

2017年、Googleは今日のAIブームの発端となった論文「Attention is All You Need」を発表しました。この論文で導入されたトランスフォーマーは、現在主流となっているほぼすべての大規模言語モデルの基盤となっています。
そして現在、トランスフォーマーが抱える課題「長期記憶」を解決する新アーキテクチャ「Titans」が登場しました。本記事では、Titansの仕組みと実力をわかりやすく紹介します。
Googleの新AI「Titans」とは?
Titans(タイタンズ)は、AIの「長期記憶」を実現する新しいアーキテクチャ(設計図)です。
Titansは、2024年12月31日にGoogleの研究者らが発表した研究論文で示され、続く2025年4月17日には、長期記憶の理論を示した新たな論文「MIRAS」が公開されました。
Titans最大の特徴「リアルタイムの記憶」
 Titansの最大の特徴は、Titansの論文タイトル「Learning to Memorize at Test Time」が示す、「推論中に重要な情報を記憶・更新しながら対話を進める」という考え方にあります。例えば、
Titansの最大の特徴は、Titansの論文タイトル「Learning to Memorize at Test Time」が示す、「推論中に重要な情報を記憶・更新しながら対話を進める」という考え方にあります。例えば、
- 会議の冒頭で「この顧客は品質重視」と伝達
- 後の戦略提案でも品質を軸に判断
のように、Titansは最初に伝えた条件を忘れず、後の判断に反映することが可能です。Titansはこうした「リアルタイムの記憶」を積み重ね、同時に長期記憶も形成していきます。
Titansの長期記憶は人間の脳を模倣
Titansの長期記憶は、深いニューラルネットワークである多層パーセプトロン(MLP)で構成されています。これは、人間が自然に使い分けている「短期記憶」と「長期記憶」の仕組みを、そのままAIの設計に組み込んだシステムです。
加えて、Titansはすべてを無差別に記憶せず、自身の予測と大きく食い違った情報を優先的に記憶します。私たちが「意外なニュースほどよく覚えている」のと同じで、Titansも「驚き」で記憶の強さを調整しているのです。
Titansの基盤であるニューラルネットワークについては、以下の記事で解説しているのでぜひご一読ください。
記憶を暴走させない2つの機能
この記憶構造を安定して機能させるため、Titansは次のような仕組みも備えています。
- モメンタム:連続する重要な流れとして文脈を保つ
- 忘却: 判断に影響しなくなった情報は自然に手放す
これらの制御により、記憶が増えすぎて破綻することを防ぎ、Titansは長期にわたって安定した学習と推論を行えるのです。
セミナーで最新AI情報をキャッチアップしよう!
リアルタイムで記憶を更新するTitansが登場した2026年、利用する私たちも知識の迅速なアップデートが必要です。この進化を味方につけ、製造・建設現場で生き残るための具体策を製造業・建設業向け 生成AI無料オンラインセミナーでマスターしましょう。
トランスフォーマーを超えたTitansの実力
生成AIといえば、OpenAIの主力モデルであるGPT‑4が代表的な存在です。創作、推論、コード生成まで幅広くこなす万能モデルとして、長らく「越えるべき基準点」とされてきました。
では、そのGPT‑4と比較してTitansはどれほどの実力を持っているのでしょうか。ここからは、長文処理能力を測定するベンチマーク「BABILong」の結果をもとに、Titansの強みを具体的に見ていきます。
既存モデルを圧倒する長文対応力
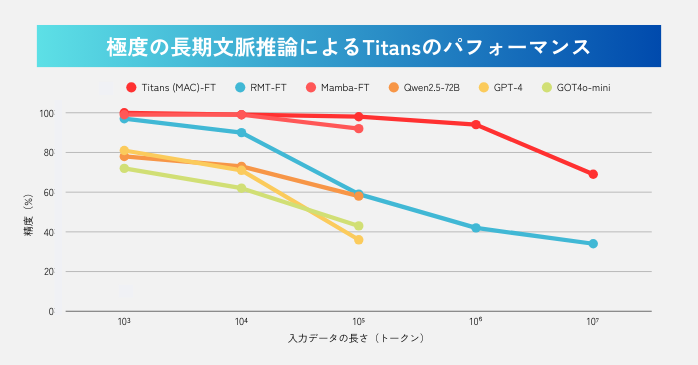
添付のグラフが示す通り、Titansはトランスフォーマー構造を採用した主要なAIモデルを大きく上回る結果を示しました。
GPT‑4やQwen2.5のような超大規模モデルでも、入力が10万トークン(10⁵)を超えると精度が急激に低下し、計測不能になります。しかしTitansは、10⁷(1,000万トークン)を超える領域でも約7割の精度を維持しています。
Titansは計算コストも圧倒的に少ない
このベンチマークでは、Titansの計算コストの低さも際立っています。従来のトランスフォーマーは文書が長くなるほど計算量が増大しますが、Titansは200万トークン級の膨大なデータでも処理が重くなりません。
