
さて今回は、物体検出の5つの代表的なアーキテクチャの特徴についてご紹介していきます。
物体検出とは、一言でいえば、「画像のどこに何があるか」を予測することです。
画像分類では、画像が「何か?」までの識別になっているのに対し、物体検出では「どこに?何が?」までを識別していきます。
そのため、その画像が何かにあたるクラスに加え、バウンディングボックスと呼ばれる対象物を囲む矩形のボックスを使用しながら、「どこに?」を抽出するタスクが増えるというわけです。
そこでまずは、その「どこに?何が?」を識別していく物体検出とは何かを見ていきます。
その後、代表的なアーキテクチャを見ていき、物体検出について理解を深めていきましょう。
物体検出とは
物体検出(Object Detection)とは、1つの画像の中に複数の物体が写っている際に、物体の位置とその物体のクラスを予測する手法です。
この物体検出は、画像のどこに何があるのか予測するため、教師データは物体のあるバウンディングボックス(座標、幅、高さ)と、それぞれどんな画像を示しているかというクラスになります。
物体検出では、入力画像に対して領域探索・特徴量抽出などをしていくのですが、どこまで自動化できるかで大きく二つの手法があります。
- NOT End-to-End Learning(下図中段)
- End-to-End Learning(下図下段)
になります。
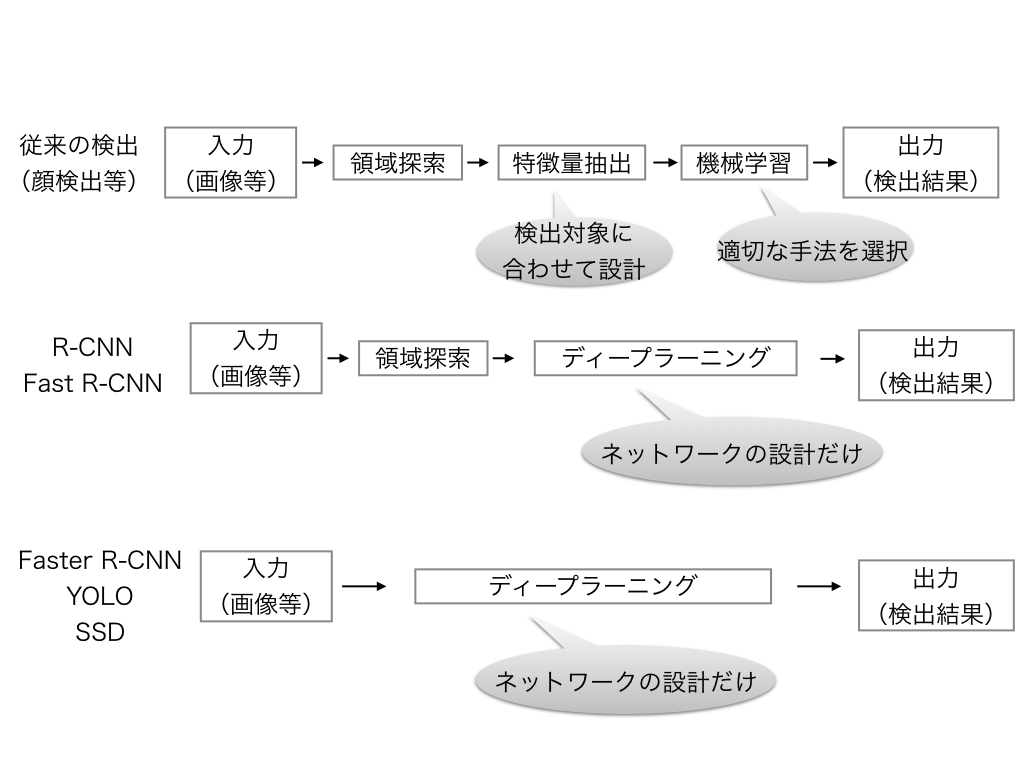
出典:https://karaage.hatenadiary.jp/entry/2018/03/28/073000
先ほどの教師データを作るツールとしては、「アノテーションツール」と呼ばれるツールが一般的に使われており、物体の位置はバウンディングボックス(矩形領域)で表現していきます。
このバウンディングボックスでは、下記の3項目が予測する対象になってきます。
- クラス名
- バウンディングボックスのXY座標
- バウンディングボックスの幅・高さ
以上3点に着目して物体の位置を表現していきます。
下図のような「アノテーションツール」を使用していくことで、物体検出を行います。
代表的なアノテーションツールとしては、labellmgやLabelbox、VoTTなどあります。
他にも多種多様の特性があるため、ご自身で比較しながら試用してみてください。

出典:https://qiita.com/shu-yusa/items/d19ea57e3cf9c4dbdce2
それでは、続いて本題でもある、物体検出で使用されている5つの代表的なアーキテクチャについて見ていきましょう。
①~R-CNN~
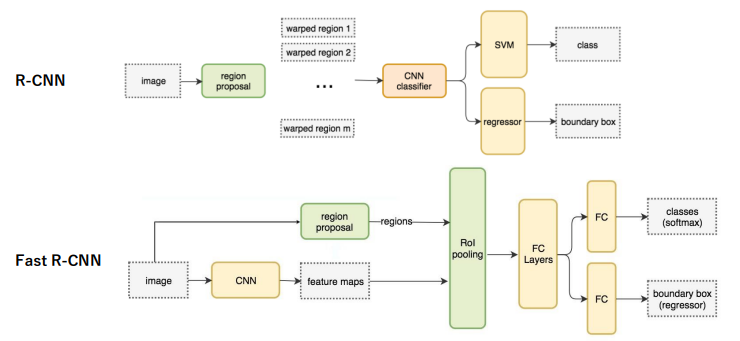
まず初めにご紹介していくのは、R-CNNと呼ばれるアーキテクチャになります。
