
近年、人工知能 (AI) の進化は目覚ましく、これに伴いAIを導入した多くのサービスがすでに提供されています。
プログラミングの世界でもAIのプログラミングは新たな技術の主役となりつつあります。
特に、機械学習の技術はAIの根幹を成す要素であり、AIサービスの導入を検討している、あるいはすでにサービスローンチしている企業では、機械学習の実装ができる人材が必須なっています。さらに多くの民間シンクタンクや公的な研究機関でも積極的に機械学習技術が取り入れられています。
機械学習は、大量のデータからパターンを学習し、未来の予測や判断をサポートする技術であり、これによりAIは人間のような判断を行えるようになります。
Pythonは、その柔軟性と豊富なライブラリを活用できる自由度の高いプログラミング言語として、機械学習の分野で広く利用されています。
Pythonのコードは読みやすく、また多くの機械学習関連のライブラリやフレームワークが提供されているため、エンジニアやデータサイエンティストにとっては非常に魅力的な選択肢となっています。
本記事では、AI時代に求められるPythonを使用した機械学習プログラミングのテクニックについて解説していきます。
機械学習プログラミングの基本

まずはAIモデルの構築や機械学習の仕組みの基本について解説します。
機械学習は、コンピュータが大量のデータからパターンやルールを学習し、それを基に新しいデータに対する予測や判断を行う技術です。
この学習プロセスは、人間がコンピュータに明示的にプログラムを教えるのとは違って、大量のデータを通じてコンピュータが自らそのデータないの規則性や傾向について学び、理解を深めることで、新しいデータに対して自ら正解を予測することができるようになることを目的としています。
機械学習には主に以下の3つの種類に分類できます。
教師あり学習(Supervised Learning)
教師あり学習は、既に答えがわかっているデータセット(訓練データ)を利用して、コンピュータに特定のタスクを学習させる方法です。
訓練データは入力データとそれに対応する正解ラベルから構成され、コンピュータはこれらのデータを使用して、未知の新しいデータに対する予測モデルを構築します。
教師なし学習(Unsupervised Learning)
教師なし学習は、正解ラベルが提供されていないデータを使って、コンピュータがデータの構造やパターンを自ら見つけ出す学習方法です。
この方法では、データのクラスタリング(グループ分け)や次元削減(データの複雑さを減らす)などが行われます。
強化学習(Reinforcement Learning)
強化学習は、コンピュータが周辺の環境からの情報を考慮しながら、最も良い結果が得られるような行動を学習する方法です。コンピュータは行動を取ることで環境からフィードバック(報酬)を受け取り、そのフィードバックを基に次の行動を選択します。
機械学習のプロジェクトは、通常、
- データの収集と前処理
- モデルの選択と訓練
- モデルの評価と改善
のステップから構成されます。そして、Pythonはこれらのプロセスを効率的に実行するための多くのライブラリとツールを提供しており、特に機械学習のためのライブラリであるScikit-learnや深層学習のためのフレームワークであるTensorFlow、PyTorchが広く利用されています。
また、AIの学習はデータの量や種類によって適切な方法が異なります。
この基本的な概念を理解することで、機械学習のプログラミング技術をさらに深く学ぶ土壌が整います。
次のセクションでは、Pythonを使用した機械学習プログラミングの実用的なテクニックについて解説していきます。
以下の記事でもAIモデルの構築について解説していますのでぜひご覧ください。