つまり、TitansはGPT‑4よりはるかに小さなモデル規模で、情報の保持と検索を同時にこなせる構造になっているのです。
トークンの規模の目安
なお、Titansのベンチマークで使用された「入力データの長さ」は、AIが文章をどの程度細かく分割して処理しているかを示す「トークン」という単位で表されています。
トークン数が増えるほど、モデルが扱う文脈は長くなり、長文処理能力の差がより明確に現れます。規模の目安は、以下をご参照ください。
- 10³(千トークン):数ページのレポート
- 10⁴(1万トークン):短編小説
- 10⁵(10万トークン):単行本約1冊
- 10⁶(100万トークン):長編小説数冊分
- 10⁷(1,000万トークン):長編小説100冊分
BABILongのテスト方法
このTitansのテストを行ったBABILongでは、以下の様な方式を採用しています。
- 膨大なデータの中に、答えにつながる事実をバラバラに配置
- AIがそれらを正しく結びつけて推論できるか
このTitansのテストは、長大なデータの冒頭情報を最後まで忘れずに保持し、活用しなければなりません。つまり、従来のAIにとっては極めて難しい課題ですが、Titansにとっては、独自の長期記憶能力が最も発揮できる領域なのです。
参照:Titans + MIRAS:AIに長期記憶を持たせるために
なお、AIの学習には、公的機関などが無償公開している「オープンデータ」が広く活用されています。データ種別や活用法については、以下の記事で解説しているのでぜひご一読ください。
Titansが登場した背景

ところで、なぜ今これほどまでにTitansの「長期記憶AI」が求められているのでしょうか。実は、Titansが登場した背景には、既存のAIモデルが抱えてきたいくつかの課題があったのです。
トランスフォーマーが抱える2つの課題
現在、多くのAIで主流となっているトランスフォーマーは、「アテンション(注意)」機構によりSOTA(最高水準)の正確性を持つモデルとされています。
しかし、テキストの長さに応じて計算量が二乗で増加する、つまり読み込む量が2倍になれば、必要なリソースは4倍になるため、巨大な情報(長文)を扱うことが事実上困難でした。
解決策として登場した線形モデル
この課題を解決するために登場したのが、計算量がデータの長さに比例する「Mamba」や「RWKV」といった線形モデル(線形RNN)です。これらは処理速度が速く、入力量が増えてもコストに大きな影響を与えません。
その代わり、記憶の履歴を小さなメモリ状態に圧縮して処理するため、圧縮の過程で細かな情報やニュアンスが失われるという欠点がありました。
正確性と速度を両立したTitans
Titansは、トランスフォーマーの「正確性」、線形モデルの「高速性」という両方のメリットを兼ね備えています。つまり、
- 正確だが重すぎるトランスフォーマー
- 速いが詳細を忘れる線形モデル
の両者の弱点を同時に解決するアーキテクチャがTitansなのです。
Titansを支えるMIRASの理論

MIRASは、トランスフォーマーや線形RNN、Titansといったシーケンスモデルには「連想記憶」という共通概念があるという発見から生まれた理論です。
Titansをはじめ、今までこれらのシーケンスモデルは別々のアーキテクチャとして扱われてきました。しかし、実は「共通の4要素の組み合わせ違いにすぎない」という発見に基づいています。
MIRASを構成する4つの要素
では、Titansの基盤であるMIRASで定義している4要素をお伝えしましょう。
| 要素 | 主な内容 | Titansの採用 |
| メモリ構造 | 内部の記憶の形、表現力を決定 | 深いMLPメモリ |
| アテンショナルバイアス | 情報の記憶の優先を決定 | 目的関数(L2) |
| 情報保持 | 忘却ではなく、過去と新情報を調整 | L2正則化 |
| 記憶学習アルゴリズム | 記憶更新に関するルール | 勾配降下+モメンタム |
MIRASから生まれた新モデル
Titansの基盤となったMIRASの理論は、この枠組みを発展させる形で、いくつもの新しいモデルを生み出しています。
| モデル名 | 特徴 |
| Moneta | 外れ値(異常値)に強い安定した記憶更新、状況に合わせて調整 |