このR-CNN(Region CNN)は、領域探索と画像認識するアルゴリズムを組み合わせて物体検出をするアーキテクチャになります。
領域探索では、Selective Searchと呼ばれるアルゴリズムを使用することで領域候補の検索をしていきます。
画像認識では、Non Maximum Supressionと呼ばれるアルゴリズムを使用して、IoU(評価指標)も元に画像を認識していきます。
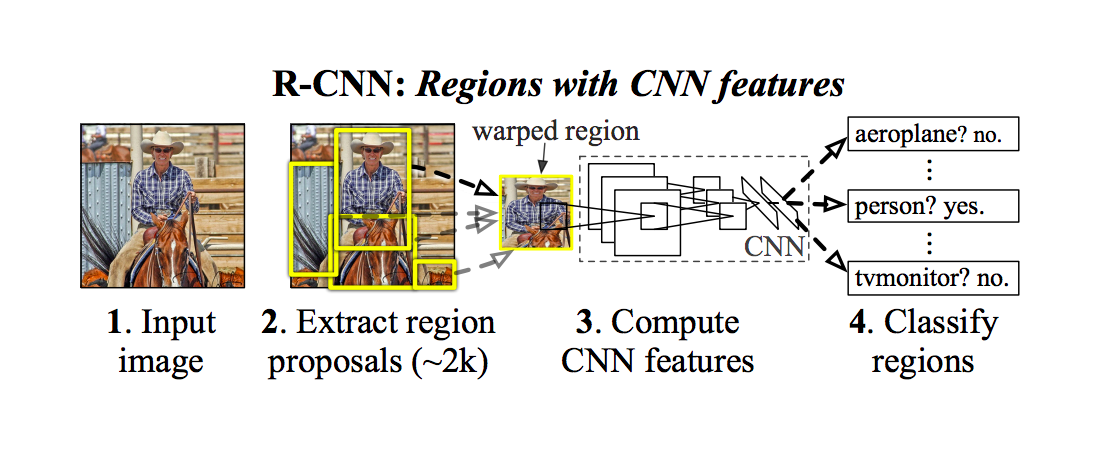
上記に示したように、Selective Search・Non Maximum Supressionの2つのアルゴリズムを使用しているわけですが、それぞれどのような計算処理が行われているのでしょうか。
詳しく見ていきましょう。
Selective Search
冒頭で説明したこのSelective Searchは、RoI(候補領域)を見つけるアルゴリズムの1つで、領域探索(Region Proposal)する際に使用されています。
どのように領域を探していくかというと、まずは画像の特徴量(色合いや濃淡勾配など)を元に画像をいくつかの領域に分けていきます(下左図中段)。
次に、類似度を元に領域を結合していき、 程よい大きさになるまで結合を続けていきます(下左図下段)。
最後に、分けた領域を元に候補となる領域、つまりRoIを生成していきます(下右図)。
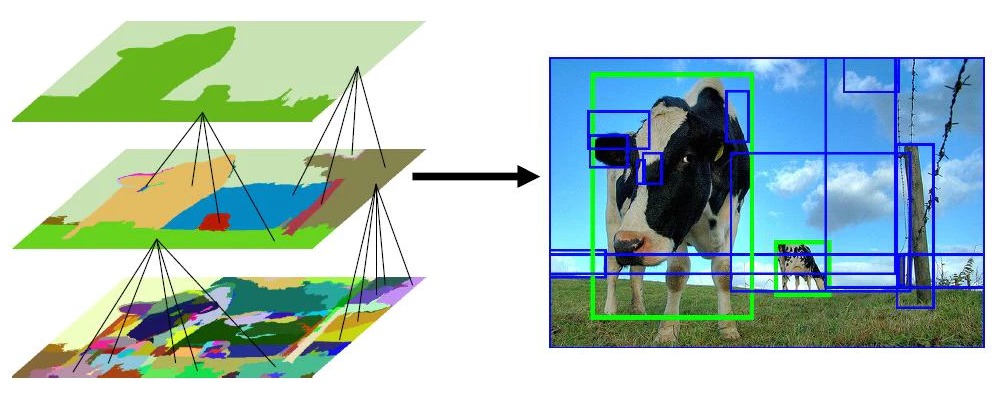
出典:https://qiita.com/Almond/items/7850cf81903fbe2a2c6c
Non Maximum Supression
続いて、画像認識の際に使用されるアルゴリズムのNon Maximum Supression(NMS)を見ていきましょう。
このアルゴリズムでは、IoUと呼ばれる評価指標を基準に画像を認識していきます。
IoU(Interesection over Union)とは、認識された二つの領域が 「どれくらい重なっているか」を示しており、物体検出を行う際の評価指標になります。2つの領域とは、正解領域(実際の対象物の領域)と予測領域(対象物と予想した領域)のことで、この2つがどのくらい重なっているかを0~1の値で評価します。
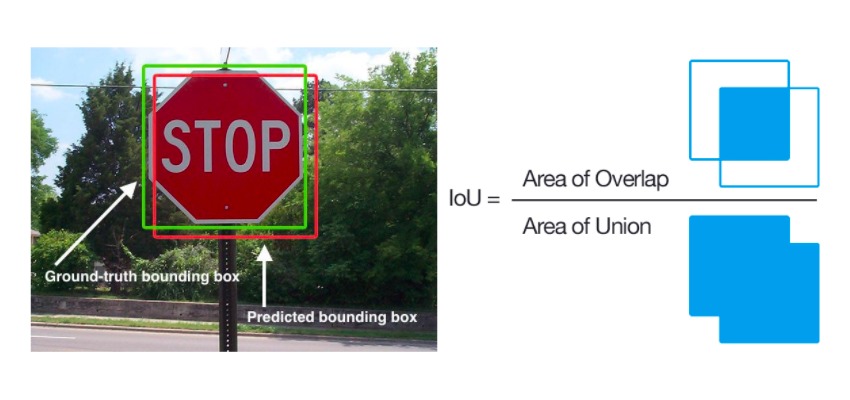
出典:https://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
では、画像認識に使用されるアルゴリズムであるNon Maximum Supression(NMS)ですが、どのような計算処理が行われているのでしょうか。
このNon Maximum Supressionは、物体検出を行った際に、1つの物体に対して複数回物体検出された場合に使用されます。
