Pythonでプログラミングを学びたい方もいるでしょう。そこで重要なのが「正規表現」です。こちらを活用すれば、設定パターンに応じて、特定の文字列を探し出せます。これによりプログラミング作業の効率化が可能なので、是非方法を覚えましょう。今回はPython初心者のために、正規表現の定義や方法をまとめました。この記事を読んで、プログラミングの学習や仕事に活かしてみましょう。
Pythonの正規表現とは?

Pythonの正規表現とは、文字の組み合わせを見つけるパターンです。正規表現ができれば、特定の文字列パターンを短時間で見つけ出せます。プログラミングでは複雑な文字列が多く、文字を見にくく感じる方もいるでしょう。しかし正規表現を使えば、そうした問題を解決できます。
正規表現はプログラミングにおいて、さまざまなデータ処理に使われます。たとえば文字列の置換やパターンマッチングで、対象箇所を探すために有用です。ほかにもデータのバリデーションやテキスト解析にも役立ちます。このように正規表現は、プログラミング作業の効率化で重要といえます。ビジネスで有能な人材になるためにも、是非、正規表現をものにしましょう。
Pythonの正規表現の記法を紹介
ここでは正規表現の記法について解説します。メタ文字と特殊シーケンスの2パターンがあるので、それぞれ参考にしましょう。
メタ文字
正規表現ではいくつかの「メタ文字」を使います。これはプログラミング用の特別な文字で、それぞれ意味合いがあるのです。メタ文字について、以下の代表例を参考にしてください。
| メタ文字 | マッチ対象 | 例 | 抽出文字列 |
| . | 改行以外の任意文字 | a.c | abc, aac, acc, alc… |
| ^ | 文字列の先頭 | ^ab | abc, abd, ab1… |
| $ | 文字列の末尾 | yz$ | xyz, yyz, 1yz… |
| * | 直前の正規表現に対し、0回以上繰り返したもの | ab* | a, ab, abb, abbb… |
| + | 直前の正規表現に対し、1回以上繰り返したもの | ab+ | ab, abb, abbb… |
| ? | 直前の正規表現に対し、0回か1回繰り返したもの | ab? | a, ab |
| [] | 文字集合指定。カッコ内のうちいずれか一文字 | [amk][x-z] | a, m, kx, y, z |
| A | B | AとBのいずれか | a|b | a, b |
| () | グループの開始と終了という意味。丸括弧内の正規表現 | (xyz)+ | xyz, xyzab |
特殊シーケンス
正規表現には特殊シーケンスもあり、以下が代表例です。
| 特殊シーケンス | マッチ対象 | 表示方法 |
| \d | 数字 | [0-9] |
