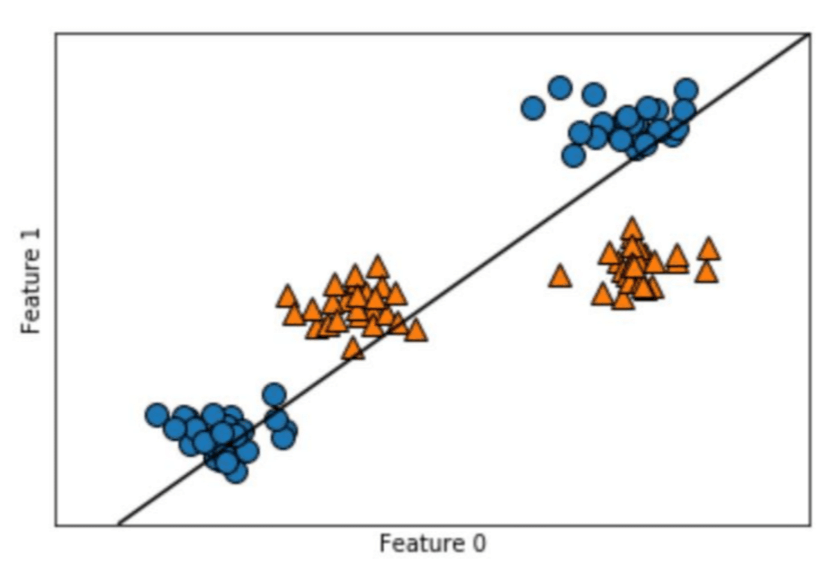
そこで、このような分離をうまくできるように、まず「カーネル関数」という考え方が使われます。
カーネル関数とは
カーネル関数とは、非線形の特徴量をデータ表現に加えることで次元を増やし、分離をする際に使用されるアルゴリズムです。入力の特徴量を拡張する意味で、2番めの特徴量の2乗を新しい特徴量として加えてみます。
先ほどまで平面でしか表現できなかったデータが、立体的に表現できるようになりました。
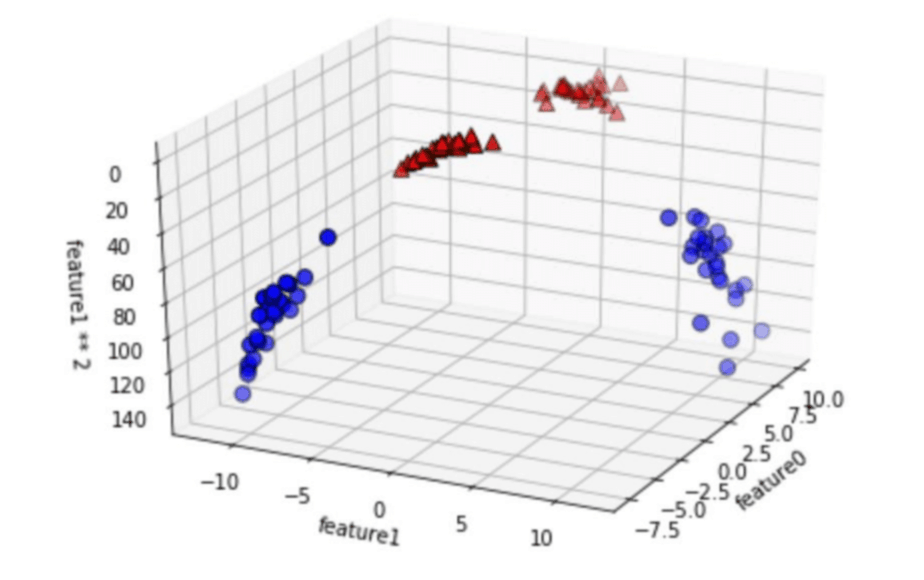
以下の図を確認してください。
こうすると、先程まで直線によって分離できなかった問題が、「平面」によって分離できるようになります。 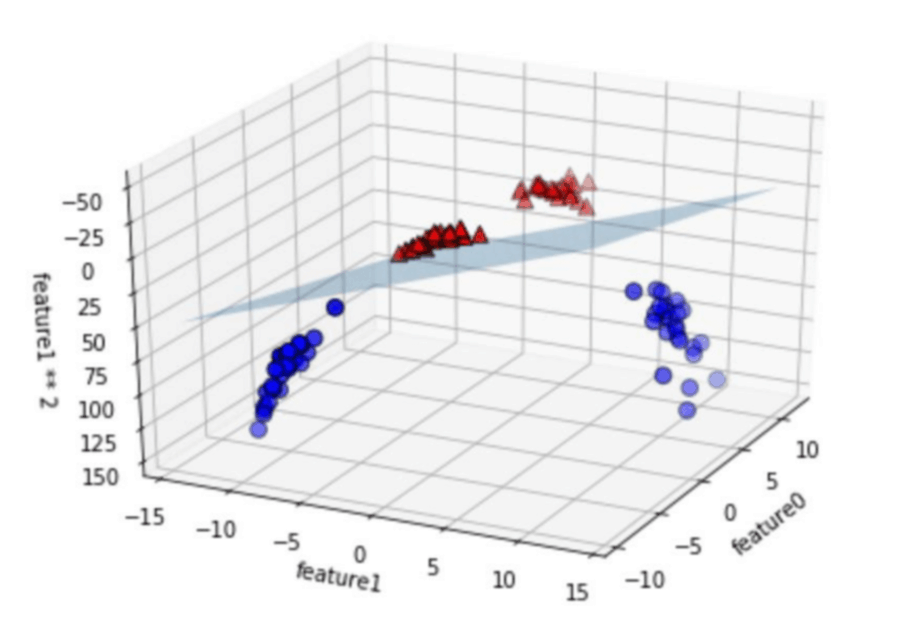
このように、入力特徴量の次元を増やして線形分離できるようにしたのが、SVMの基本的な考え方です。
このカーネル関数を適用すると、平面では線形分離できなかったデータが線形分離できるようになります。
しかし、カーネル関数を導入すると、実際にデータポイントの拡張を計算し始めますので、高次元で計算量が多くなりすぎる問題が発生します。
そのため、数学的に解決するカーネルトリックという手法が用いられる事が多いです。
Scikit-learnを使った、SVMのプログラミング方法について学びたい方には、AIエンジニア講習がおすすめです。
マージン最大化とは
SVMのもう一つの特徴、「マージン最大化」についてもご紹介しておきましょう。例えばこのようなデータを赤と青の点に分けることを考えます。
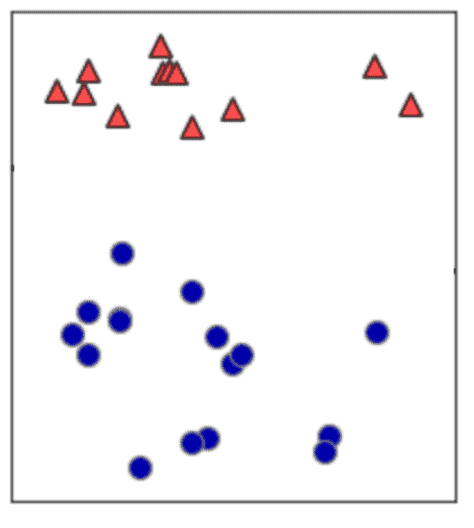
直線の引き方は、幾通りも考えられるのがおわかりいただけますでしょうか。どちらの線でも、2つの点を分類できています。 つまり、データを分類できる線形は幾通りも引けてしまうのです。
場合によっては、三角のデータに近い線が引けてしまいますし、逆に丸のデータに近い線も引けてしまいます。そうなると、データに偏りができてしまいます。
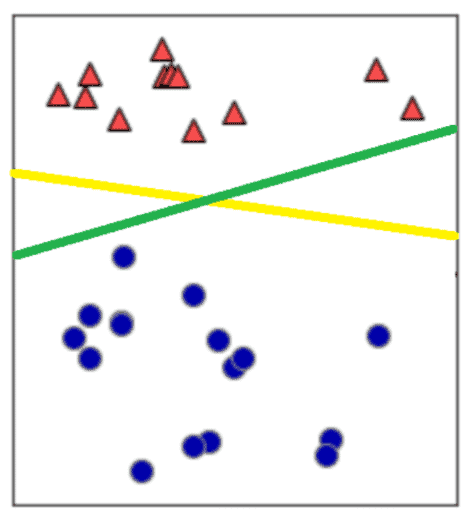