領域の一致具合の指標であるIoU(Intersection over Union)を元に、同じラベルかつ被りがある領域同士を、IoU値の閾値(IoU=0.3など)を設けて領域をSupression(抑制)していきます。
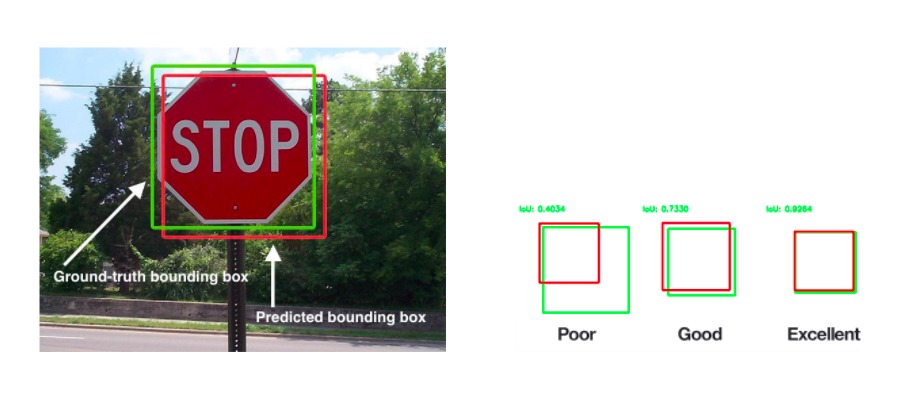
出典:https://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
ここまでR-CNNの概要を見てきましたが、欠点がいくつがあります。
まず、領域探索(Region Proposal)が従来技術であるため、認識精度が低いことや学習が煩雑(CNNの学習・fine-tuning・SVMの学習・線形回帰の学習) です。
また約2,000個の認識領域に対してそれぞれCNNを実行しているため、実行時間が遅い(1枚の画像に対し、10秒~45秒)ことが挙げられます。
これらを克服したアーキテクチャが、次のFast R-CNNになります。
②Fast R-CNN
Fast R-CNNとは、前述のR-CNNを改良したモデルとなっており、画像全体の特徴抽出を一回のみ実行することによって演算時間を大幅に早めたアーキテクチャになります。
具体的には、VGG16を用いたR-CNNより「9倍の学習速度・213倍の識別速度」を実現しています。
Fast R-CNNには、RoI poolingと、Multi-task Lossというアイデアが採用されたことで、演算を早めることを実現しました。
具体的な計算手順としては、まず畳み込み層までを使って任意サイズの入力画像の特徴マップを計算します。
次に、Selective Searchで求めた候補領域(RoI)を特徴マップ上に射影していきます。
最後に、特徴マップ上で射影されたRoIをRoI Poolingし、全結合層を何段か挟んだ後に、クラス分類問題・矩形回帰問題を同時に解くことで検出速度を早めることが出来ました。
では、Fast R-CNNに使用されているRoI PoolingとMulti-task Lossの2つの仕組みについて詳しく見ていくことにしましょう。
RoI Pooling
まずRoI Poolingとは、縦横比が異なる可変長サイズの入力に対して固定サイズ(1×1・3×3・5×5など)の特徴マップを得ることを目的としたプーリングのことです。
RoI(Region of Interest)とは、関心領域とも呼ばれており、検出していきたい画像の部分領域のことで、各セクションごとに最大値を見つけ大まかな特徴抽出を行います。
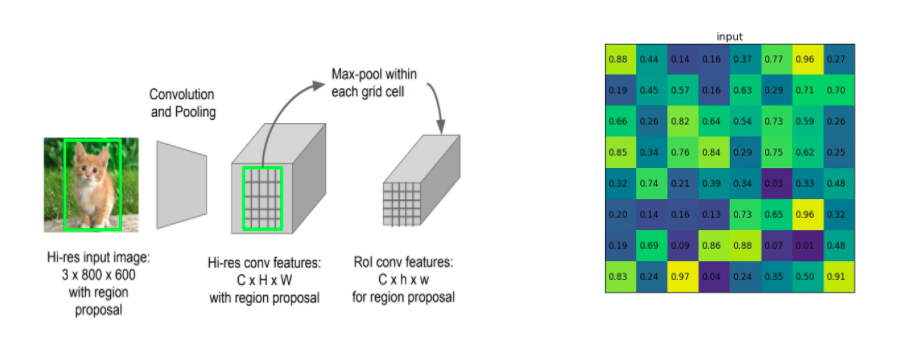
出典:https://blog.negativemind.com/2019/02/14/general-object-recognition-fast-r-cnn/
出典:https://github.com/deepsense-ai/roi-pooling
Multi-task Loss