Pythonによる機械学習プログラミングに必要な準備について

機械学習プログラミングに取り組む前に、いくつか準備を整える必要があります。
それにはまず、適切な環境構築を整える必要があります。
Pythonのインストールに始まり、実際にプログラムを書き込むGUIやCUIが必要です。
また、統合開発環境 (IDE) の選択、そして必要なパッケージの管理が必要となってきます。
これらの準備は、実際に学習工程に入ったときにエラーなくスムーズに開発を行うために重要であり、プロジェクトの進行に大きく影響するため、非常に重要です。
こうした事前準備について詳しく説明し、機械学習プログラムを効果的に開発するための基盤を構築する方法について説明します。
環境構築
環境構築は、機械学習プログラミングを始める最初のステップです。
機械学習プログラミングを始める前に、まずはPythonのインストールと、必要なライブラリやツール(例えば、 Scikit-learn, Pandas, NumPy など)のセットアップが必要です。最初にお使いのハードウェアの状態や、オペレーティングシステムについて確認しておきましょう。
機械学習を行うためには最低限、以下のようなコンピュータのスペックやストレージが必要になります。
機械学習に必要なコンピュータのスペック
| OS | Windows/MacOS/Linuxいずれでも可能 (但し、ネットでの情報が多いのはMacです。) |
| メモリ | 8GB以上 (これは最低限です。現実的な実行時間で学習を行うには16GB以上のメモリが推奨されます。) |
| ストレージ | 250〜500GB 程度 (クラウドなどにデータを保存すればこの程度でOKです。) |
| GPU | メモリ8GB以上 (NVIDIA社 GeForce RTX シリーズ推奨 ※予算に余裕があれば) |
上記のような環境があれば、非常に深層のディープラーニングなどでなければローカル環境での実装が可能です。ローカルでの環境が準備できなくても、Google Colabratory を利用すれば、一定の制限はあるものの、無料でGPUの利用が可能です。
さらに、目的に応じたソフトウェアやライブラリのインストールが必要になります。
通常、Pythonは機械学習プロジェクトのための優れた選択肢であり、Anacondaという無料のオープンソースディストリビューションを利用することで、Pythonとその必要なライブラリを簡単にインストールできます。
Anacondaは、データサイエンスと機械学習に必要なツールを提供し、環境の管理とパッケージのインストールを簡単に行うことができます。
IDE(統合開発環境)を活用する
統合開発環境 (IDE) は、コードの記述(エディエタ機能)、デバッグ、そしてテストを効率的に行うためのソフトウェアツールセットです。
IDEは、コードエディタ、デバッガ、そしてビルド自動化ツールを提供しており、プロジェクトの管理とコードの品質を向上させてくれます。
機械学習のためのIDEとしてポピュラーなのは、PyCharmとVisual Studio Code (VS Code) などで、多くのプログラミング学習コースでこれらのIDEの使用が推奨されています。
こうしたIDEは、Pythonプログラミングを強力にサポートしてくれ、さまざまな機械学習ライブラリやターミナルとの統合も簡単に行うことができ、Jupyter notebook (ジュピターノートブック)のようなメジャーな開発環境との連携もでる非常に便利なツールです。
パッケージ管理
プロジェクトで使用するライブラリとツールのバージョンは適切に管理されなくてはプログラムはうまく動いてくれません。