マージンとは
最終的にほしい分離の線は、「新しい青または赤の点が入力されたときに、正しく(汎用的に)赤か青かを分類できる線」ですので、どちらのほうがいい線なのかを考える必要があります。
このときに使われるのが、「マージン」という考え方です。マージンとは、線形分離する線からそれぞれのデータまでの距離です。
このマージンが最大化するように分離の線を決めることをマージン最大化と呼びます。
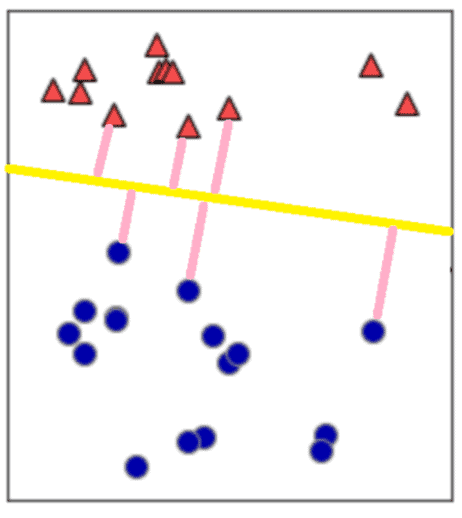
ちなみに、一番近いデータ点を「サポートベクトル」と言います。
このような考え方で分離が行われるため、ディープラーニングで使われるニューラルネットワークに比べると、少ないデータでも汎用性が高い、つまり汎化性能が高いモデルができるのがSVMの特徴となっているのです。
SVMの特徴や考え方を簡単に解説している動画もありますのでぜひ参考にしてください。
SVM(サポートベクターマシン)のメリット

SVMはその高い汎化性能と柔軟性から、さまざまな分野で利用されています。その具体的なメリットを以下に詳しく解説します。
高い汎化性能
SVMは、少ない学習データでも新しいデータに対する予測精度が高く、過学習を防ぐ構造を持っています。特に医療分野での疾患分類や金融分野でのリスク予測など、限られたデータから高い精度を要求されるケースで効果を発揮します。
過学習のリスクが低い
モデルの複雑性が制限されるため、過学習のリスクが低く抑えられます。この特性により、データ分布が単純な場合やノイズの少ないデータセットで特に安定したパフォーマンスを示します。
非線形データへの対応力
カーネル関数を利用することで、非線形なデータを高次元空間にマッピングし、線形的に分離可能にします。この仕組みにより、複雑なデータ構造でも柔軟に対応でき、画像認識や音声分類などの分野で活用されています。
分類と回帰の両方に対応可能
SVMは、分類(SVC)だけでなく回帰分析(SVR)にも使用できます。そのため、二値分類や多クラス分類に加えて、連続値の予測問題にも適用できる柔軟性を持っています。
多様なカーネル選択