続いてMulti-task Lossとは、物体のクラス分類とバウンディングボックスの回帰という2つのタスクの誤差を同時に考慮できる損失関数のことです。
Multi-task Lossを最小化するようニューラルネットワークを学習することで、2つのタスクを同時に習得させることができます。
このMulti-task Lossを導入したことにより、誤差逆伝播が可能になり、ネットワーク全てのパラメータの更新に繋がりました。
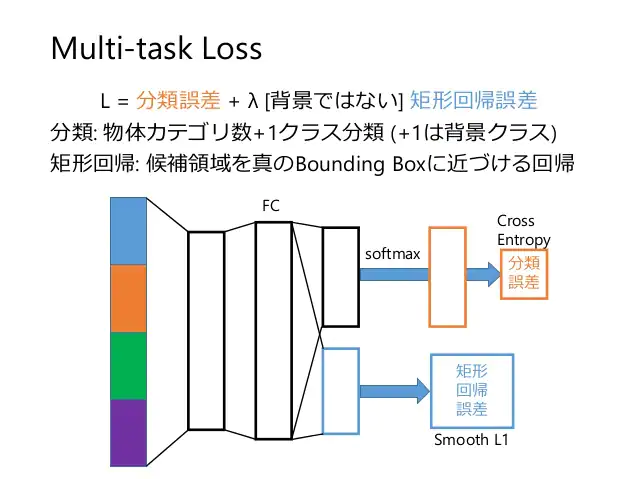
ここまで、Fast R-CNNを見てきたわけですが、まだまだ改善の余地がありそうです。
なぜなら、Selective Searchも従来技術にあたるため、計算量が膨大であることに変わりません。
また、認識精度も低く計算速度も遅くなってしまいます。
それらを改良したモデルが次にご紹介していくFaster R-CNNになります。
③Faster R-CNN
Faster R-CNNは、先ほどのFast R-CNNの検出速度を早めたモデルになるためFasterという名前になっています。
このFaster R-CNでは、物体候補(Region Proposals)を検出するアルゴリズムに、Region Proposal Network (RPN) というネットワークを使用することで、物体検出では初めてEnd to Endで学習できるようにしたアーキテクチャになります。
畳み込みレイヤーと分類/回帰ができるネットワーク(RPN)で構成されているのが特徴です。
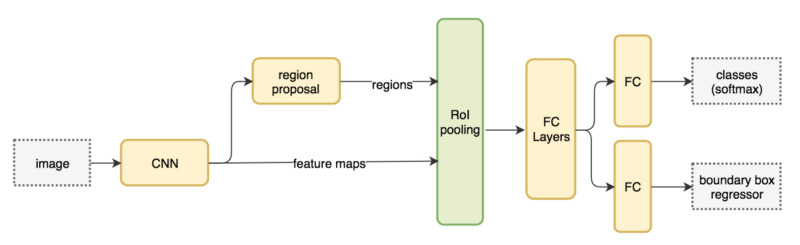
出典:https://qiita.com/arutema47/items/8ff629a1516f7fd485f9
具体的な計算処理としては、まず、畳み込み層を何段かかけた後の特徴マップに対して、n × n のウィンドウをスライディングさせます。
各スライディングウィンドウの中央をアンカーとして、k個のバウンディングボックス(Anchorボックス)を作成していきます。
ここでk個の候補領域を推定するために、以下2つの全結合層へ分岐していきます。
1つ目がcls layerで、k個の各候補領域がオブジェクトか、背景かの確率を推定した2k次元のスコア が出力されます。
もう1つは、reg layerでk個のバウンディングボックスのx座標、y座標、幅、高さを表す4次元のスコアが出力されるいくつかのアンカーボックスにおいて、相対的なδx、δyの ようなオフセットを予測します。
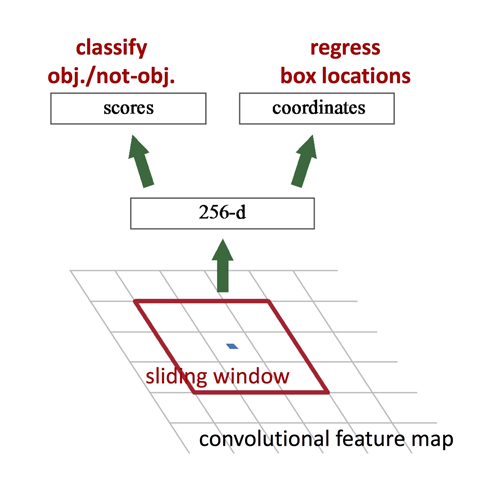
出典:https://jamiekang.github.io/2017/05/28/faster-r-cnn/
