これからプログラミングを学びたいと考えているなら、まずはPythonの「pandas」に挑戦してみましょう。pandasはデータを効率的に扱えるライブラリで、AIやビジネス分析、日常の業務効率化まで幅広く活用されています。
この記事では、「Python pandas入門」として、pandasの基本的な使い方やインストール方法、実装例までを、初心者でも理解しやすいように基礎から丁寧に解説します。
データ分析の王道ともいえるpandasを身につけることで、学習の幅が広がり、自身の成長やキャリアアップにもつながるでしょう。
Pythonのpandasとは
pandas(パンダス)とは、Pythonでデータを扱う際によく利用されるライブラリ(追加機能)です。表形式のデータを簡単に扱えることが特徴で、Excelのように行と列を使ってデータを整理できます。
pandasでは、主に「Series」や「DataFrame」という仕組みを使い、データの読み込みや抽出、集計を効率的に行えます。たとえば、CSVファイルを数行のコードで読み込み、必要な列だけを取り出すことが可能です。
初心者でも扱いやすく、データ分析や機械学習の前処理など幅広い分野で使われています。
Pythonのpandasでできること

pandasは特に表形式のデータ操作に強く、Excelのような感覚でデータを整理できます。
pandasを使って実現できる代表的な機能をまとめてみましょう。
- CSVやExcelなど外部ファイルの読み込み・書き出し
- 行や列の抽出、条件によるデータの絞り込み
- 欠損値(データが欠けている部分)の確認や補完処理
- データの集計や統計量の計算(平均・合計・最大値など)
- 複数のデータを結合してひとつの表にまとめる
- 日付や時系列データの操作
- グラフ作成ライブラリと連携したデータの可視化
このようにPythonのpandasを使うことで、データ整理から分析の準備までを一貫して行えるようになるのが大きな特徴です。
pandasのインストール方法と環境構築

pandasを使うには、まずPython本体と必要な環境を整える必要があります。ここでは、初心者でも迷わずに進められるように、Pythonやpandasの環境構築手順を解説します。
- Pythonをインストールする
- pandasをインストールする
- Jupyter Notebookをインストールする
- 動作確認をする
①Pythonをインストールする
pandasを利用するには、まずPython本体をインストールする必要があります。Python公式サイトから最新版のインストーラーをダウンロードし、ウィザードに従って進めましょう。

インストール時には、「Add Python to PATH」というチェック項目を必ず有効にしましょう。これを忘れると後の作業でコマンドが使えなくなるため注意が必要です。
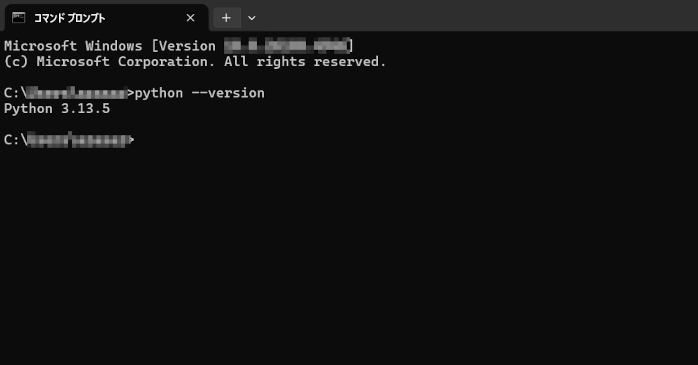
インストール後は、ターミナル(コマンドプロンプト)で次のコマンドを入力してみましょう。
バージョンが正しく表示されていれば、インストール完了です。
②pandasをインストールする
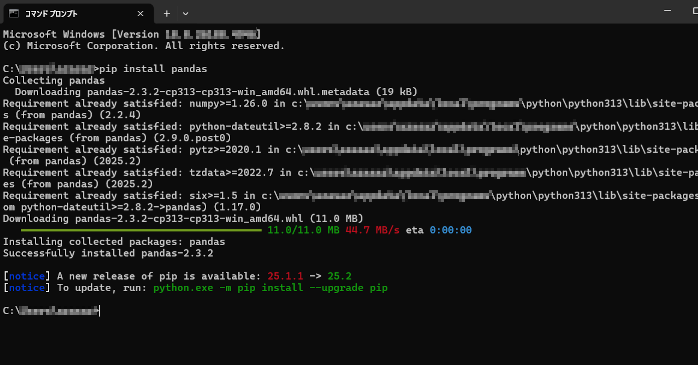
Pythonが使えるようになったら、次にpandasをインストールします。ターミナル(Mac/Linux)やコマンドプロンプト(Windows)を開き、次のように入力しましょう。
自動的に必要なファイルがダウンロードされ、インストールが正常に完了すると、ライブラリが利用可能になります。
③Jupyter Notebookをインストールする
pandasを学習・実践する際におすすめなのが「Jupyter Notebook」です。ブラウザ上でPythonのコードを手軽に実行・保存できます。インストールも簡単にできるので、学習の際にはぜひ導入しておきましょう。
Jupyter Notebookのインストールは、次のコマンドを入力すれば完了です。
インストールが完了したら、実際にJupyter Notebookを起動してみましょう。次のコマンドを入力します。
ブラウザが起動し、コードを書ける画面が表示されればOK。コードを1行ずつ実行して結果を確認できるので、初心者でも理解しやすく効率的に学習できます。
④動作確認をする
最後に、正しくインストールできたか動作確認を行いましょう。Jupyter Notebookを開き、新しいノートブックを作成します。そして、最初のセルに、次のコードを入力して実行してみましょう。
pd.__version__