| \D | 数字以外 | [^0-9] |
| \s | 空白文字 | [\t\n\r\f\v] |
| \S | 空白文字以外 | [^\t\n\r\f\v] |
| \w | 英数字 | [a-xA-Z0-9_] |
| \W | 英数字以外 | [^a-xA-Z0-9_] |
厳密には特殊シーケンスの場合、最初に「\」を入力してエスケープを行い、半角逆スラッシュのような文字を出します。たとえば「\w」なら「w」の前の「\」をエスケープして、半角逆スラッシュのような文字に変えるのです。以上で特殊シーケンスが完成します。
Pythonの正規表現の実装にはreモジュールを要する

Pythonで正規表現を実装するなら、reモジュールが必要です。reモジュールでは文字列の検索や置換、分割、連結などが実装されています。reモジュールの実装時は「import re」を入力してください。以下は関連の関数やメソッドの代表例です。
| 関数 | 処理 | 返り値 |
| match | 先頭で一致する文字列を検索 | 対象のマッチオブジェクト |
| search | 一致する文字列を検索 | 対象のマッチオブジェクト |
| findall | 一致するすべての文字列を検索 | 対象の文字列リスト |
| finditer | 一致するすべての文字列を検索 | 対象の全マッチオブジェクト |
| fullmatch | 完全一致する文字列を検索 | 対象のマッチオブジェクト |
| sub | 一致の文字列を置換 | 置換後の文字列 |
検索の場合、一致対象がないと「None」と表示されたり、リストが空になったりします。以上を踏まえ、ケース別のreモジュールの方法を見ていきましょう。
match
match関数は「re.match(pattern, string, flags=0)」とします。任意文字列の先頭に対し、ユーザーが抽出したいワードの有無を判定する形です。
search
文字列全体を対象に、正規表現パターンにマッチさせるなら、search関数を使いましょう。「re.search(pattern, string, flags=0)」と入力します。これにより、任意文字列を対象に抽出ワードの有無を判定します。
findall
こちらは文字列全体で、複数の正規表現パターンをマッチさせるために使います。文字列は「re.findall(pattern, string, flags=0)」としてください。メールアドレスや電話番号など、特定文字列のリストアップに役立ちます。
finditer
「re.findall(pattern, string, flags=0)」と入力します。findallはリストとして返り値が出るのに対し、finditerはマッチオブジェクトが返るしくみです。後者は開始と終了の各位置を取得できるため、柔軟に活用できるでしょう。
