ニューラルネットワーク
ニューラルネットワークとは
ニューラルネットワークとは、コンピュータで神経細胞(脳)の動きを再現しようとしたもので、別の神経細胞から受け取った信号を、ある閾値を超えたときだけ次の神経細胞へ伝達する、という仕組みを数理モデルとしたのが始まりです。このモデルはMcCulloch-Pittsモデルと呼ばれ、このモデルで考案された神経細胞の接続モデルを形式ニューロンと呼びます。
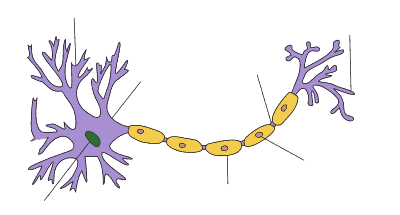
画像参照:Wikipedia
この形式ニューロンを複数つなぎ構成されたものを、ニューラルネットワークと呼びます。
また、形式ニューロンを並列に並べて構成したものを層といい、層を複数重ねて多層のニューラルネットワークもしくはディープニューラルネットワーク(DNN)と呼んでいます。
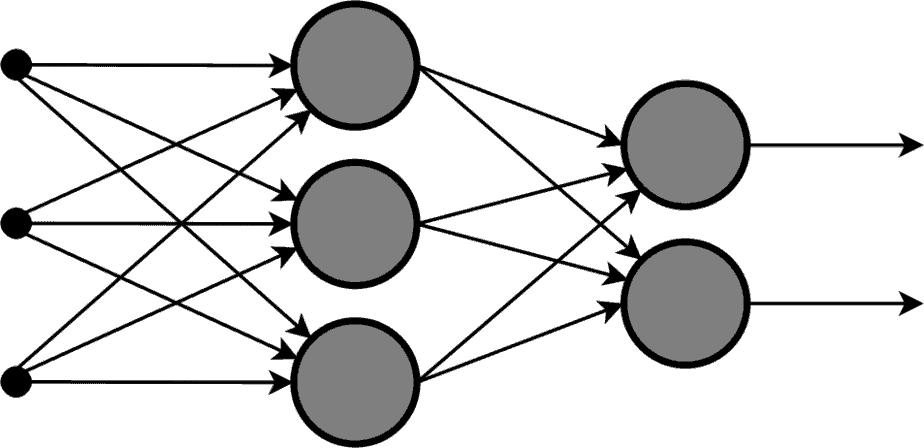
画像参照:Wikipedia
ニューラルネットワークの特性としては、分散性、局所性、荷重和、可塑性、汎化性があげられ、この特性を生かして、伝播、学習、自己組織化といった機械学習に必要な要素を支えています。
初期のニューラルネットワークにおいて、重要な役割を果たしたのが、パーセプトロンと呼ばれる機械学習で、入力層、中間層、出力層の3つの部分からなり、入力層と中間層の間はランダムに接続されている状態です。
入力層に外部から信号が与えられると、中間層は入力層からの情報を元に反応し、出力層は中間層の答えに重みづけをして、多数決を行い、答えを出すといった仕組みになっています。
この中間層を抜いた状態のものを単純パーセプトロンと呼び、中間層があるものを多層パーセプトロンと呼びます。
通常多層パーセプトロンでは、入力層から出力層への一方向での信号伝播が行われるので、順伝播型ニューラルネットワークとも言います。
出力層での結果は、教師データにある正解ラベルと比較されて、誤差が出てきますが、この誤差を最小にするための情報を伝播してきた方向とは逆に流して学習をさせていきます。これを誤差逆伝播法といい、最終的に誤差が無くなるまで繰り返し学習を行うことで正解に近づけていきます。
ニューラルネットワークには、用途に応じていろいろなパターンが利用されています。
Convolutional Neural Network(CNN)
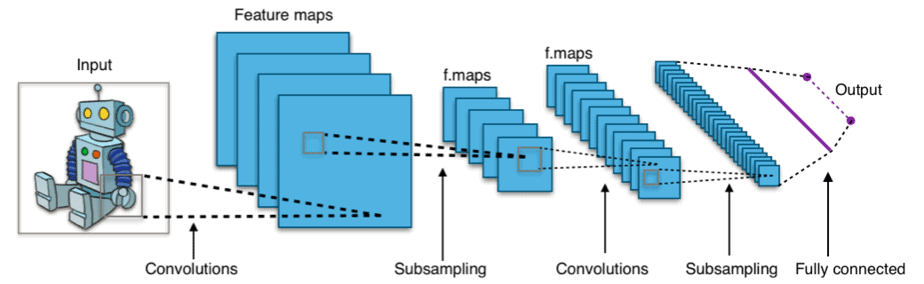
画像参照:Wikipedia
主に画像や自然言語処理に使われており、中間層は主に畳み込み(convolution)層とプーリング(サブサンプリング)層を交互に繰り返しており、ここでデータの特徴を抽出し、最後に全結合層で認識を行うという構造になっています。