pandasのバージョンが表示されれば、インストールは成功です。
pandasの基本データ構造【Pythonコード例あり】

pandasには大きく分けて「Series」と「DataFrame」という2つの基本構造があります。ここでは実際のコード例を交えながら、SeriesとDataFrameの使い方を確認していきましょう。
- Seriesの使い方
- DataFrameの使い方
- SeriesとDataFrameの違い
- Pythonのリスト型やdict型との違い
Seriesの使い方
Seriesは、「1列だけのデータ」を格納するための構造です。Pythonのリストに似ていますが、pandasではデータと一緒に「インデックス(行番号のようなもの)」を管理できる点が特徴です。
たとえば、商品IDと売上数のように、1対1で対応するデータを持たせると便利です。サンプルコードを見てみましょう。
import pandas as pd
# リストからSeriesを作成
data = pd.Series([100, 200, 300], index=[“A”, “B”, “C”])
print(data)
上記のコードを実行すると、各データに「A」「B」「C」というインデックスが付与されて表示されます。
DataFrameの使い方
DataFrameは、「複数列を持つ表形式のデータ」を扱うための構造です。ExcelやCSVに近いイメージで、データ分析の中心となります。Seriesが1列だけだったのに対し、DataFrameは複数のSeriesを組み合わせたものと理解するとわかりやすいでしょう。
import pandas as pd
# 辞書型からDataFrameを作成
data = {
”商品”: [“りんご”, “みかん”, “ぶどう”],
”価格”: [100, 80, 300],
”在庫”: [50, 100, 20]}
df = pd.DataFrame(data)
print(df)
上記を実行すると、行と列を持つ表が表示されます。これによって「価格の列だけ取り出す」や「在庫が30未満のデータだけ抽出する」といった操作が簡単に行えます。
SeriesとDataFrameの違い
SeriesとDataFrameはどちらもデータを管理するための構造ですが、用途や特徴に違いがあります。初心者は「1列=Series」「表全体=DataFrame」と覚えると混乱しにくいです。
両者の性質を正しく理解しておかないと「どちらを使うべきか迷う」という場面が出てくるため、違いを分かりやすく表にまとめました。
| 項目 | Series | DataFrame |
|---|---|---|
| データ構造 | 1次元(1列のみ) | 2次元(行と列の表) |
| インデックス | あり(ラベル付きでアクセス可能) | 行インデックス+列名あり |
| データの扱い | 1つの項目に特化 | 複数項目をまとめて管理 |
| 作成方法の例 | pd.Series([1,2,3]) | pd.DataFrame({“A”:[1,2,3],”B”:[4,5,6]}) |
| 利用シーン | 単一のデータ列を分析するとき | 表形式で複数の項目を扱うとき |
このような両者の違いを意識することで、pandasの基本操作をより理解しやすくなるでしょう。
Pythonのリスト型やdict型との違い
Pythonでデータを扱う場合、標準機能としてリスト型やdict型を利用することができます。しかし、大量のデータを処理したり集計や可視化を行ったりする際には限界があり、pandasのSeriesやDataFrameを使う方が圧倒的に効率的です。
それぞれの違いも比較してみましょう。
| 項目 | リスト(list) | 辞書(dict) | pandas.Series / DataFrame |
|---|---|---|---|
| データ構造 | 単純な順序付き配列 | キーと値のペアの配列 | 行・列を持つ表形式(Seriesは1次元) |
| アクセス方法 | インデックス番号のみ | キー指定のみ | インデックス番号+ラベル名 |
| 機能性 | データ保存・参照のみ | キーごとの参照は可能 | 欠損値処理・集計・統計・フィルタリングなど分析機能が豊富 |
| 可視化との連携 | 自前で処理が必要 | 自前で処理が必要 | MatplotlibやSeabornと簡単に連携可能 |
| 大量データの扱いやすさ | 不向き | 不向き | 最適化されており高速 |
まとめると、リストやdictはシンプルで軽量なため小規模データの管理に向いています。一方、pandasはデータ分析に特化しており、統計処理や可視化との連携など、本格的なデータ処理には欠かせない存在です。
初心者にとっては違いがやや分かりにくいかもしれませんが、まずは「データ処理をするならpandasを使うのが王道」と理解して学習を進めましょう。
独学するのは不安があるな…という方は、丁寧な進行と実務に即したカリキュラムで、基礎から応用までハンズオンで学べる以下のようなセミナーの受講もおすすめです。気になる方は、どのようなカリキュラムかチェックしてみてください。
Pythonのリストについては、こちらで詳しく解説しています。
pandasでよく使われる基本操作【Pythonコード例あり】