開発環境にライブラリなどをインストールする際は、Pythonの場合、pip のようなパッケージインストーラを使用します。pip を使えば、インストールしたライブラリのアップデートなどを簡単に行うことができます。
また、Anaconda環境を使用する場合は、conda(Anacondaのパッケージマネージャ)を利用することで、必要なパッケージを簡単にインストールし、管理することができます。
パッケージ管理を適切に行わないと、ライブラリに依存関係が発生し、パッケージのインストールがうまくできなくなったり、エラーが発生したりします。
このような状況をコンフリクトと呼びます。
コンフリクトを回避し、他の開発者との開発環境の共有のためにも適切に開発環境を整えることが重要です。
Python機械学習プログラミングの工程

では機械学習の具体的な工程について説明していきます。
おおまかにお伝えすると、データの準備→モデルの学習→モデルの評価の順に行います。
データを確認する
まずは機械学習を行う最初の段階として、AIに学習させるデータの特徴や、データに不備がないかなどを確認する必要があります。
機械学習プログラミングを行う上で、AIに学習させるデータには欠損がなく、他のデータと大きく差があるデータを取り除いた状態にする必要があります。
そのためには、データを観察してどのような処理が必要なのか、あるいはAIモデルを決定するための根拠をデータの中から探し出す必要があります。
このような作業を探索的データ解析(EDA)といます。
探索的データ解析は、データを理解し、その特性や構造を把握するための重要なステップです。
データの可視化や基本的な統計量を確認して、データの特徴や問題点を明らかにし、外れ値や欠損したデータがどこにどれくらいあるのかなどを把握します。
データの前処理
データの前処理では、欠損値の処理、カテゴリデータのエンコーディング、特徴量のスケーリングなど、データをモデルが理解しやすい形に整えます。
モデルの学習手法の決定
機械学習モデルの学習方法は主に、教師あり学習、教師なし学習、および強化学習に分類され、その違いを理解することが重要です。
教師あり学習

教師あり学習はデータに正解が含まれている場合に適用します。
このデータを教師データと呼びます。画像認識や数値予測などに使用されます。
教師あり学習では、学習用のデータを説明変数と目的変数の2つに分けてから学習を行います。
例えば、お店の売上を予測する場合、客単価や客数などが説明変数で、売上が目的変数となります。
教師なし学習
教師なし学習は、データセットに隠された特色や傾向を分析してクラス分けを行ったり、教師あり学習の前段階の処理として実装することもあります。
強化学習は、教師なしデータで行う学習で、AI自身が学習結果から精度を高めるために答えを探索する手法です。ロボットの動きを学習したり、自動運転車の制御をするのに使用されます。
これらの方法は前述した通り、データ量やデータ同士の相互関係や、予測する対象と目的によって異なります。
どんな学習手法を使えばいいのか判断できない場合は、チートシートを使って学習手法を選択することができます。
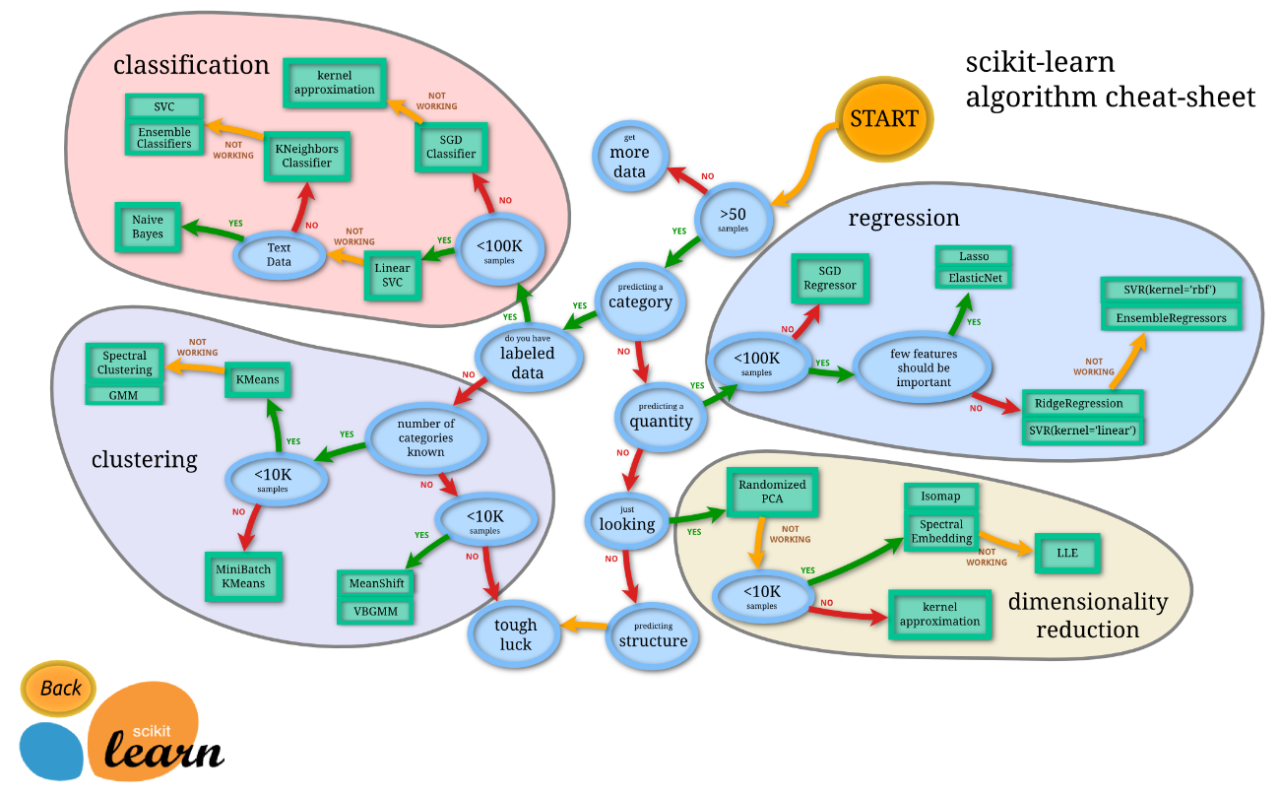 引用:scikit-learn
引用:scikit-learn
モデルの学習
データの準備とモデルの選定を終えたらいよいよモデルの学習です。この工程では、選択したアルゴリズムに基づいて、訓練データを使用してモデルをモデルを訓練します。
AIモデルは訓練データから一定の規則性やパターンを学習して、未知データの予測や判断のための知識を獲得します。学習プロセスは、特定の目的関数を最適化することによって行われ、モデルの性能を向上させます。
モデルの評価選択したモデルにデータを供給し、アルゴリズムがデータからパターンを学習するプロセスを実行します。
