最近では元々のデータにはない新しいデータの生成などにも利用されているVariational Autoencoderをはじめ、画像のノイズ除去や可視化、事前学習にも応用されているAutoencoderについて今回は書いていきたいと思います。
Autoencoderとは
そもそもAutoencoderは次元削減を行うためにつかわれています。Autoencoderは基本的には入力層と出力層を合わせて3層で構成されていて、隠れ層のノード数が入力より小さくても、入力と出力が同じになるように学習させていく機械学習の一つです。
とてもイメージが付きづらいですね。少し別のもので例えてみます。
何か非常に重たい数GBのデータを誰かに送らなければならない場合、皆さんはどうしますか?
恐らく、zipファイルなどに圧縮すると思います。そして受け取った人はzipファイルを解凍すれば、元のデータが復元できますね?
これはzip形式への圧縮方法と復元方法を各PCが知っているからできるのですが、この圧縮や復元の方法自体を機械学習させるのが、Autoencoderでやっていることです。(下図の矢印の部分を学習しています)
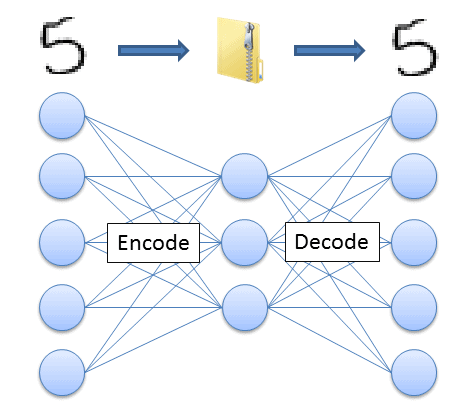
なんとなくイメージついたでしょうか?それでは、実際に学習を可視化していきたいと思います。
MNISTを使ってAutoencoderを試してみる
今回もデータはChainerのサンプルデータセットの中の「MINST」を使用して、Autoencoderを実装してみます。
「MINST」の中には28px×28pxの手書きの数字画像(0〜9まで)を数値化したデータが70,000個入っています。

今回は、少なめに学習用のデータとして2,000個、テスト用のデータとして4個使用します。
クラスを作成します。ここでは、各層のノード数と活性化関数を設定します。
ここで注目していただく部分は、入力及び出力層より隠れ層のノード数が少ないことです。
def __init__(self):
super(Autoencoder, self).__init__(
encoder=L.Linear(784, 256),
decoder=L.Linear(256, 784))def __call__(self, x):
h = F.relu(self.encoder(x))
return h
MNISTのデータには正解のラベルがついているので、取り除く処理を施して、実際に学習と検証をしていきます。
学習回数による精度の可視化
今回はChainerの1.11.0から導入された、Trainerというフレームワークを使って学習を実行する部分を実装していきます。
model = L.Classifier(Autoencoder(), lossfun=F.mean_squared_error)
model.compute_accuracy = False
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)updater = training.StandardUpdater(train_iter, optimizer, device=-1)
trainer = training.Trainer(updater, (epoch, ‘epoch’), out=”result”)
trainer.extend(extensions.ProgressBar())
trainer.run()
非常に短くなりました。For文や、データのセッティング、損失関数の計算等を書かなくてもよくなり、とても簡単に実装できるようになった事が見て取れると思います。
ではエポック数(学習回数)を変更しながら、入力したデータと結果のデータを比較していきます。
各学習回数と出力結果
まずは、検証データがこちらです。これが学習回数でどのように変わっていくかをご覧いただきます。

エポック数=1

さすがに一回ではいいデータにはなりませんね。
では、少し進めて
エポック数=50

少し、元のデータを再現できるようになってきました。
ではさらに進めて
エポック数=200

かなり再現度が高くなってきています。
では、最後に
エポック数=500

もう200回とあまり変わりませんね。
この様に学習回数が多ければ多いほどいいわけでもない事も分かりますね。
今回は、Autoencoderの基礎を知るために学習の様子を可視化してみました。
この学習済みモデルを利用すれば、MNISTをニューラルネットワークを使ったクラス分類の事前学習に利用出来たりしちゃいますね。