線形カーネル、RBFカーネル、ポリノミアルカーネルなど多様なカーネル関数を選択できるため、さまざまなデータセットや問題に適応できます。特定の課題に最適なカーネルを選択することで、SVMの性能を最大限に引き出すことが可能です。
SVM(サポートベクターマシン)のデメリット

SVMは多くのメリットがある一方で、利用時に注意すべきデメリットも存在します。これらを理解し、適切な対策を講じることが重要です。
計算コストが高い
サンプル数が多い場合や次元が高い場合、計算負荷が急激に増加します。これにより、大規模データセット(例:数百万件以上)では、学習時間が長くなりすぎる、あるいはメモリ不足が発生することがあります。この課題を解決するために、次元削減手法やサブサンプリング技術の併用が推奨されます。
適切なカーネル選択が必要
SVMの性能は使用するカーネル関数に大きく依存します。誤ったカーネル選択は学習精度の低下につながり、試行錯誤が必要です。さらに、カーネルトリックを適用する際には、データ特性に関する十分な理解が求められるため、初心者には難易度が高い場合があります。
ハイパーパラメータ調整の難しさ
GammaやCといったハイパーパラメータの調整が必要で、これらの値を適切に設定しないとモデルの性能が低下します。GridSearchCVやランダムサーチといった手法を用いて最適値を探索するのが一般的ですが、試行回数が多くなると計算コストが増加します。
次元の呪い
データが高次元になると、次元の呪いによってモデルの性能が悪化する可能性があります。具体的には、高次元空間ではデータが希薄になるため、距離や分離基準が曖昧になりがちです。これを解決するために、主成分分析(PCA)や独立成分分析(ICA)などの次元削減手法を活用することが推奨されます。
解釈の難しさ
モデルの構造がブラックボックス化しやすく、学習結果の解釈が困難です。特に、ビジネス応用や規制が厳しい分野では、結果の説明可能性が重要視されるため、他のアルゴリズム(例:決定木)と比較して不利になる場合があります。
SVMのプログラミング方法が学べるおすすめセミナー
「AIエンジニア講習」は、Scikit-learnを使ったSVMのプログラミング方法を学べ、AIプログラミングを習得できる、AIエンジニア育成セミナーです。