pandasはデータを扱うための便利な機能が豊富に用意されています。ここでは、初心者がまず覚えておきたいpandasの基本操作をご紹介します。
- データの読み込み
- データの抽出・フィルタリング
- データの並び替え
- グループ化と集計
①データの読み込み
pandasは、外部ファイルからのデータ取り込みが得意です。CSVやExcelのファイルを数行のコードで簡単に読み込めます。
import pandas as pd
# CSVファイルを読み込む
df_csv = pd.read_csv(“sample.csv”)
# Excelファイルを読み込む
df_excel = pd.read_excel(“sample.xlsx”)
pd.read_csv()を使えばCSVファイルを、pd.read_excel()を使えばExcelファイルを読み込めます。読み込んだデータはDataFrameとして管理されるので、そのまま抽出や集計に使えます。
②データの抽出・フィルタリング
pandasを使えば、条件に合ったデータを取り出す操作も簡単です。列を指定して取り出したり、特定の条件を満たす行だけを抽出したりできます。
# 「価格」列だけを抽出
df[“価格”]
# 「在庫」が50以上の行を抽出
df[df[“在庫”] >= 50]
1つ目のコードでは「価格」列だけを、2つ目のコードでは「在庫が50以上」という条件を満たす行だけを抽出しています。このように、必要なデータだけを効率よく扱えるのが大きな特徴です。
③データの並び替え
pandasを使えば、データを昇順や降順に並び替えることも簡単にできます。
# 価格を昇順に並び替え
df.sort_values(“価格”)
# 在庫を降順に並び替え
df.sort_values(“在庫”, ascending=False)
上記は、「価格」を昇順に、「在庫」を降順に並び替えている例です。「ascending=False」を指定することで、降順になります。分析したい順序にデータを整理したい場面で役立ちます。
④グループ化と集計
pandasを使えば、同じ値ごとにデータをまとめ、平均や合計などの集計を行う処理も可能です。カテゴリー別の売上や商品別の在庫管理に役立ちます。
# 商品ごとの在庫合計を計算
df.groupby(“商品”)[“在庫”].sum()
# 商品ごとの価格平均を計算
df.groupby(“商品”)[“価格”].mean()
ここでは、「商品」ごとに在庫の合計や価格の平均を出しています。「groupby()」を使うことで、カテゴリ単位での集計がとても簡単に行えるのが魅力です。
Pythonのpandasを活用した事例