Faster R-CNNは、End-to-Endのモデルになりますが、計算処理に使用されているAnchor・Region Proposal Network(RPN)は、それぞれどのような仕組みなのでしょうか。
Anchor
Anchorとは、スライディングウィンドウに対して、物体の形状は正方形に収まらない場合が多いために用意するk個の検出矩形パターンのことです。
Anchorは、スライディングウィンドウの中心を基準に設定され、下記の論文では、128×128、256×256、512×512の三種類のアンカーボックスと、1:1, 2:1, 1:2 の三つのアスペクト比を使用しています。
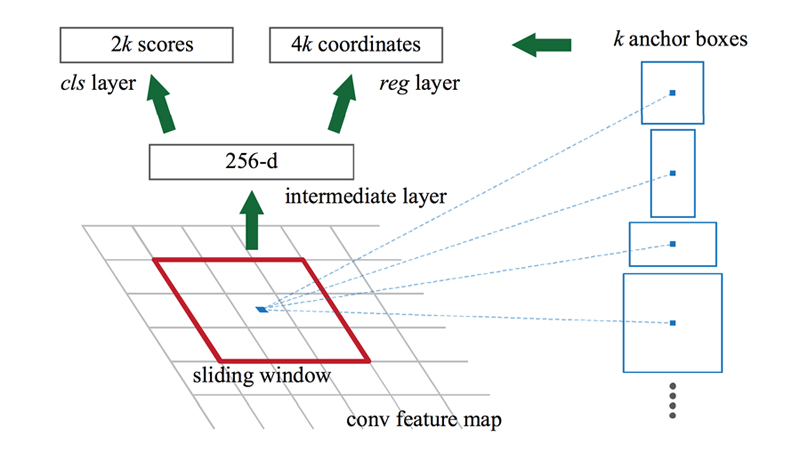
出典:https://blog.negativemind.com/2019/02/20/general-object-recognition-faster-r-cnn/
Region Proposal Network
Region Proposal Network(RPN)とは、画像内から物体領域の抽出を行うネットワークになります。
Fast R-CNN以前ではSelective Searchを使用していたため、物体検出の精度と時間がかかっていました。
RPNでは、画像全体の特徴マップから、予め決められたk個の固定枠(Anchor)を用いて特徴を抽出していきます。
その特徴マップをRPNの入力とし、物体かどうかを表すスコア(図中cls layer)と物体の領域(図中reg layer)の2つを同時に出力します。
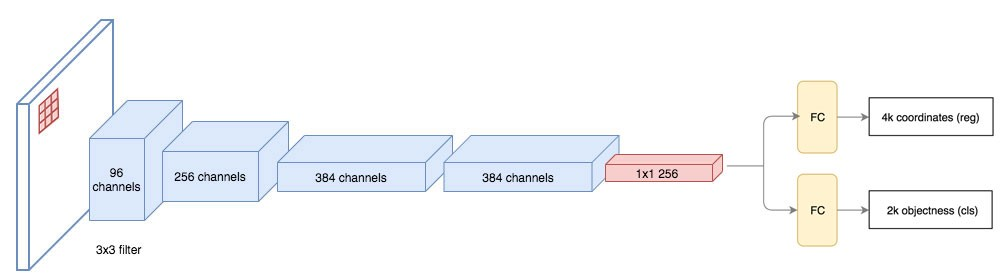
ここまでFaster R-CNNの概要を見てきましたが、領域候補を分類問題として扱っているため、処理速度をさらに高める余地はありそうです。
これまでのR-CNN・Fast R-CNN・Faster R-CNNは共に、徐々に処理速度は向上してはいるものの分類問題の範疇を超えていません。

出典:http://cs231n.stanford.edu/
そこで改良されたのが、次にご紹介するYOLOと呼ばれるアーキテクチャになります。
このYOLOは、領域候補を分類問題ではなく回帰問題として処理していくことで検出速度を早めることを可能にしました。
④YOLO
YOLO(You Only Look Once)は、領域候補を回帰問題としてで推定していくアーキテクチャですが、領域候補の探索とクラスの識別を同時に行うことで、リアルタイムに近い処理速度を実現しています。
YOLOという名前の由来は、「You Only Look Once」という英文の頭文字をつなげて作られた造語で、日本語に翻訳すると「一度見るだけで良い」という意味を持っているアルゴリズムです。

出典:https://blog.csdn.net/qq_24502469/article/details/105121275