fullmatch
「re.fullmatch(pattern, string, flags=0)」という文字列です。任意文字列全体が検索対象で、正規表現パターンとの完全一致があれば、対応のマッチオブジェクトが返ってきます。
sub
「re.sub(pattern, repl, string, count=0, flags=0)」という文字列です。検索に限らず置換もできるので、入力ミスや内容変更への対処に役立ちます。正規表現パターンに一致する箇所があれば、対処すべてを任意の文字列に置き換えたうえで、結果を出すしくみです。
Pythonの正規表現の代表例
reモジュール実装後は、正規表現に慣れていきましょう。ここではcompileやgroup(x)など、ケース別の正規表現の方法を紹介します。
まずはcompileを覚えよう
compileは以下の方法が推奨されます。
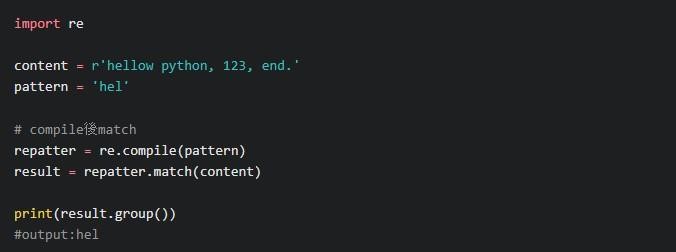
こちらの方が処理も速く、複用もできるため、柔軟に活用できます。compileは正規表現の基本なので、プログラミングに欠かせません。
group(x)
group(x)はターゲット文字の取得に使います。
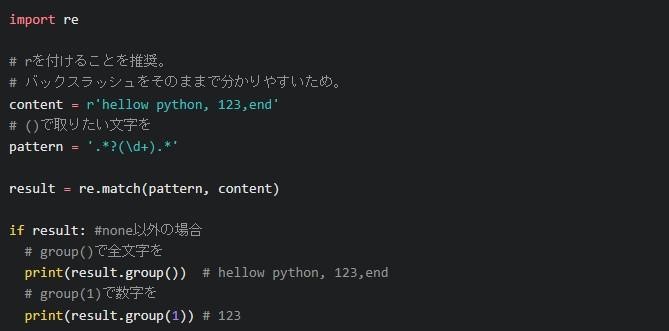
ポイントは「r’hellow python, 123,end’」のように、contentの文字列では対象の先頭に「r」をつけることです。以上により、バックスラッシュがわかりやすくなります。groupの後のカッコ内は空白なら全文字、数字なら数字のみを検索対象にできます。
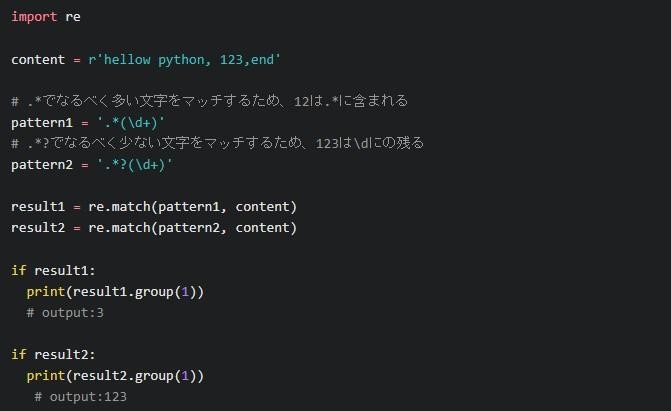
「.*」と「.*?」の区別
「.*」と「.*?」の区別は、マッチさせたい文字に応じて行いましょう。「.*」なら可能な限り多い文字、「.*?」は少ない文字へのマッチを狙います。普段使いやすいのは「.*?」です。
改行
改行するなら、matchで引数を決めてください。加えて「# re.S」も設定しましょう。以上により「.*」が改行を識別します。
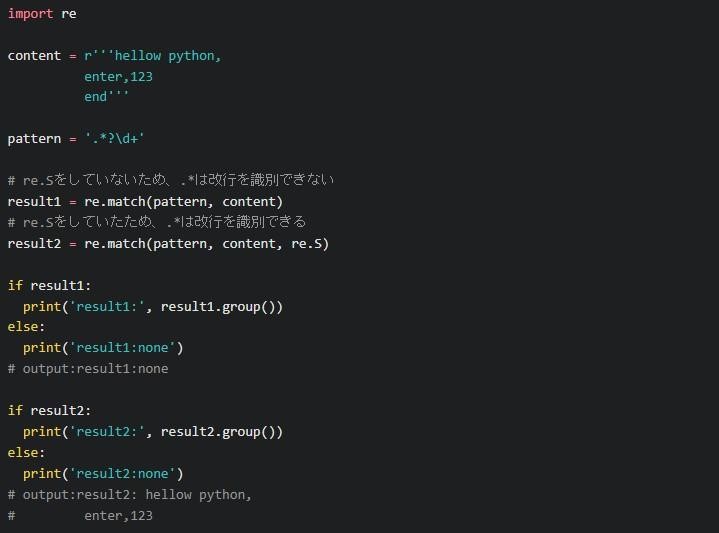
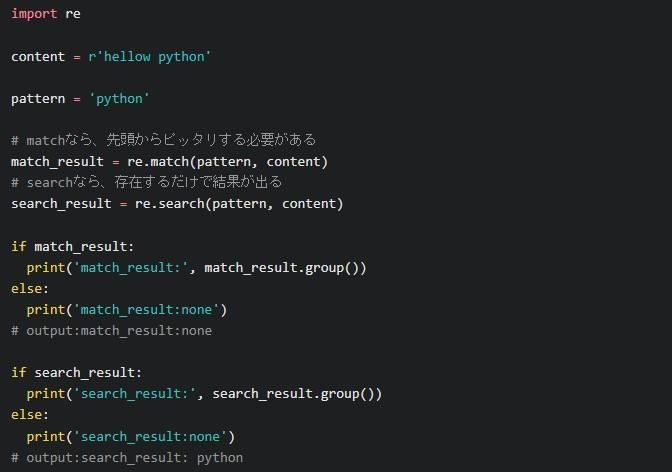
search()
searchは存在するだけで結果を出せるので、柔軟に活用できます。matchは先頭から正確に一致していなければなりませんが、searchはそのようなことを求められません。
findall()
findall()は全結果をリスト型にできます。search()は最初の結果を返すだけなので、findall()の方が多くの情報量を引き出せるでしょう。
