ニューラルネットワークで「教師あり学習」をさせていて、度々発生してしまうものに「過学習(過適合)」があります。
今回は過学習はなぜ良くないのか、過学習を対処する方法はあるのかという点について解説していきます。
まず「過学習」とは?
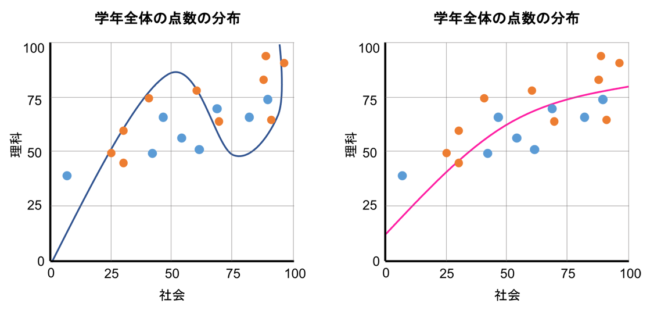
「過学習」とは過適合とも言いますが、機械学習を行う際に学習データとAIが適合しすぎて正確な結果が出ないことを言います。
学習データ上では正解率が高いのに評価データにすると正解率が低くなってしまうと言う、学習データだけに最適化されてしまって汎用性がない状態に陥ることです。
予め用意した学習データでの正解率がいくら高くても、実際の運用では役に立ちませんのでこれでは意味がありません。つまり、過学習にならずどんなデータを入れても正しい推定をしてくれるAIが理想的と言うことですね。
今回は実際にNeural Network Consoleを使って過学習の抑制に挑戦してみたいと思います!
機械学習で起きる過学習の具体例
それでは、機械学習で起きる過学習のモデルをみてみましょう。
下記のグラフは、左から「未学習」「適正」「過学習」と並んでいます。
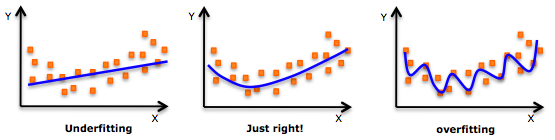
過学習のグラフはデータに対する精度が高いように見えますが、未知のデータには対応できていないことを示します。
- 未学習・・・モデルの表現力が低い
- 適正・・・真のモデルをよく表現している
- 過学習・・・過度にデータフィットしており、真のモデルと異なる
このように結果が変わってしまいます。
未学習と過学習とは
機械学習には、アルゴリズムの性能を向上させるために人の手を加えなくてはならないパラメータがあります。このパラメータをハイパーパラメータといいます。
ハイパーパラメータが不適切な場合、モデルは性能を十分に発揮できません。
性能が十分でない状態によくみられる特徴として「未学習」と「過学習」があります。
「過学習」とは、学習データに対する精度の向上を重視し過ぎた結果、未知のデータに対する精度が低下している状態です。
真のモデルを表現するためには、人の手で調整する必要があるのです。
機械学習で起きる過学習の原因
機械学習で起きる過学習の原因としては、以下の3つが考えられます。
- 学習データの数が少ない
- モデルが複雑
- データに偏りがある
1つずつ詳しくみていきましょう。
①学習データの数が少ない
過学習と聞くと、学習データが多すぎて起こるトラブルと思われがちですが、実は学習データの数が少ないことで起こります。少ないデータでモデルを作ろうとすると、記憶できているデータのみを参照するため、どうしても結果に偏りがでてしまいます。目的に応じたデータ分析を実現するためには、十分な量のデータを学習させる必要があるのです。
②モデルが複雑
さまざまなアルゴリズムを導入してモデルを構築すると、高度な解析を行えるようになる一方、過学習のリスクが増大する可能性があります。初歩的なAI開発においては、十分なデータ量を確保した上で、シンプルな手法を選ぶほうがよいでしょう。