いつでもどこでも学習できるパソコン、スマホ、タブレット対応のEラーニング学習の為、自分の都合の良いペースで取り組めます。
内容は、今回の記事でご紹介するScikit-learnを使ったSVMのプログラミング方法はもちろんのこと、AI基礎知識から、実務で使えるAIの実装技術と活用術までをも習得できるおすすめのセミナーです!
もちろん非エンジニアの方でも、ゼロからプログラムの実装方法を学ぶことができます。
| セミナー名 | AIエンジニア育成講座 |
|---|---|
| 運営元 | GETT Proskill(ゲット プロスキル) |
| 価格(税込) | 45,100円〜 |
| 開催期間 | 2日間 |
| 受講形式 | 対面(東京・名古屋・大阪)・ライブウェビナー・eラーニング |
Scikit-learnでSVMを実装する方法
ここからは、Scikit-learnで実際にSVMを試してみましょう。インストールがまだの方は、インストールしてみてください。 Pythonの機械学習ライブラリなので誰でも無料で利用可能です。
Pythonの機能を把握したい場合は、以下の記事を参考にしてください。
ディープラーニングをPythonでプログラミングする方法を徹底解説!
ステップ①Scikit-learnで新しいプロジェクトを作成
[Create New Project]で、新しいプロジェクトを作成します。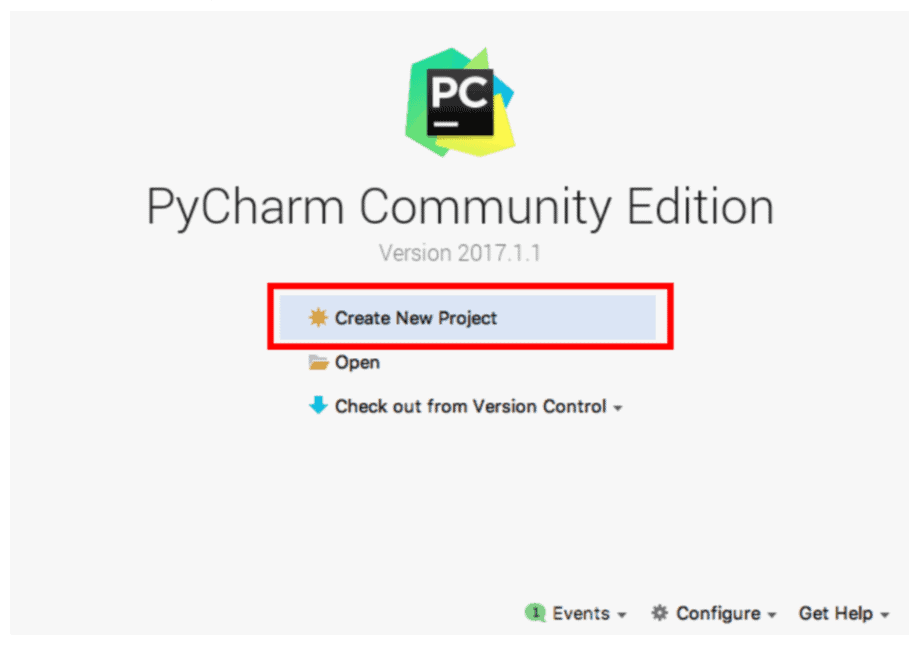
Locationに「opencv」と入力し、[Create]をクリックします。Pycharmでは、プロジェクトという単位でプログラムを管理することができます。
プロジェクトは、指定したLocationのディレクトリに作られたフォルダです。
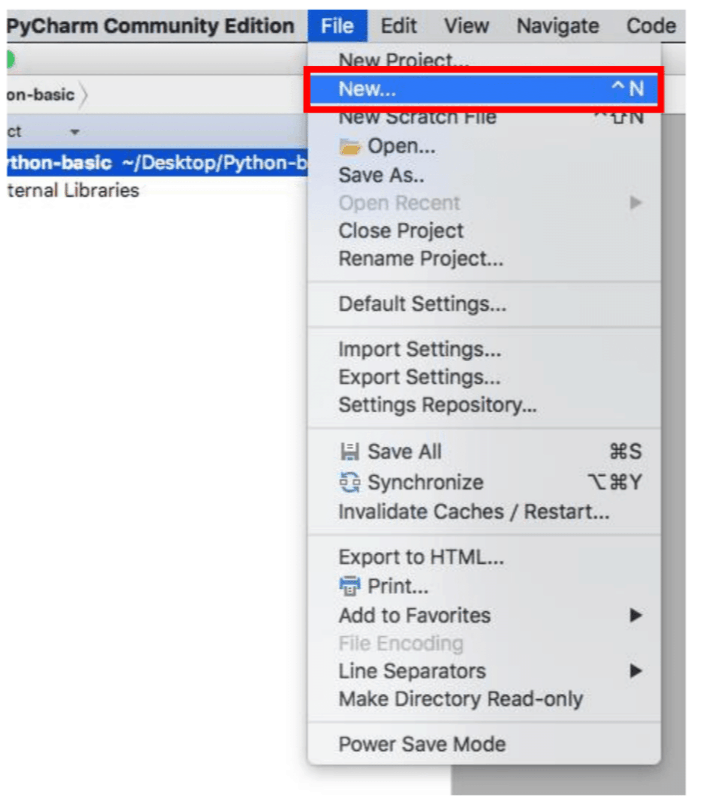
ダイアログボックスから、「Python File」を選びます。
「Name」に「svm.py」と入力し、[OK]をクリックします。
ライブラリをインポートします。
from sklearn import datasets
from sklearn import svm