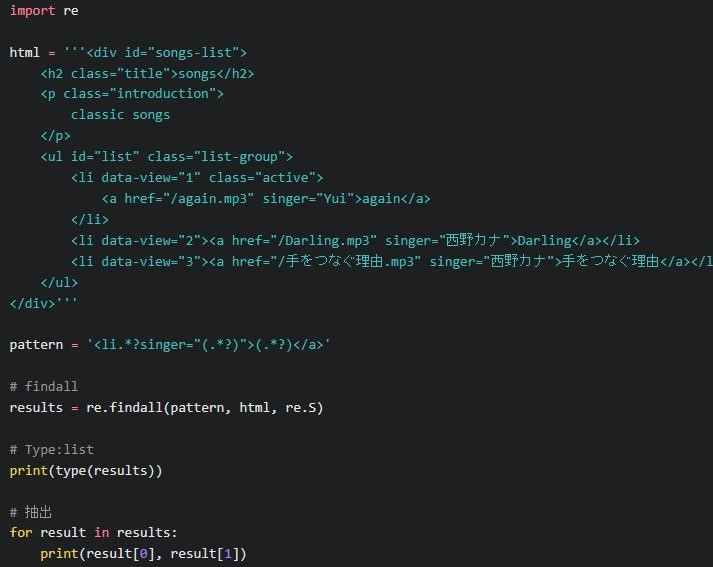
以下は結果の例です。

replaceはsub()で可能
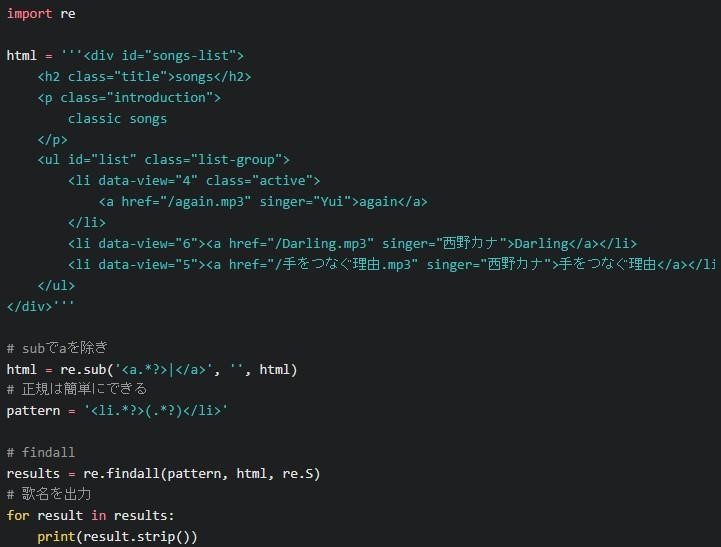
replaceはsub()を使えば、余分な情報を取り除きつつ、正規式を簡単に示せます。
正規表現を行う際の注意点
Pythonで正規表現をするには、さまざまな注意点があります。パターン文字列の定義では、クォーテーションの直前に「r」をつけましょう。またプログラミングでは英数字や記号だけでなく、日本語も扱えます。ここでは2つの注意点を確かめていきます。
パターン文字列の定義では「r」が重要
パターン文字列の定義では「r」が欠かせません。「r」をクォーテーションの前につけると、エスケープシーケンスを無効にできます。正規表現にはバックスラッシュ使用パターンがあるため、作業の効率化のために「r」が必要です。こちらがあれば、あらゆる正規表現がraw文字列として扱われます。たとえば「regex = r’ab*’」という文字列です。このように「r」を忘れなければ、ユーザーの狙いどおりに、パターン文字列を定義できます。
一方「r」をつけなくても、文字列が同じ結果の場合もあります。たとえば特殊シーケンスはエスケープシーケンスとは異なるため、クォーテーションの前に「r」をつけなくても影響が出ません。以上の例外はありますが、基本的にパターン文字列を定義するなら、クォーテーション直前の「r」を習慣づけてください。
日本語も正規表現に使える
Pythonの正規表現では日本語も利用可能です。多くの方はプログラミングでは、英数字や記号しか使わないとイメージするでしょう。確かに実際のプログラミングにおいて、日本語は英数字や記号より使用頻度が少ないといえます。しかし場合によっては、日本語の使用によるコードの成立もあるのです。
たとえば「regex = u’[ぁ-ん]’」という具合です。正規表現で日本語を使うなら、表現パターンをUnicodeに変換しましょう。Python 3.3からは「u’…’」で変換可能で、エラーは生じません。ひらがなやカタカナだけでなく、漢字を使ったパターンも使用可能です。プログラミングでは、日本語を使った正規表現も可能と覚えてください。
まとめ
Pythonでプログラミングを学ぶなら、正規表現を覚えましょう。さまざまなパターンがあり、ひとつずつ覚えていけば、Webサイトやシステムの構築に役立ちます。正規表現によっては、プログラミングの効率化もできるでしょう。たとえば「.*?」は「.*」より少ない文字をマッチするため、正確な検索結果を引き出せるでしょう。
プログラミングを仕事に活かすうえで、正規表現は基本です。今回の記事を参考にしながらマスターしていきましょう。