pandasはエンジニアや研究者だけでなく、ビジネスの現場でも広く使われています。ここでは、幅広いシーンで活用されているpandasの事例をご紹介します。
- 業務データの集計・分析
- マーケティング分析
- 金融・時系列データの処理
- 機械学習の前処理
- ログ・アンケートデータの解析
①業務データの集計・分析
会社の売上や在庫データを月ごとや商品ごとに整理するのは、どの業種でも必要な作業です。従来はExcelで時間をかけていた処理も、pandasなら数行のコードで効率的に行えます。
たとえば「商品別の売上ランキングを作る」「月ごとの在庫推移を確認する」といった集計は、業務改善や意思決定に直結します。日常業務をよりスピーディーに進められるため、初心者でも「業務の時短ツール」としてすぐに活用できる分野です。
②マーケティング分析
顧客の年齢や地域、購買履歴といったデータは、マーケティングの分野では重要な基盤です。ここにpandasを使えば、たとえば「20代女性はどの商品をよく買うのか」「地域ごとの売れ筋商品は何か」といった傾向を素早く抽出できます。
Excelよりも柔軟にフィルタリングや集計ができるため、ターゲットを絞ったキャンペーン施策にも効果的です。
③金融・時系列データの処理
株価や為替レートのような時間とともに変化するデータを扱うときにも、pandasが役立ちます。たとえば「株価の移動平均を計算する」「一定期間ごとの値動きを比較する」といった処理は、pandasの時系列データ機能で簡単に実現できます。
金融に関わる業務だけでなく、売上推移やアクセス数のように時間軸のあるデータを扱う場面でも役立つため、幅広い分野に応用可能です。
④機械学習の前処理
機械学習を行う際には、モデルにデータを渡す前に整形する「前処理」が欠かせません。特に欠損値(データが抜けている部分)の処理や不要な列の削除、数値化や正規化といった作業は、pandasを活用することで効率的に進められます。
精度の高い分析やAIモデルの構築をしたい方、さらに機械学習に興味がある初心者も、まずはpandasを学んでおくと安心です。
Pythonで機械学習を学びたいという方は、こちらも参考にしてください。
⑤ログ・アンケートデータの解析
Webサイトのアクセスログやアンケートの回答データは、通常CSV形式で蓄積されます。そのため、pandasを使うことで、「どのページがよく見られているか」「回答者の傾向はどうか」といった情報を素早く整理でき、サイト改善や顧客理解に直接役立てられます。
プログラミング初心者でも身近なCSVデータを題材にすぐ試せるため、「学んだらすぐ役立つ!」と実感できる分野と言えるでしょう。
pandasを体系的に学ぶなら「Python基礎セミナー講習」

独学でPythonやpandasを学ぼうとすると、基礎文法や環境構築、ライブラリの使い方などでつまずいてしまう方も多いのではないでしょうか。そこでおすすめなのが、「Python基礎セミナー講習」です。
「Python基礎セミナー講習」は、Pythonの基礎から実務に直結する応用まで体系的に学べる実践的なセミナーです。基礎文法や環境構築をはじめ、pandasを使ったデータ分析や可視化、AIプログラムの実装、さらにExcel処理の自動化まで、実務で役立つ応用スキルを習得できます。
特にpandasに関しては、データの読み込み・整形・集計・可視化まで一連の流れを実践的に学べるので、業務や研究ですぐに活用できる力が身につきます。「Pythonを基礎から学びたい」「データ分析を実務で活かしたい」という方は、ぜひ受講をご検討ください。
| セミナー名 | Python基礎セミナー講習 |
|---|---|
| 運営元 | GETT Proskill(ゲット プロスキル) |
| 価格(税込) | 29,700円〜 |
| 開催期間 | 2日間 |
| 受講形式 | 対面(東京・名古屋・大阪)・ライブウェビナー・eラーニング |
Pythonでpandasを学んでデータ分析を始めよう
pandasは、データの読み込みから整形、集計、可視化までをシンプルなコードで実現できる強力なライブラリです。Pythonのリストやdictと比べても柔軟で効率的な処理が可能で、業務データの分析やマーケティング、さらには機械学習やAIの基盤づくりにまで幅広く活用されています。
初心者にとっても、身近なCSVファイルやExcelデータを扱うところから始めればすぐに実践できるのが魅力。まずはpandasを学び、データ分析の第一歩を踏み出して、自分の可能性を広げていきましょう。