import matplotlib.pyplot as plt
from sklearn import metrics
こちらは、デフォルト(default)画面です。
上から、データセットのインポート、SVMのインポート、グラフ描画用ライブラリのmatplotlibのインポート、結果を混同行列として確認するためのmetricsのインポートです。
データの準備と可視化
今回は、手書の数字が含まれたMNISTデータセットを利用します。
#データの準備
digits = datasets.load_digits()
n_samples = len(digits.data)
print("データ数:{}".format(n_samples))
#データの可視化
images_and_labels
= list(zip(digits.images, digits.target))
for index, (image, label) in enumerate(images_and_labels[:10]):
plt.subplot(2, 5, index + 1)
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.axis('off')
plt.title('Training: %i'% label)
plt.show()
MNISTとは、Mixed National Institute of Standards and Technology databaseの略で、0~9までの手書きの数字画像が含まれたデータセットです。
学習用のデータが60,000個、テスト用のデータが10,000個の、合計70,000個の手書き文字データが含まれています。

datasets.load_digits()で、簡単にMNISTデータセットを呼び出すことができます。
最後のfor文は、1797データが含まれているデータセットのうち、始めの10個だけをビジュアライズするコードになっています。
ここまで実行してみると、以下のような出力になるはずです。

SVMの設定
いよいよここから、SVMの設定です。
# SVM の読み込み
clf = svm.SVC(gamma=0.001, C=100.)