③データに偏りがある
機械学習においては、学習データに偏りがあると正しい分析ができないため、データの量だけでなく質も重要になります。都合のいいデータだけ学習させてしまうと、正しい予測ができず、モデル構築にも悪影響を及ぼします。
過学習の対処方法・解決方法
それでは過学習を抑制するにはどうすれば良いのかを解説していきます。
- 学習データの数を増やす
- モデルを簡単なものに変更する・又はドロップアウトする
- 正則化する
この3つの対処方法や解決方法を詳しく説明していきます。
①学習データの数を増やす
こちらはまさに正攻法です。学習データの数が多ければ多いほど、学習データのバリエーションが増えていき、未知のデータに近づいていきますので、最も良い解決策と言えるでしょう。
そのため、AI開発の取り組みを始めようとする場合には、まずは、今の時点でインプットデータがどのくらい収集、準備できているのかをまず確認することになります。
そして、学習データの収集がどうしても出来ない場合には、手作りでの加工や機械的にクローンデータを水増しできないか(単純コピーではあまり意味がない)ということに取り組むことになると思います。
学習データの収集方法については下記記事でも解説しています。
②モデルを簡単なものに変更する・又はドロップアウトする
モデルを簡単なものに変えてしまうというのは、リスクもあってなかなか難しいです。
というのも、モデル(ネットワークの自由度:主に重み付けの数になると思われます)は、解決したい問題の複雑さに合わせて作られているはずなので、問題の複雑さに対して過大なネットワーク自由度を持たせて作っていると自分で認識できている場合を除いては簡単にできる解決策ではないと思います。
そうした中で、ネットワーク自由度を強制的に小さくして過学習を避ける方法としてドロップアウトがあります。多層ネットワークの各層のユニットを確率的に選別して、選別したもの以外を無効化することで「自由度の小さい仮のネットワーク」にできます。その上で学習させることでモデルを簡素化したような効果が得られるというわけです。
③正則化する
正則化というのも、ある意味、複雑なモデルを単純なモデルへ変化させていく数学的な手法と言えると思います。
数式を書いて説明していくと収拾つかなくなりますので、どういうものかイメージだけ説明すると、パラメーターの値が大きくなりすぎるのを防いで、小さい値に近づけていくことで、変数の影響を抑える数学的な手法ということになります。
つまり、不要なパラメータの影響を小さくすることで複雑なモデルを単純なモデルに変えていきながら、過学習を防ぐということかと思います。
今回は、 Neural Network Consoleを使って、最も簡単に過学習を抑制できそうなこの正則化による抑制にチャレンジしてみたいと思います。
過学習の状態を確認しよう
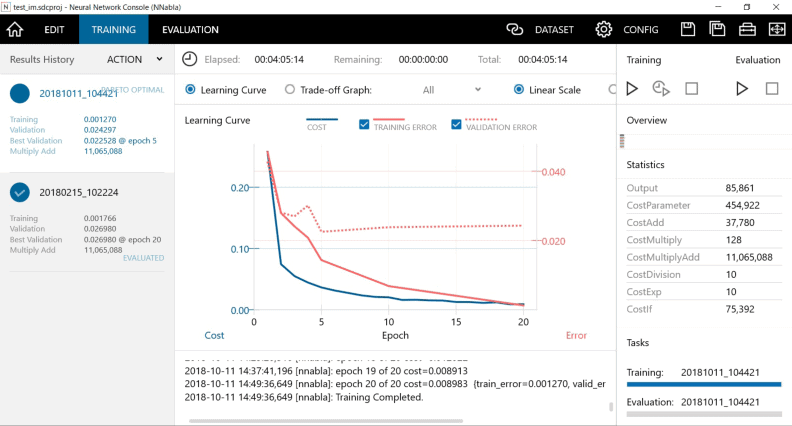