具体的にどのような構造かというと、24層の畳み込み層・4層のプーリング層で画像から特徴を抽出し、2層の全結合層で物体のバウンディングボックスと物体の種類の確率を推定していきます。
つまり、物体検出を分類問題ではなく、回帰問題としてモデル化しているというわけです。
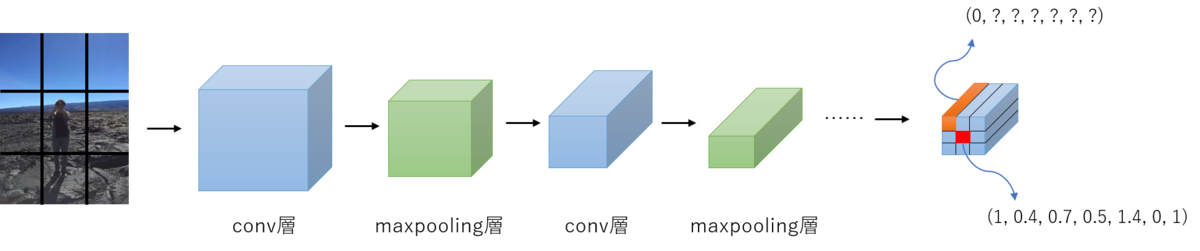
これまでにご紹介してきたFaster R-CNN以前では、領域候補の生成を分類問題として、どんな物体なのかという流れで物体検出を行っていましたが、YOLOでは領域探索とクラス分類を同時に実行し、回帰問題として物体の推定を行います。
では、YOLOがどのような仕組みによって物体検出を行っているのか見ていきましょう。
grid cell
YOLOではまず、入力画像に対して正方形にリサイズしていく処理を行います。
候補領域検出を行わない代わりに、正方形の画像全体をN×N(※N:任意の数)のgrid cell(グリッド領域)に分割していきます。
最後にそれを畳み込みニューラルネットワークの入力とします。

出典:https://zhanghanduo.github.io/post/yolo1/
class probability map
続いて行う処理は、入力画像をS×Sの領域に分割し、その領域内の物体の種類(クラス)の推定していきます。
このクラス・パビリティ(class probability)では、各grid cell単位が、ある特定のクラスであるかを確率 (条件付き確率)で推定しています。
この数値が高いほど、コンピューターの行ったクラス分けが何かを意味しています。
例えば下図では、車=0.74なので、そのgrid cell内には車が写っていることを示しています。
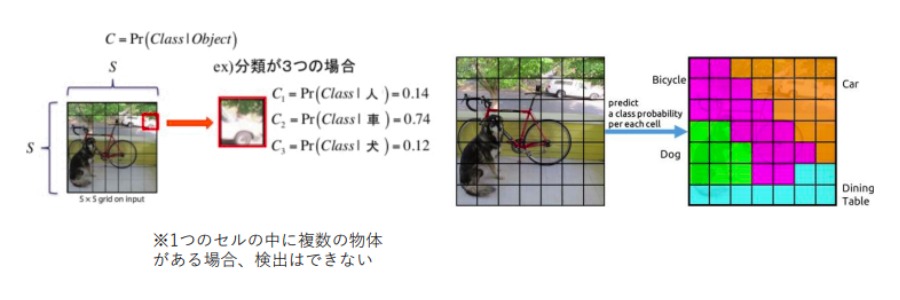
出典:https://www.slideshare.net/ssuser07aa33/introduction-to-yolo-detection-model
Bounding Box
上記のclass probabilityと共に行っていく処理は、バウンディングボックスの推定です。
分割した各grid cellに対して、B個のバウンディングボックスを推定していきます。
1つのバウンディングボックスにつき、中心座標値(x, y)・幅/高さ(w, h)・物体であるコンフィデンス・スコア(背景なら0、物体なら1の確率)、以上計5つの値が出力されます。
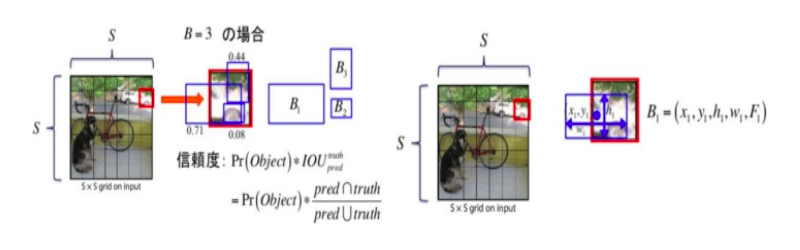
以上、Bounding Box・Class probability mapを見てきましたが、最後にこの2つを結合し物体を検出していきます。
これらを結合させることにより、どんな物体があるのかを推定することが出来ます。
これらのバウンディングボックスには重複領域が多くあるため、最終的に、信頼度スコアの高いバウンディングボックスを基準にNMS(Non-Maximum Suppression)で選別していきます。