gammaとCが、調整が必要なハイパーパラメーターです。
gammaは、高次元空間へのマップ方法である放射基底関数(RBF:radial basis function)カーネルとも呼ばれるガウシアンカーネルの計算時に使用される、幅を制御する調整用のパラメーターです。
gammaが小さいとガウシアンカーネルの直径が大きくなり、多くの点を近いと判断するようになり、gammaが大きいとデータポイントを重視するようになり、モデルがどんどん複雑になります。
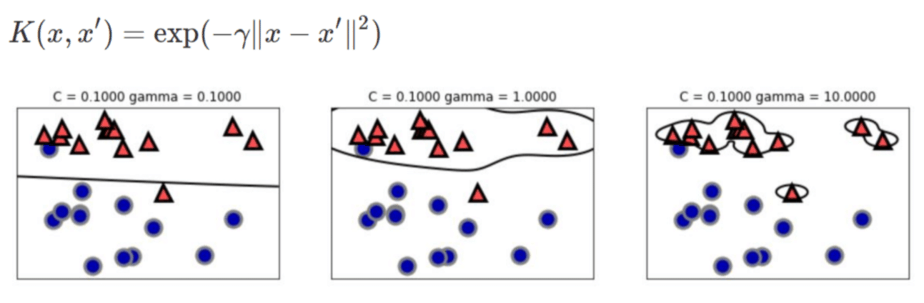
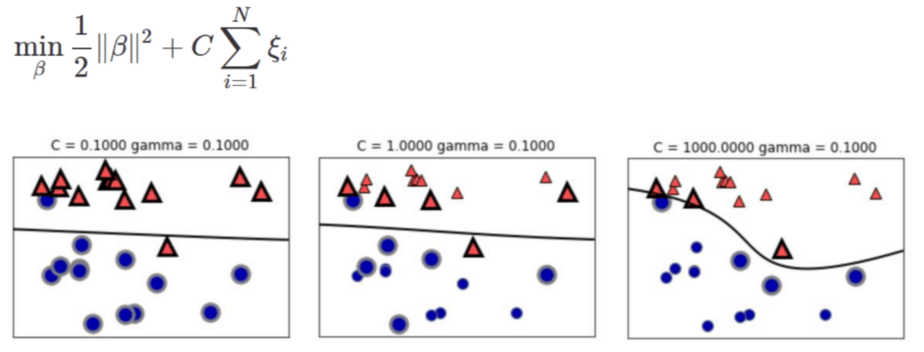
Cは、正則化パラメーターです。
これは、誤分類をどれだけ許容するかを決めるパラメーターで、大きく設定するほど誤分類をしないように分離が行われます。
AIエンジニア講習ではScikit-learnを使ったSVMのプログラミング方法が学べます。
学習を実行するコードの記述
学習を実行するコードを記述します。今回は、全データの60%を使用して学習を行いました。
# 60%のデータで学習実行
clf.fit(digits.data[:int(n_samples * 6 / 10)], digits.target[:int(n_samples * 6 / 10)])
なんと、1行で済んでしまいます!