まず、Neural Network Consoleで過学習になってしまった状態を確認しておきたいと思います。
Neural Network Consoleの学習結果(下の画面)を見てください。
Traiingエラー(赤の実線)がきれいに収束しているのに、Validationエラー(赤の点線)が途中から逆に増加していってます。 ただし、赤の点線の増加傾向はそれほど大きくはないので、過学習の傾向がある状態といった感じでしょうか。
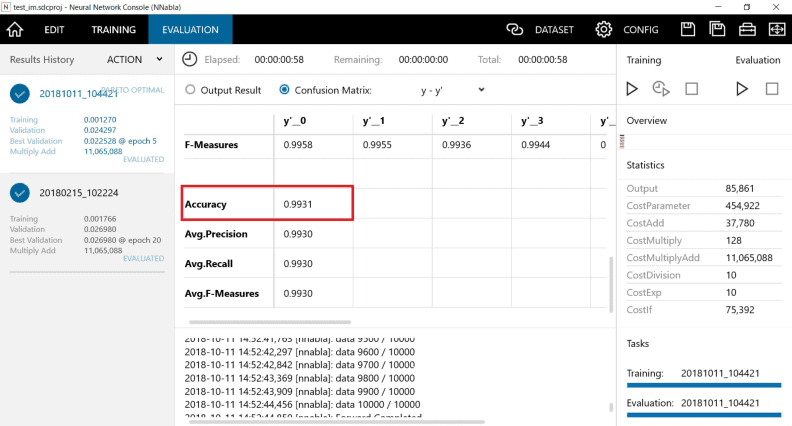
評価した結果のAccuracyも「99.31%」で、それなりの精度にはなっています。
正則化の設定をしてみる
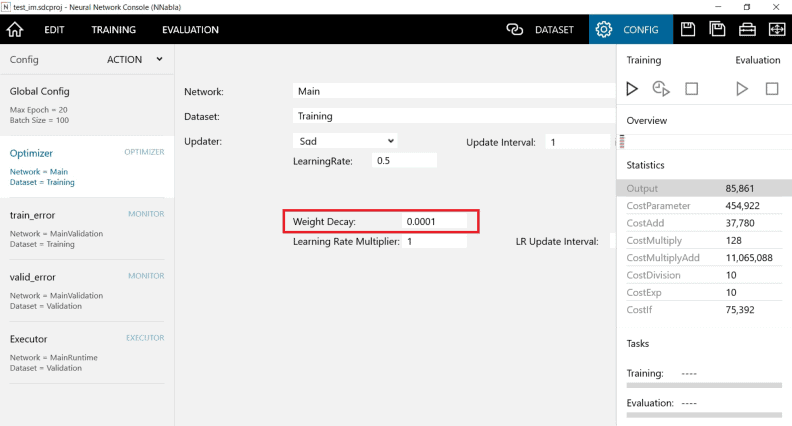
画面上部のCONFIGメニューの中の「Optiizer(オプティマイザー)」を開きます。
Weight Decay(重み減衰)の値を0以外にすると正則化が働くようになりますが、その値を何にするかは決まりがなく、値と効果の関係も不明なので、経験的感覚で決めるしかありません。
今回は、経験的に「0.0001」にしてみました。
学習曲線の変化を見る
正則化を働かせた結果、学習曲線がどう変化したかを確認します。
Neural Network Consoleの学習結果(下の画面)を見てください。
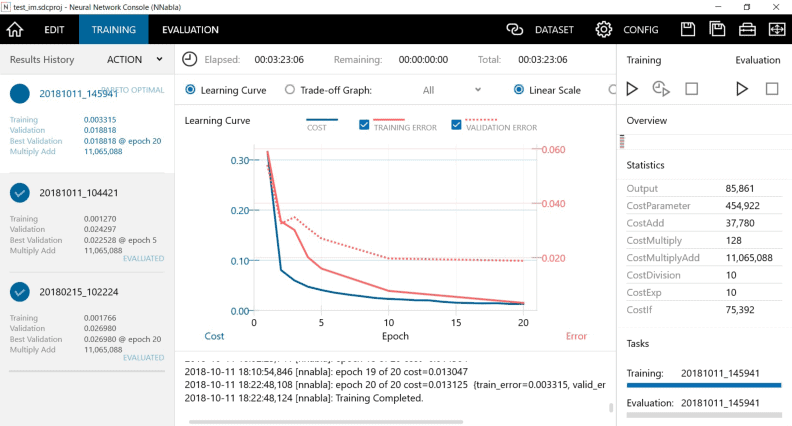
Traiingエラー(赤の実線)はきれいに収束していますが、Validationエラー(赤の点線)の方は、増加の傾向はなくなり過学習の傾向が抑制された状態には変わっていますが、まだ収束しきれていないまま終わってしまいました。
評価した結果のAccuracyは「99.45%」となり、精度は上がっています。
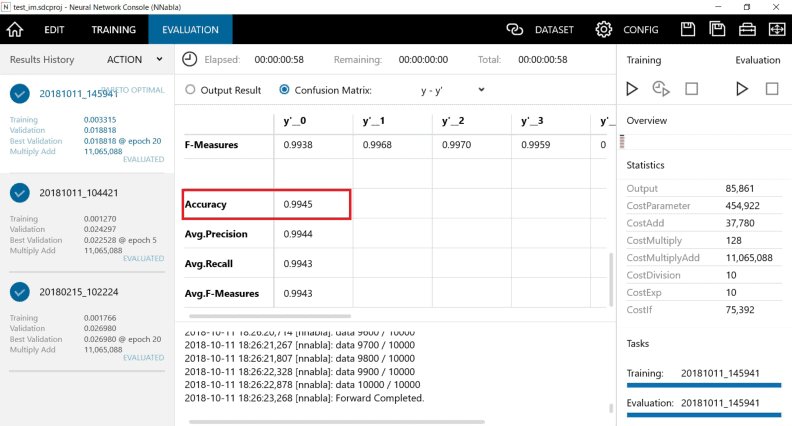
というわけで、Max Epoch数をもっと増やして収束するまで学習を続けさせてみるか、Weight Decay(重み減衰)の値を変えてみるか、もう少し試行錯誤してみる必要がありそうです。
ただ、普段使いのCPUパソコンでは学習時間がかかりすぎて今日はもう限界なので、今回はここまでにしておきたいと思います。
Neural Network Consoleのもっと詳しい使い方は下記で解説しています。
過学習についてまとめ
今回はAIで利用する「過学習」という単語について説明させて頂きました。
一見難しい言葉に思われがちですが、理解できるとすんなり活用できるものだと思います。
また、記事内で紹介させていただいたAI研究所の「ビジネス向けAI完全攻略セミナー」や「AIエンジニア育成講座」に参加すれば、過学習やPythonプログラミングの基礎から、ライブラリを使用したディープラーニングの実装など、実務に繋がる分野まで学ぶことができます。
独学で学ぶよりも遥かに効率的なのでご検討ください!
是非皆さんもこの機会にAIや人工知能、過学習について勉強してみてくださいね。