モデルの評価
モデルの評価は、学習したモデルの性能を測定するステップです。
通常は、学習用データセットを訓練データとテストデータに分割しておいて、テストデータを使用してモデルの予測性能を評価します。
評価の方法は数値予測とクラス分類で異なります。
数値予測
数値予測の場合、AIの予測値がデータの平均値とどれくらい離れているのかなどで評価しますが、
- 評価の値には平均絶対誤差(MAE)
- 平均二乗誤差(MSE)
- 二乗平均平方根誤差(RMSE)
などがあります。
クラス分類
クラス分類の評価手法には、
- 正解率
- 再現率
- F1スコア
などのメトリクスである混同行列を計算して評価します。
評価は、モデルが未知のデータに対してどれだけ適切に数値の予測や判断を行えるかを理解するために不可欠です。また、モデルの性能を向上させるためのフィードバックとしても利用されます。
学習したモデルの性能を評価し、必要に応じてモデルの改善を行います。評価指標を使用して、モデルの精度をチェックし、精度を高めます。
機械学習モデルの精度を上げるためのテクニック
機械学習モデルの精度を向上させるためには、多くのテクニックが存在します。
以下にいくつかの主要なテクニックを紹介します。
再度データ前処理を施す
データのクリーニングと前処理はモデルの精度に大きな影響を与えます。
学習済みのモデルを構築後も欠損値の処理、外れ値の検出と修正、および説明変数のスケーリングなどのデータ前処理を再度実施してみてください。
データをきれいにすることはモデル性能の向上に向けた最も効果的な方法です。
特徴量エンジニアリング
AIモデルの学習に使う説明変数の1つ1つを特徴料と読んだりもします。
AIモデルの予測に対して有用な特徴量を選択したり、新しい特徴量を作ることで、モデルの予測性能を向上させることができます。
特徴量エンジニアリングは、データの潜在的なパターンとその関係を明らかにする上でとても重要です。
モデル選択とハイパーパラメータチューニング
選択したアルゴリズムで良い結果が出なければ、違うアルゴリズムを試してみましょう。
データによっては精度が出ないアルゴリズムもあるため、変更することで良い結果が得られる場合があります。また、最適なハイパーパラメータを見つけることで、モデルの性能を向上させることができます。
ハイパーパラメータチューニングは、グリッドサーチ(Grid Search)やランダムサーチ(Randomized Search)などの方法を使用して行われます。
交差検証
交差検証は、モデルの性能向上させるための信頼性の高いテクニックです。
データセットを複数のサブセットに分割し、それぞれのサブセットでモデルを学習して評価します。これにより、モデルの性能がデータセットの特定の部分に依存していないことを確認できます。
データの分割には Scikit-learn のパッケージにある、preprocessing モジュールないの train-test-split 関数を使用するのが手軽な方法です。
アンサンブル学習
アンサンブル学習は、複数のモデルを組み合わせて単一のモデルよりも優れた予測性能を達成するテクニックです。
Bagging, Boosting, Stackingなどのアンサンブルメソッドは、モデルのバリアンスとバイアスをバランス良くし、予測精度を向上させます。
学習の早期停止(Early Stopping)
早期停止は、過学習を防ぐためにモデルの学習を途中で停止するテクニックです。
モデルの性能がテストデータに対して改善されなくなった、あるいは精度が一定回数落ちてきた時点で学習を停止し、過学習を避けます。
正則化
正則化もAIモデルの性能向上に対して効果的な手段です。
正則化は、モデルが訓練データに過度に適合するのを防ぐためのテクニックです。