| Yaad | 極端(予想外)な事象から自身を保護する堅牢なメモリ |
| Memora | 記憶を確率分布として扱うことで文脈を長期的に保持 |
これらのモデルは、
- 言語モデリング
- 常識推論
- Needle-in-a-Haystack
- 長期記憶タスク
などで、トランスフォーマーや線形RNNを上回る性能を示しています。こうしたMIRASの成果が統合されて生まれたのが、長期記憶と継続推論でAIの未来を形作るTitansです。
GoogleがTitans+MIRASで目指す未来
 では、GoogleはこのTitansで何を目指し、何を達成しようとしているのでしょうか。
では、GoogleはこのTitansで何を目指し、何を達成しようとしているのでしょうか。
その答えを探るために、2026年1月16日にYouTubeで公開されたGoogleDeepMindCEOデミス・ハサビス氏の独占インタビューをもとに、GoogleがTitans+MIRASで描く未来像を解説します。
未来のAIに必要な3つの能力
ハサビス氏は、今後のAIに必要な要素として次の3つを挙げています。
- 継続学習
- 動的な長期記憶
- ワールドモデル(世界理解と予測)
これらは、Titansが重視する「長期記憶」と「継続的推論」と方向性が一致しています。
現在の大規模言語モデル(LLM)は、Geminiのようなマルチモーダルモデルも登場していますが、それでもなお「世界そのものを理解している」とは言い切れない段階にあります。
Titansが目指す「忘れないAI」「文脈を維持し続けるAI」は、この課題を補うためのものです。
LLMとワールドモデルの融合が必要な理由
ハサビス氏は、AIが次のフェーズへ進むためには、LLMとワールドモデルの統合が必要であり、これらは収束できるとみています。具体例として挙げられているのが、
- Genie(対話型ワールドモデル)
- Veo(動画生成モデル)
で、これらはGoogleが考える「初期段階のワールドモデル」と位置づけられています。その理由は明確で、リアルで一貫性のある動きを生成できるということは、背後にある世界構造を何らかの形で捉えているはずだという理論です。
Titansも、モデルが見出した世界の構造を受け継ぎ、長い文脈の中で活かしていく役割を担っています。
Titans+MIRASが導くAGIへの道
ハサビス氏は、2010年のGoogleDeepMind創業当初から「AIの進化(AGI到達)は20年規模のミッションである」と述べてきました。この見方に従えば、2030年前後には、そのミッションを完了したAIが実現することになります。
なお、AGI(汎用人工知能)とは、人間のように柔軟で適応的な知能を持つAIのことであり、
- 世界を理解する
- 文脈を長期にわたって保持する
- 継続的に学び続ける
- 自律的に行動する
といった能力が求められます。これらはLLM単体では到達が難しい領域ですが、TitansとMIRASが提供する「長期記憶×継続学習×世界理解」によって、その未来は着実に近づいています。
参照:The Man Behind Google’s AI Machine | Demis Hassabis Interview
セミナーに参加して最新AIリテラシーを身に付けよう!
ハサビス氏が予見する2026年、AIは「自律型エージェント」や「ロボティクス」として実社会へ進出します。Titansを含めた急速な進化の過渡期にある今こそ、最新のAIリテラシーへのアップデートが必要です。
ぜひ、製造・建設業の生成AI成功事例・導入の具体策を学べる製造業・建設業向け 生成AI無料オンラインセミナーで、Titansの進化を踏まえたAI時代に生き残るスキルを手に入れてください。
セミナー名 製造業・建設業 生成AI無料オンラインセミナー 日時 アーカイブ配信中 価格 無料 開催場所 Zoomウェビナー(オンライン)
Titansについてまとめ
Titansはベンチマークでトランスフォーマーを代表するGPT-4を圧倒し、その確かな実力でAIの未来を変えようとしています。ゲームチェンジャーと呼ばれるTitansのアーキテクチャは、AGI到来の未来を予見するに足る十分な説得力に満ちています。
Titansが叶える高度な恩恵を最大限に活用するためにも、私たち自らが積極的に最新の技術動向をアップデートしておきましょう。