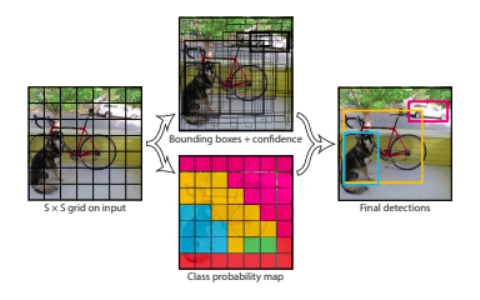
出典:https://arxiv.org/pdf/1506.02640.pdf
YOLOの出力層では、1つのgrid cellにつきB × 5 + C個の出力となり、 全体の出力はS × S × (B × 5 + C)個と表せます。 論文の例では、 S = 7 B = 2 C = 20: Pascal VOCデータセットの 20種類のラベルを使用しています。
YOLOのコスト関数

ここまでYOLOの概要を見てきました。
YOLOの大きな特徴は、検出と識別を同時に行うことで処理速度を早めた点にあります。
画像全体に対して特徴マップを生成していくため、汎化制度の高い識別アーキテクチャになります。
しかし、小さい画像の検出は不得意な部分があり、密接した対象の識別には向いていません。
そこでYOLOと競うように登場したモデルが、これからご紹介するSSDになります。
⑤SSD
SSD(Single Shot MultiBox Detector)は、Faster R-CNNと同等の精度を実現している、小さい物体の検出にも対応したモデルになっています。
また、比較的低解像度でも高精度に検出できるアーキテクチャになります。
様々なスケールの特徴を利用し、アスペクト比ごとに識別することで、高精度の検出率を達成しています。
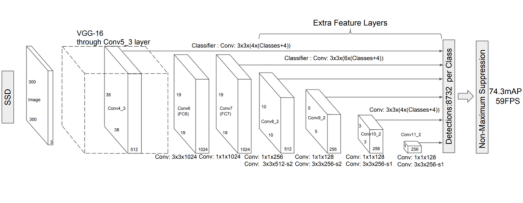
出典:https://arxiv.org/pdf/1512.02325.pdf
SSDは、YOLOと同様にバウンディングボックスを推定していくのですが、YOLOとの違いは、YOLOが元画像を等間隔に区切ったgrid cellにより、バウンディングボックスを推定するのに対し、SSDでは、特徴マップに対してデフォルトボックスと呼ばれる矩形パターンを配置することでバウンディングボックスを推定する点になります。
SSDに使用されているこのデフォルトボックスとは一体どのような役割をしているのでしょうか。
Default box
さてこのDefault box(デフォルトボックス)で、バウンディングボックスの推定していくわけですが、どのような役割をしているのでしょうか。
このデフォルトボックスは、Faster R-CNNのAnchorのように、検出する物体の領域サイズ・アスペクト比のバリエーションに対応するために複数の矩形パターンを使用します。
Faster R-CNNと同様、ボックスの位置とサイズのオフセットを学習していきます。
そうすることで、密接した対象物があった場合にも対応することが出来るようになりました。
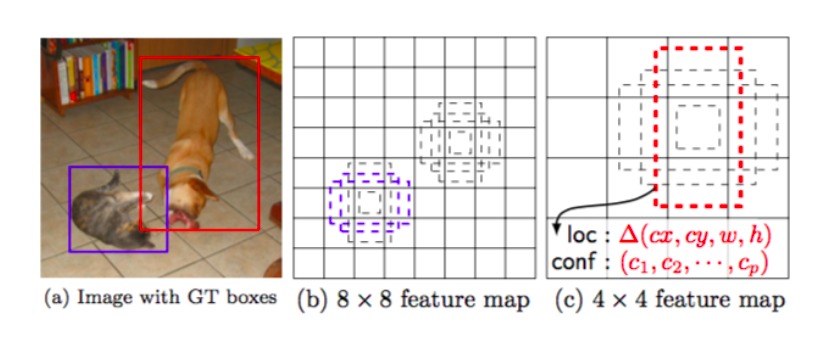