L1正則化とL2正則化は、モデルのコンプレックスさを制御し、過学習を減らすために使用されます。
これらのテクニックは、機械学習モデルの精度と性能を向上させる上で重要です。
適切なデータ前処理、特徴量エンジニアリング、モデル選択とハイパーパラメータチューニング、そして評価方法を選ぶことで、高性能な機械学習モデルを構築することができます。
Python機械学習ライブラリの特徴を紹介
機械学習の環境構築を行う上で必須なライブラリについてご紹介します。
Scikit-learn
![]()
Scikit-learnは、Pythonのオープンソース機械学習ライブラリであり、単純で効果的なツールを提供して、データマイニングやデータ解析をサポートします。
このライブラリは、分類、回帰、クラスタリング、次元削減、モデル選択など、広範な機械学習タスクを簡単に実行できます。
Scikit-learnは、非常に使いやすく、広範なドキュメンテーションとコミュニティサポートを提供しているため、初心者にも非常に人気があります。
TensorFlow / Keras

TensorFlowは、Googleが開発したオープンソースのディープラーニングフレームワークであり、大規模なデータセットでの高性能なニューラルネットワークの訓練と実行を可能にします。
Kerasは、TensorFlowの高レベルAPIであり、より簡単かつ高速にディープラーニングモデルを構築するためのインターフェースを提供します。
Kerasは、使いやすさと柔軟性を重視して設計されており、プロトタイプの作成から本番環境での運用まで幅広くサポートしています。
PyTorch

PyTorchは、Facebookが開発したオープンソースのディープラーニングフレームワークであり、動的計算グラフを特徴としています。
これにより、モデルの構築とデバッグが非常に簡単になります。
PyTorchは、研究やプロトタイプ作成に非常に適しており、自然言語処理やコンピュータビジョンのタスクで広く利用されています。
また、PyTorchは強力なコミュニティと豊富な学習リソースを提供しており、ディープラーニングの研究者やエンジニアに人気があります。
これらのライブラリは、それぞれが特定のタスクや用途に特化しており、機械学習やディープラーニングのプロジェクトを効果的にサポートします。
選択するライブラリはプロジェクトの要件や目標、そしてチームの経験に依存するため、プロジェクトのニーズに最適なライブラリを選ぶことが重要です。
Pythonによる機械学習プログラミング まとめ
機械学習は、今日のテクノロジードリブンな世界で非常に重要な役割を果たしています。
この記事では、機械学習の基本から始め、環境構築、データの前処理、モデルの学習と評価、そして機械学習モデルの精度を向上させるテクニックに至るまで、機械学習プロジェクトの各ステップについて詳しく解説しました。
さらに、Pythonの主要な機械学習とディープラーニングのライブラリについても紹介し、それぞれの特徴と利点をハイライトしました。
機械学習は広範で多様な分野で利用されており、適切な知識とツールを装備することで、データ駆動型の解決策を効果的に開発し、実装することができます。
今回紹介した概念とテクニックは、機械学習の世界へのファーストステップでしかありません。AI人材と呼ばれるためには、より深い理解と実践的なスキルの獲得に向けて更なる学習が必要となります。
これからのAI時代において、機械学習の知識は技術者やデータ科学者にとって、あるいはビジネスシーン全体においても不可欠なものです。
これらの基本的な概念を理解し、適切なツールとテクニックを利用することで、機械学習プロジェクトの成功に大きく貢献することができます。