機械学習による画像認識精度を競うILSVRCで、2012年に2位と圧倒的な差を付けて優勝したHinton教授率いるチームにより、CNNは大きなブレークスルーを迎え、ディープラーニングブームの火を付けました。
参考記事:Azure MLでCNN(畳み込みネットワーク)を使ってディープラーニングさせる方法
Recurrent Neural Network(RNN)
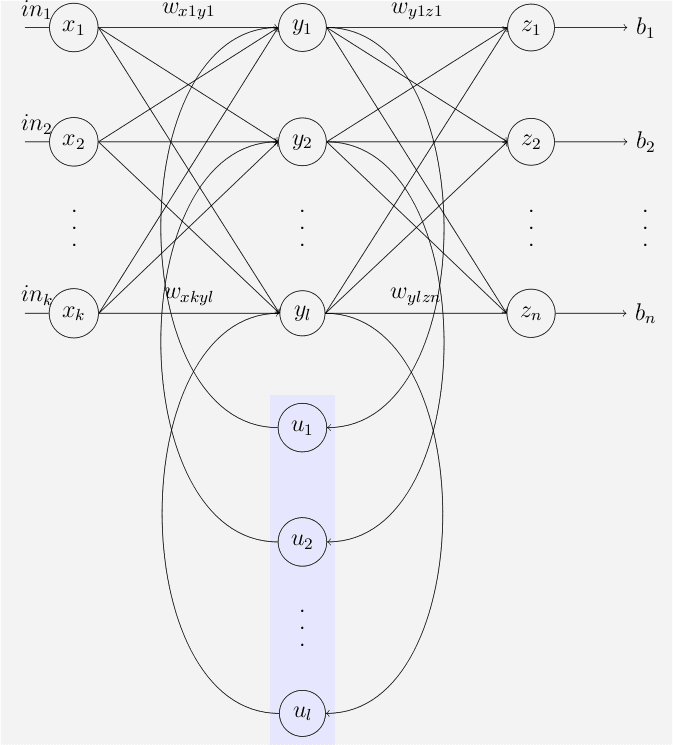
画像参照:Wikipedia
Recurrent Neural Network(RNN)は、時系列キーフレームを複数セットで解析する動画分類や、言語モデル、ロボットの行動制御などに使われています。
現在、このRNNが世界中で注目されており、ディープラーニングによる世界最先端の研究課題となっています。
このモデルの特徴は、唯一中間層への自己フィードバックができる点にあり、前時刻の層の出力を考慮して現中間層の出力を計算したり、次時刻の層の出力を考慮して現中間層へと両方向に情報をフィードバックしたりさせることができます。最近は、Long Short-Term Memory(LSTM)と呼ばれるモデルが、シンプルで学習も比較的簡単にできるために人気があります。
オートエンコーダ
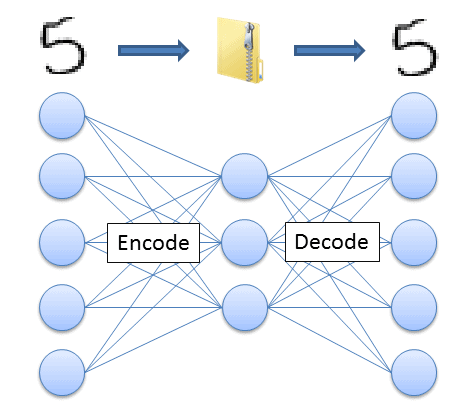
オートエンコーダは、ノイズ除去、次元削減などに有効なネットワークで、その名の通り、入力データを再現(デコード)することが可能な低次元の特徴を抽出(エンコード)できます。中間層は全結合である必要はなく、数十層重ねることが多く、中間層のエンコード部分を一層ずつ逐次的に加えて学習し、積み重ねていく手法をとります。
教師なし学習の為、入力データ自身を教師データとするところが他のネットワークとは異なる点です。
ボルツマンマシン
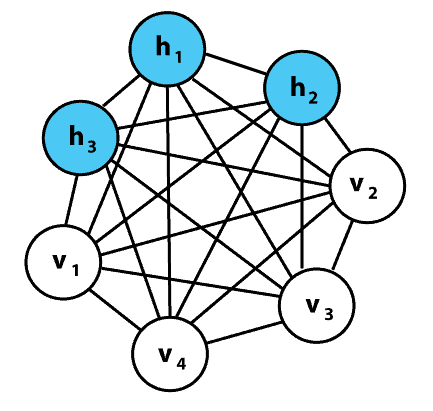
画像参照:Wikipedia
ボルツマンマシンは、主に画像や音声認識などに適用でき、ネットワーク構成は、入力層と中間層が双方向で結合する形となっています。中間層の中の層同士の関係が、確率モデルで記述されるのが特徴で、入力データをうまく再現できるようになる生成型モデルとなっています。
オートエンコーダとボルツマンマシンは、教師なし学習で特徴量を抽出させ、教師あり学習前の事前学習(pre-training)として使うこともあり、特徴抽出部分の大半のパラメータをあらかじめ最適に近い値に初期設定することができる為、効率的に学習ができるようになります。