Scikit-learnにはSVMのアルゴリズムが既に実装されているため、複雑な計算式は書かなくても、ハイパーパラメーターと学習実行さえ行えば機械学習ができるようになっているのです。
clf.fit(入力データ, ラベルデータ)と指定することで、学習が実行されます。残っている40%のデータを使って、テストを実行するコードを記述します。
# 40%のデータでテスト
expected = digits.target[int(n_samples *-4 / 10):]predicted = clf.predict(digits.data[int(n_samples *-4 / 10):])
print("Classification report for classifier
%s:¥n%s¥n"% (clf,metrics.classification_report(expected, predicted)))
print("Confusion matrix:¥n%s" % metrics.confusion_matrix(expected, predicted))
実行すると、以下のような表が表示されます。
この表は、Scikit-learnで用意されているmetrics機能を使用したもので、学習済みモデルの評価ができます。学習済みモデルが、予測をした結果がどの程度の評価で認識できているかを示してくれます。

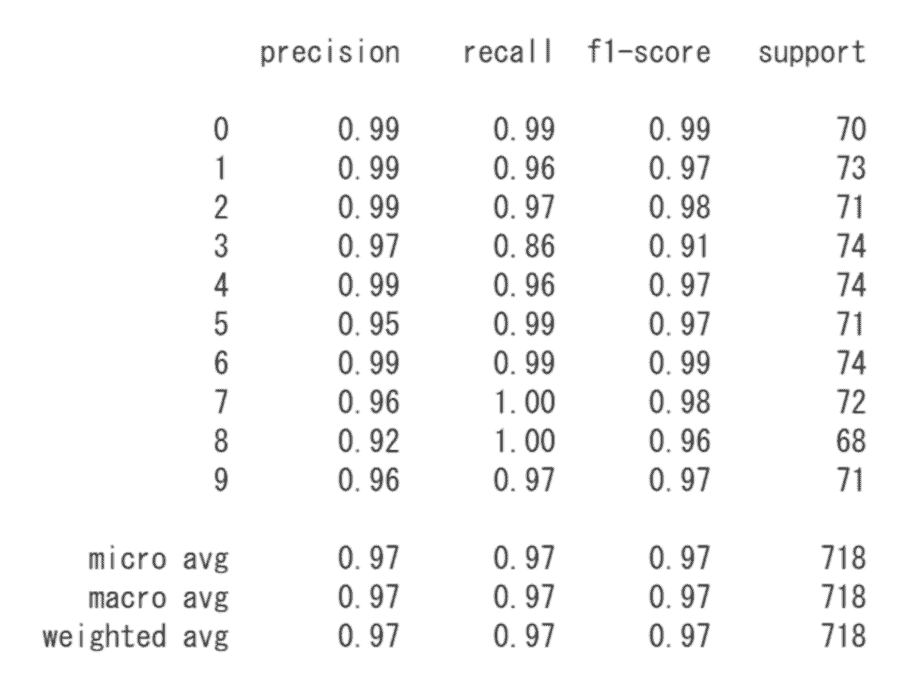
また、下に表示されるのは混同行列(Confusion Matrix)です。
行(正解ラベル)に0~9の手書き数字、列(予測ラベル)にも0~9の手書き数字があるとして、正解数が表示されます。
例えば、2行目を確認すると、1という手書き数字に対して1と予測したものが70個あり、2と間違えてしまったものが1個、8と間違えてしまったのが2個ある、という意味になります。

予測結果の可視化
こちらは必須ではないですが、予測結果を可視化してみます。
#予測結果を可視化
images_and_predictions = list(zip(digits.images[int(n_samples *-4 / 10):], predicted))
for index,(image, prediction) in enumerate(images_and_predictions[:12]):
plt.subplot(3, 4, index + 1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Prediction: %i' % prediction)
plt.show()
出力結果は以下のようになります。

Scikit-learnでは、SVMによるデータ分類のため、数多くのデータ呼び出し、さらにデータの整理もしなければいけません。
混乱してしまうこともあるかもしれませんのでタブ(Tab)を上手く利用して、自分自身が解りやすいように整理するようにしましょう。
ちなみに以下の記事ではScikit-learnを初めて使う方に向けて機能やチュートリアルをわかりやすく解説しますので、是非チャレンジしてみてください。
Scikit-learnについて復習したいという方は、まずはこちらの記事を読んでからこの記事に戻ってきましょう。
【2025】Scikit-learnとは?メリットや機能・チュートリアルについて解説
SVM・サポートベクターマシンについてまとめ
今回はSVMとはなんなのかというところから、実際にライブラリを利用してSVMを実装する手順まで解説しました。単純なモデルでしたが、Scikit-learnのSVMを使ったクラス分類の方法をご理解いただけたのではないでしょうか。
SVMは、「カーネル関数」と「マージン最大化」の概念を理解すれば、機械的にデータを入力していくだけです。
まずは、「カーネル関数」と「マージン最大化」の考え方を理解し、ハイパーパラメーターを調整するところから試してみてください。
なおScikit-learnを使ったSVMのプログラミング方法をしっかり学びたい方には、AIエンジニア講習を受講されるといいでしょう。