出典:https://qiita.com/hiroqik/items/2f602913a0363f2c9ee9
Default box(デフォルトボックス)ごとに物体領域のバウンディングボックスの位置・サイズのオフセット値(loc:localization loss)・物体のクラス分類の信頼度(conf:confidence loss)を推定し、誤差を求めることで、適切なオフセットを生成しています。
オフセットとは、Default boxを基準としたバウンディングボックスの相対的な位置・サイズのことです。
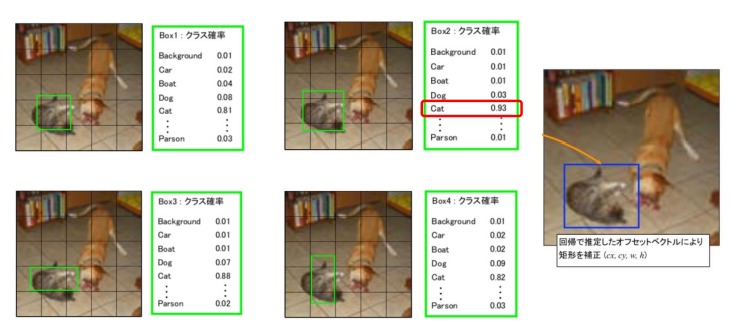
上記のように、デフォルトボックスごとに対象物が何であるかを確率に変換して検出していきます。
徐々にこのデフォルトボックスの位置をズらしていき、オフセットを補正することで対象物の最終的な推定をしています。
まとめ
さて、いかがだったでしょうか。
これまで物体検出における、代表的な5つのアーキテクチャについてご紹介させていただきました。
まず物体検出には、
- NOT End-to-End Learning
- End-to-End Learning
の大きく2つの手法に分けられていました。
NOT End-to-End Learningには、R-CNNとFast R-CNNの2つのアーキテクチャがありました。
次に、End-to-End Learningには、Faster R-CNN・YOLO・SSDの3つのアーキテクチャがありました。
領域探索・クラス識別をどこまで自動化出来るかが焦点になっていましたが、以下にこれまで見てきたアーキテクチャをまとめましたので、参考にしてみてください。
物体検出における代表的な5つのCNNネットワーク
| CNNネットワーク名 | 概要 | 物体検出の手法 |
|---|---|---|
| R-CNN | 領域探索と画像認識するモデルを組み合わせて物体検出するアーキテクチャ。 | NOT End-to-End Learning |
| Fast R-CNN | R-CNNを改良し、演算時間を大幅に早めたアーキテクチャ。 | NOT End-to-End Learning |
| Faster R-CNN | Fast R-CNNを改良し、物体候補を検出するアルゴリズムにRegion Proposal Networkを使用することでEnd to Endで学習できるようにしたアーキテクチャ。 | End-to-End Learning |
| YOLO | バウンディングボックスとクラスの確率回帰問題として検出を行うことで、リアルタイムに近い処理速度を実現したアーキテクチャ。 | End-to-End Learning |
| SSD | 処理速度がYOLO v1よりも高速で、Faster R-CNNと同程度の認識精度をもつアーキテクチャ。 | End-to-End Learning |






